20%的杨幂+80%的泰勒长什么样?小红书风格化AI来了,可兼容SD和ControlNet
不得不说,现在拍写真真是“简单到放肆”了。
真人不用出镜,不用费心凹姿势、搞发型,只需一张本人图像,等待几秒钟,就能获得7种完全不同风格:

仔细看,造型/pose全都给你整得明明白白,并且原图直出修也不用修了。
这搁以前,不得在写真馆耗上至少整整一天,把咱和摄影师、化妆师都累个半死不活。
以上,便是一个叫做InstantIDAI的厉害之处。
除了现实写真,它还能整点“非人类的”:
比如猫头猫身,但仔细看又有你的脸部特征。

各种虚拟风格就更不用说了:

像style2,真人直接变石像。
当然,输入石像也能直接变:

对了,还能进行俩人脸融合的高能操作,看看20%的杨幂 80%的泰勒长什么样:

一张图无限高质量变身,可是叫它玩明白了。
所以,这是怎么做到的?
基于扩散模型,可与SD无缝集成
作者介绍,目前的图像风格化技术已经可以做到只需一次前向推理即可完成任务(即基于ID embedding)。
但这种技术也有问题:要么需要对众多模型参数进行广泛微调,要么与社区开发的预训练模型缺乏兼容性,要么无法保持高保真度的面部特征。
为了解决这些挑战,他们开发了InstantID。
InstantID基于扩散模型打造,其即插即用(plug-and-play)模块仅靠单张面部图像即可熟练地处理各种风格化变身,同时确实高保真度。
最值得一提的是,它可与时下流行的文本到图像预训练扩散模型无缝集成(例如SD1.5、SDXL),作为插件使用。
具体来看,InstantID由三个关键组成部分:
(1)捕获鲁棒语义人脸信息的ID embedding;
(2)具有解耦交叉注意力的轻量级适配模块,方便图像作为视觉提示;
(3)IdentityNet网络,它通过额外的空间控制对参考图像的详细特征进行编码,最终完成图像生成。
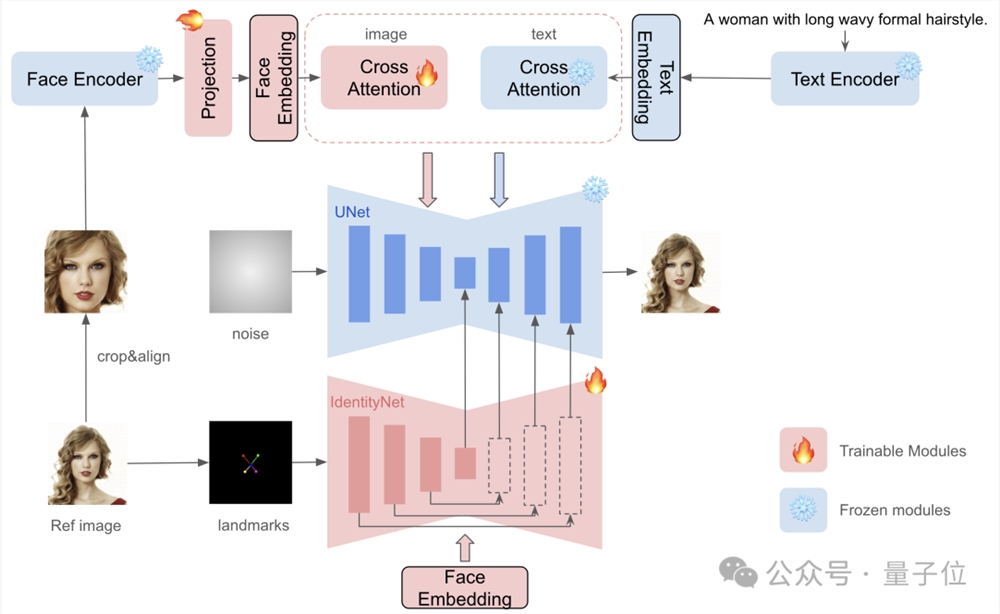
而相比业内此前的工作,InstantID有几点不同:
一是不用训练UNet,因此可以保留原始文本到图像模型的生成能力,并兼容社区中现有的预训练模型和ControlNet。
二是不需要test-time调整,因此对于特定风格,不需要收集多张图像进行微调,只需要对单个图像进行一次推断即可。
三是除了实现更好的面部保真度,也保留了文本可编辑性。如下图所示,只需几个字,即可让形象变性别、换套装、改发型以及发色。

