AI看图猜位置,准确率超90%!斯坦福最新PIGEON模型:40%预测误差不到25公里
【新智元导读】在社交媒体上发照片要谨慎了,AI工具一眼就能识破你的位置!
随手在网络上发布的一张照片,能暴露多少信息?
外国的一位博主@rainbolt就长年接受这种「照片游戏」的挑战,网友提供照片,他来猜测照片的具体拍摄地,有些照片甚至还能猜到具体的航班细节。
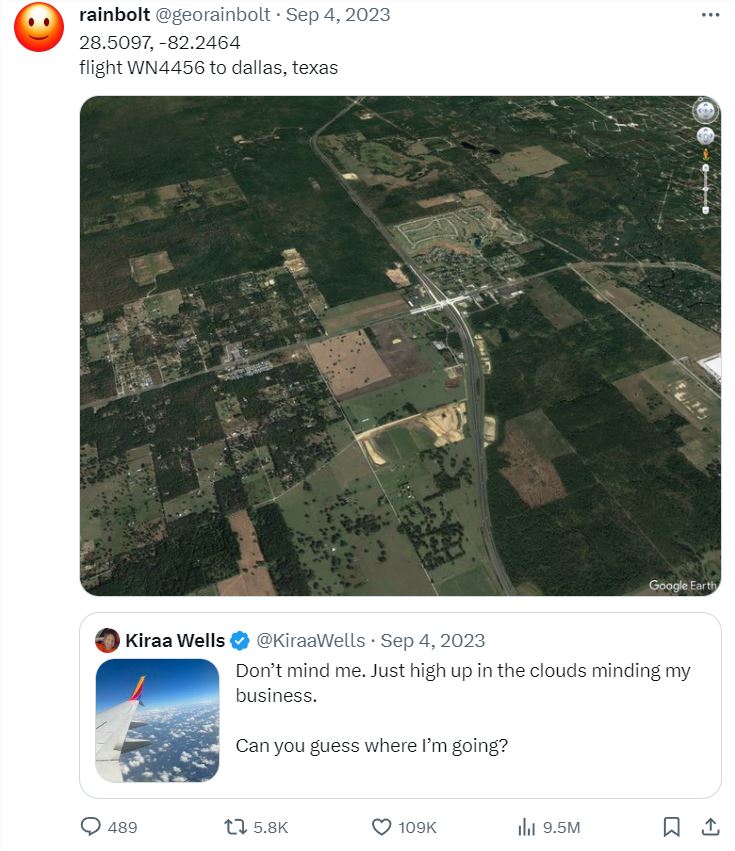
是不是细思极恐?
但「照片挑战」也同样抚慰了很多人心中的遗憾,比如拿着一张父亲年轻时候拍的照片,却不知道在哪里,借助rainbolt和广大网友的力量,最终完成了心愿。
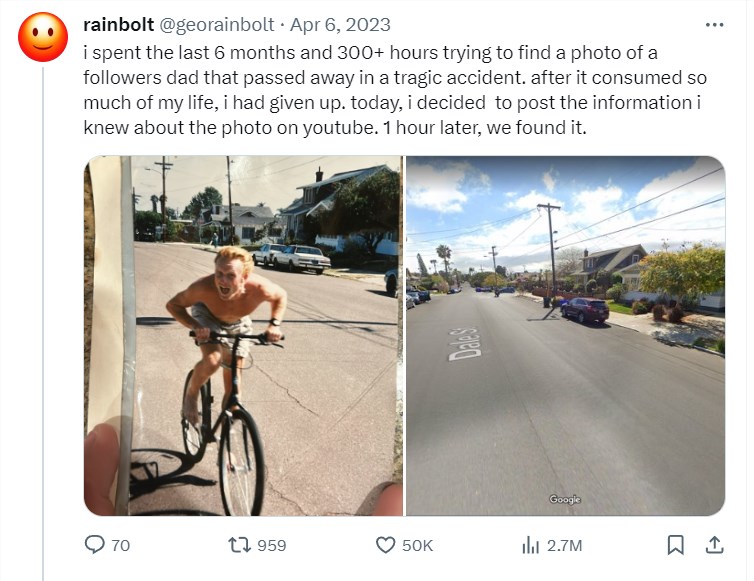
我花费了6个月和300多个小时试图找到一位粉丝父亲生前照片的位置,但没有结果,我放弃了;在发布到youtube上的一小时后,我们找到了。
光是想想,就能知道「从照片猜位置」这个过程的艰辛和难度,其中涉及到大量的地理、历史专业知识,从路标、交通方向、树木种类、基础设施等蛛丝马迹中不断找到真相。
在计算机领域,这一任务也被称为图像地理定位(image geolocalization),目前大多数方法仍然是基于手工特征和检索的方法,没有使用Transformer等深度学习架构。
最近斯坦福大学的研究团队合作开发了一款AI工具PIGEON,将语义地理单元创建(semantic geocell creation)与标签平滑(label smoothing)相结合,对街景图像进行CLIP视觉转换器的预训练,并使用ProtoNets在候选地理单元集上细化位置预测。
论文链接:https://arxiv.org/abs/2307.05845
PIGEON在「照片猜国家」的子任务上实现了91.96%的正确率,40.36%的猜测在距离目标25公里以内,这也是过去五年来第一篇没有军事背景资助的、最先进的图像地理定位相关的论文。
GeoGuessr是一个从街景图像中猜测地理位置的游戏,全球拥有5000万玩家,前面提到的rainbolt就是该游戏的忠实粉丝,也是公认的最强玩家之一。
而PIGEON模型在GeoGuessr中对人类玩家呈碾压优势,在六场比赛中连续击败rainbolt,全球排名前0.01%.
PIGEON的进步还启发了开发人员创建另一个模型PIGEOTTO,使用Flickr和维基百科的400万张图像进行训练,输入任意图像而非街景全景图,就能定位出图像的位置,功能更加强大。
在此类任务的测试中,PIGEOTTO的性能最佳,将中位偏差降低了20%-50%,在城市粒度上的预测超过了之前的SOTA高达7.7个百分点,在国家粒度上超过了38.8个百分点。
从技术上来说,该工作的最重要的结果之一就是证明了预训练的CLIP模型StreetCLIP域泛化及其对分布变化的鲁棒性,能够以零样本的方式将StreetCLIP应用于分布外基准数据集IM2GPS和IM2GPS3k,并取得了最先进的结果,击败了在400多万张分布内(in-distributions)图像上微调的模型。
并且,实验结果也证明了对比预训练是一种有效的图像地理定位元学习技术,在StreetCLIP预训练中没见过的国家预测上,准确率比CLIP提高了10个百分点以上。
由于图像地理定位数据集在地理分布方面差异很大,结果也证明了将StreetCLIP应用于任何地理定位和相关问题的有效性。
由于这项技术目前仍然可以用于不良目的,所以开发人员决定暂时不公布模型权重。
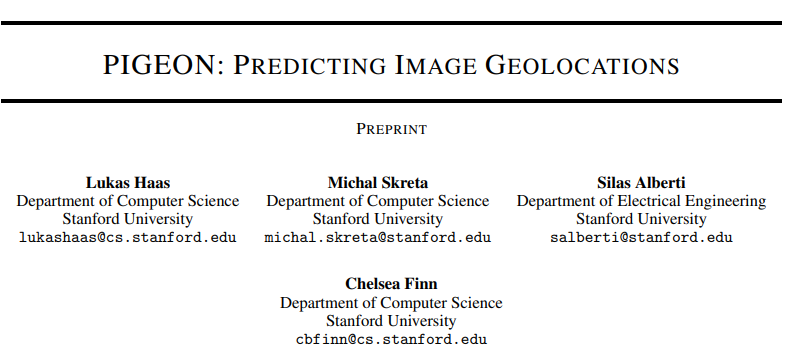
虽然大多数图像地理定位方法都依赖于公开的数据集,但目前还没有公开的、全地球范围下的街景(Street View)数据集。