再次强调,以上所有效果只需1张参考图像在几秒内即可完成。
如下图实验证明,多来几张参考图的作用基本不大,1张就能做得很好。

下面是一些具体对比。
比较对象是现有的免调优SOTA方法:IP-Adapter(IPA)、IP-Adapter-FaceID以及前两天腾讯刚刚出品的PhotoMaker。
可以看到,大家都挺“卷”的,效果都不赖——但仔细对比的话,PhotoMaker和IP-Adapter-FaceID保真度都不错,但文本控制能力明显差一点。

相比之下,InstantID的面孔和样式能更好地融合,在实现了更好保真度的同时,还保留了良好的文本可编辑性。
除此之外,还有与InsightFace Swapper模型的比较,你觉得哪个效果更好呢?

作者介绍
本文一共5位作者,来自神秘的InstantX团队(网上没有搜到太多信息)。
不过一作是来自小红书的Qixun Wang。
通讯作者王浩帆也是小红书的工程师,从事可控和条件内容生成(AIGC)方面的研究,是CMU’20届校友。

参考链接:
https://instantid.github.io/
HyperCore加持!小米15首发骁龙8至尊版:强得不可思议
小米公司即将于10月29日发布新机型小米15,这款手机将首次搭载高通骁龙8至尊版处理器。骁龙8至尊版处理器采用了台积电第二代3nm制程技术,并采用了双超大核方案,雷军强调,结合小米自研的HyperCore架构和内置的微架构调度器,该处理器的能效表现将非常出色。0000解决Sora物理bug!四所美国顶尖高校联合发布PhysDreamer模型
Sora视频生成器发布后不久,就被网友发现存在物理交互的bug,例如模型对物理世界的理解不足,导致小狗走路时前腿出现不自然的交错问题。为了解决这一问题,提升视频生成的真实感,来自MIT、斯坦福大学、哥伦比亚大学和康奈尔大学的研究人员联合提出了一种基于物理的方法模型——PhysDreamer。项目地址:https://top.aibase.com/tool/physdreamer站长网2024-05-06 20:34:460000有人涨粉至千万,有人悄悄落寞,B站百大UP主逐渐两极分化
在卷到飞起的美食赛道,创作者为了获取用户的关注,用各式各样的内容吸引用户的注意力,吃播、探店Vlog、美食制作教程、美食测评等内容形式层出不穷。同时为了保持自身的热度,不少创作者维持着较高的更新频率,甚至有的UP主能做到日更。站长网2023-07-24 17:15:300000低质量AI生成网站获广告支撑 数量高达217个
新闻网站评级工具NewsGuard公布了2023年6月的错误信息监控结果,称141个品牌正在为低质量的人工智能(AI)生成的网站提供广告收入,用于支持这些不可靠网站的发展。这些网站几乎没有人对其进行监督,每天平均会生成上千条文章,其中包括错误信息,尤其是误导用户的医疗健康信息。站长网2023-06-29 12:13:380000研究发现:四分之一听众无法分辨出AI深度伪造语音
概要:1.研究发现,人类只能在73%的时间内检测到深度伪造语音,无论是英语还是普通话的听众识别准确率都是一样的。2.研究人员预测,随着深度伪造技术的进步,深度伪造语音将变得更加逼真,更难以检测。3.自动检测器的改进对于减轻深度伪造内容的潜在威胁至关重要。伦敦大学学院的一项研究发现,人类在识别深度伪造语音方面的准确率仅为73%。站长网2023-08-07 10:08:460000