所以研究人员决定在原始数据集上创建,主动联系了Geoguessr的首席技术官Erland Ranvinge,获得了该游戏中竞争对决模式下使用的100万个地点的数据集,再随机采样10%数据点,对每个数据点下载4张图片,最终获得40万张图片。
1. Geocell Creation(地理单元生成)
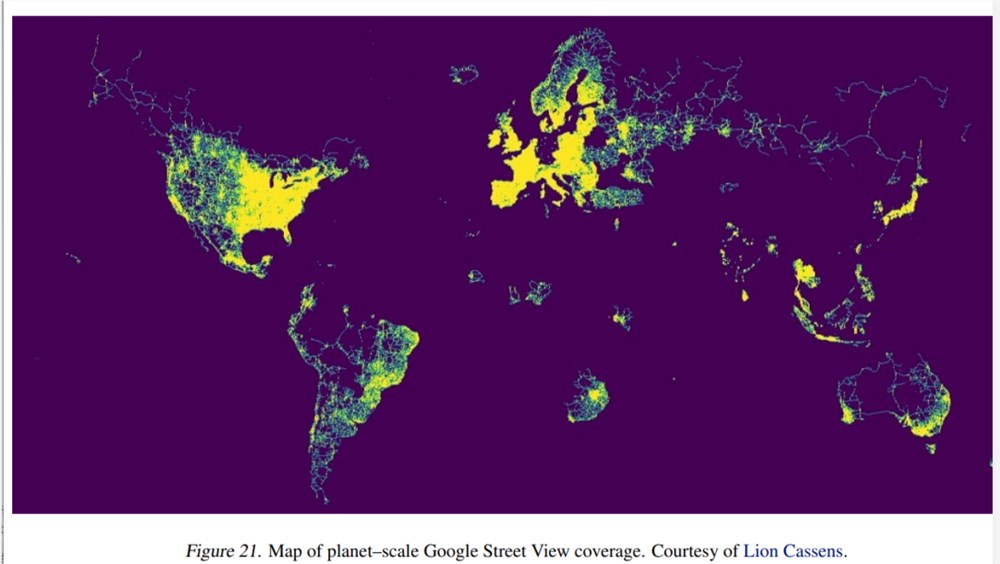
先前的研究尝试过直接对输入图像来预测经纬度,但结果证明无法取得sota性能,所以目前的方法大多依赖于生成geocells,把坐标回归问题离散化,再转成分类问题,所以geocell的设计至关重要。
这篇论文的一个创新点就是语义地理单元(semantic geocells),可以根据训练数据集样本的地理分布自动适应,因为图像中的视觉特征通常与国家(道路标记)、地区(基础设施质量)或城市(街道标志)有关;并且国家或行政边界往往遵循自然边界,如河流或山脉的流动,这反过来又影响植被类型,土壤颜色等自然特征。
研究人员设计的地理单元有三个级别:国家、admin1、admin2,从最细粒度级别(admin2)开始,算法会逐步合并相邻的admin2级别多边形,其中每个geocell包含至少30个训练样本。

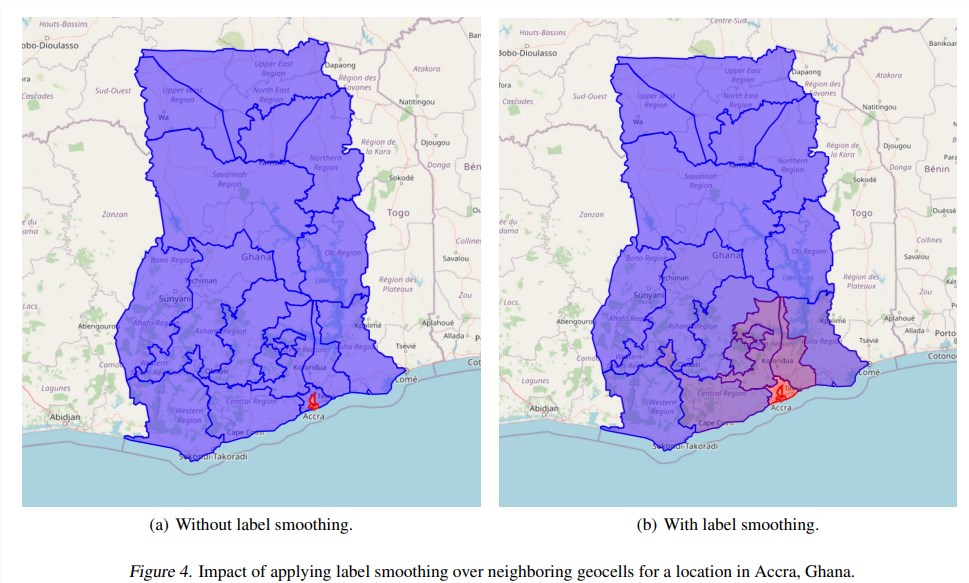
2. 标签平滑(label smoothing)
语义地理单元创建过程来离散化图像地理定位问题,可以在粒度和预测准确性之间寻求平衡:地理单元的粒度越大,预测就越精确,但由于基数(cardinality)更高,分类问题就会变得更加困难。
为了解决这个问题,研究人员设计了一个损失函数,基于预测的、到正确的地理单元之间的距离进行惩罚,可以更高效地对模型进行训练。
使用两点之间Haversine距离的一个优势是基于地球的球面几何,能够精确估计两点之间的距离。
研究人员使用预训练的视觉Transformer,架构为ViT-L/14,然后对预测header进行了微调,并且对最后一个视觉Transformer层进行解冻。
对于具有多个图像输入的模型版本,将四个图像的embedding进行平均;在实验中,平均embedding比通过多头注意力或额外的Transformer层组合embedding表现得更好。
基于先验知识和专业GeoGuessr玩家通常观察到的策略,图像定位任务有各种相关特征,例如,植被、道路标记、路标和建筑。
多模态模型对图像有更深语义理解的embedding,使其能够学习这些特征,实验中也证明了,CLIP视觉Transformer比类似的ImageNet视觉Transformer有明显的进步,并且使用注意力map能够以可解释的方式展示模型学习到的策略。
4. StreetCLIP对比预训练
受CLIP对比预训练的启发,研究人员设计了一个对比预训练任务,在学习geocell预测头之前,也可以使用它来微调CLIP基础模型。
使用地理、人口统计和地质辅助数据来增强街景数据集,使用基于规则的系统为每个图像创建随机描述,例如:
地点:南非东开普省地区的街景照片
Location: A Street View photo in the region of Eastern Cape in South Africa.
气候:该地区为温带海洋性气候。
Climate: This location has a temperate oceanic climate.
罗盘方向:这张照片是朝北的。
Compass Direction: This photo is facing north.
季节:这张照片是在12月拍摄的。
Season: This photo was taken in December.
交通:在这个位置,人们在道路的左侧行驶。
Traffic: In this location, people drive on the left side of the road.
相当于是一个隐式的多任务,可以确保模型保持丰富的数据表示,同时调整街景图像的分布并学习与地理位置相关的功能。
5. 多任务学习
研究人员还尝试通过为辅助气候变量、人口密度、海拔和一年中的月份(季节)创建特定于任务的预测header来明确多任务设置。
6. ProtoNet Refinement
为了进一步完善模型在geocell内的猜测并提高街道和城市级别的性能,研究人员使用ProtoNets执行geocell内的细化,将每个单元的单元内细化作为一个单独的few shot分类任务。
再次使用OPTICS聚类算法,其中minsample参数为3,xi参数为0.15来聚类geocell内的所有点,从而提出在cell内分类设置中学习的类别。
每个聚类由至少三个训练样本组成,形成一个原型,其表征通过对原型中所有图像的embedding进行平均来计算。
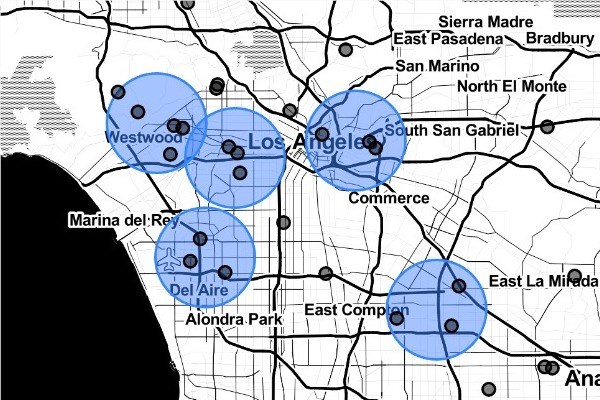
大洛杉矶都市区的可视化ProtoNet集群
为了计算原型embedding,使用与geocell预测任务相同的模型,但删除预测header并冻结所有权重。
在推理过程中,首先计算并平均新位置的嵌入,采用平均图像嵌入与给定geocell内的所有原型之间的欧几里得距离,选择具有最小欧几里得图像嵌入距离的原型位置作为最终的地理定位预测。
性能最好的PIGEON模型实现了91.96%的国家准确率(基于政治边界),40.36%的猜测都在距离正确位置25公里以内,中位公里误差为44.35公里,GeoGuessr平均得分为4525分。
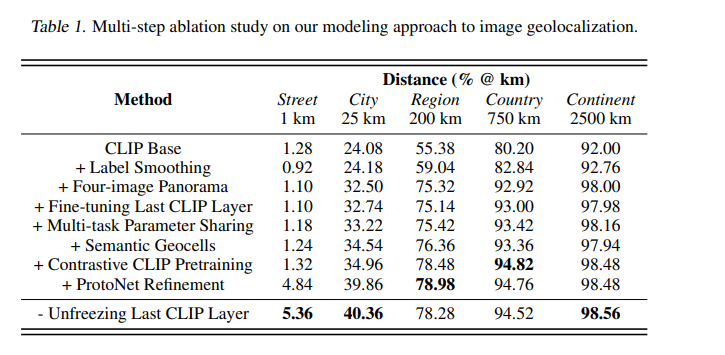
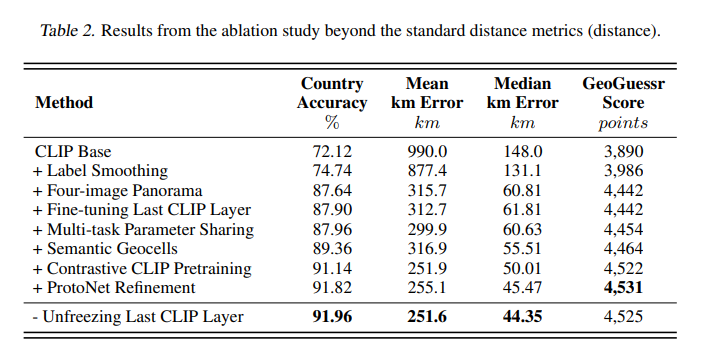
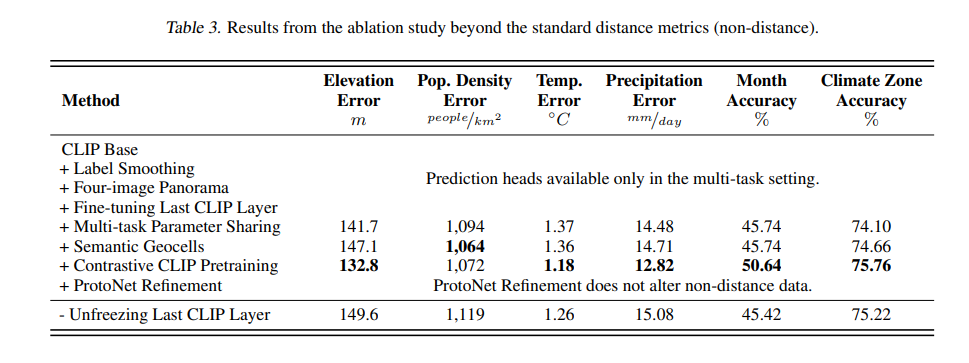
在增强数据集上的多任务模型的结果显示,模型可以从街景图像中推断出地理、人口和地质特征。
参考资料:
https://the-decoder.com/this-ai-knows-where-you-took-which-photo
https://www.researchgate.net/publication/372313510_PIGEON_Predicting_Image_Geolocations
中消协点名共享充电宝好借难还:企业应提高消费纠纷解决效率
今日,中消协发布了2023年上半年消费维权舆情热点,2023年上半年,有关线下演出“退票难”、酒店民宿毁约侵权纠纷、知名餐饮品牌食品安全问题隐患、视频平台会员服务体验不佳、研学游侵权“陷阱”、家乐福商超购物卡限制消费、航空里程积分清零、共享充电宝“好借难还”、网红竹筒奶茶被曝食品安全问题、低价旅游团强制购物问题等多个案例涉及的消费维权问题较为突出。站长网2023-08-04 11:27:090000AI 四小龙今何在系列之——旷视,成败皆靠大金主?
如今提到“AI六小龙”,智谱、月之暗面、阶跃星辰、百川智能等名字自是耳熟能详。但这距离过往“AI四小龙”的提法,仅仅过去了三年时间不到。站在生成式AI的洪流中央回望,曾经的旷视、依图、商汤、云从等“四小龙”,却被排除在了曾经的聚光灯外。如果按AI行业十年起步的行业周期来看,这并不是一个正常的情况。00003个月涨粉670万,8旬老人站上抖音C位
在抖音,“姥姥”不是一类身份,而是一个赛道。今年9月,继“桃罐头”视频一炮而红后,@八零徐姥姥被流量选中,坐上涨粉快车,成为下半年出圈的又一位“姥姥”。金句频出的姥姥、温情的家庭日常,加上乡村美食的诱惑,@八零徐姥姥的走红似乎是必然,最近30天内,其账号涨粉势头不减,已跃升至700万达人行列。观察其粉丝画像,其中31-40岁、24-30岁人群居多,其中71%都是女性。@八零徐姥姥作品站长网2023-12-05 17:04:370000澳大利亚AI芯片制造商BrainChip获美国专利授权 股价上涨 11%
BrainChipHoldingsLtd(BRN.AX)是一家澳大利亚的人工智能芯片制造商,该公司最近在美国获得了一项有关其神经形态处理器的专利授权。此消息使得BrainChip的股价上涨了近11%,创下了六周来的最佳表现。站长网2023-07-19 19:18:330000东方甄选与淘宝背后的“权力游戏”
8月29日,东方甄选终于在淘宝开启直播卖货,一些股东对此期盼已久;傍晚18点左右,销售额已突破1亿元。促成东方甄选选择进入淘宝生态的原因有很多,与抖音的摩擦、行业的变化、淘宝的接纳……但从东方甄选CEO孙东旭在2023财年年报的业绩交流会上的表述看,东方甄选是在产品力、组织力、内容力、供应链都达到一定水准后,做出的选择。站长网2023-08-30 09:18:590000