LLM AutoEval:AI平台自动评估Google Colab中的LLM
划重点:
1. 🔄 自动化设置和执行:LLM AutoEval通过使用RunPod简化设置和执行过程,提供便捷的Colab笔记本,实现无缝部署。
2. 🎚 可定制的评估参数:开发者可以通过选择两个基准套件(nous或openllm)来微调评估,提高LLMs性能。
3. 📊 摘要生成和GitHub Gist上传:LLM AutoEval生成评估结果摘要,快速展示模型性能,并方便地上传至GitHub Gist进行分享和参考。
在自然语言处理领域,语言模型的评估对于开发人员推动语言理解和生成的边界至关重要。LLM AutoEval是一款旨在简化和加速语言模型(LLMs)评估过程的工具,专为寻求快速高效评估LLM性能的开发者定制。
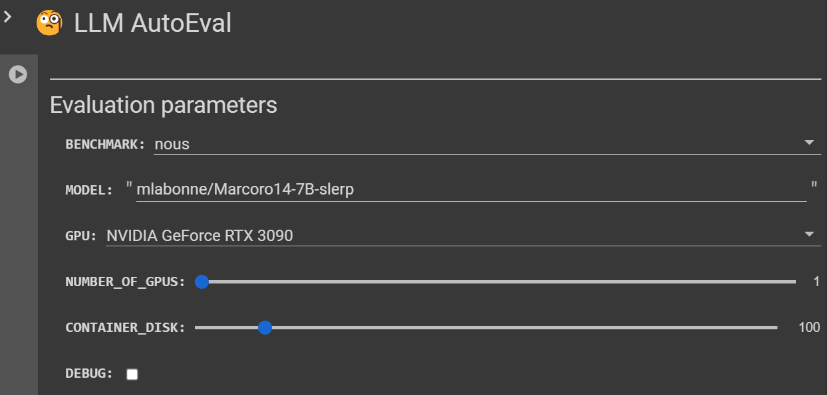
LLM AutoEval具有以下关键特点:
1. **自动化设置和执行:** LLM AutoEval通过使用RunPod简化设置和执行过程,提供方便的Colab笔记本,实现无缝部署。
2. **可定制的评估参数:** 开发者可以通过选择两个基准套件 - nous或openllm,微调他们的评估。这提供了对LLM性能的灵活评估。
3. **摘要生成和GitHub Gist上传:** LLM AutoEval生成评估结果的摘要,快速展示模型的性能。该摘要随后方便地上传至GitHub Gist,以便轻松分享和参考。
LLM AutoEval提供了用户友好的界面,可定制的评估参数,满足开发者在评估语言模型性能时的多样化需求。两个基准套件,nous和openllm,提供了不同的任务列表进行评估。nous套件包括诸如AGIEval、GPT4ALL、TruthfulQA和Bigbench等任务,推荐用于全面评估。
另一方面,openllm套件包含任务,如ARC、HellaSwag、MMLU、Winogrande、GSM8K和TruthfulQA,利用vllm实现增强速度。开发者可以从Hugging Face中选择特定的模型ID,选择首选GPU,指定GPU数量,设置容器磁盘大小,选择在RunPod上使用社区或安全云,并切换对于像Phi这样的模型的信任远程代码标志。此外,开发者还可以激活调试模式,尽管不建议在评估后保持Pod处于活动状态。
为了在LLM AutoEval中实现无缝的令牌集成,用户必须使用Colab的Secrets选项卡,在那里创建两个名为runpod和github的秘密,分别包含RunPod和GitHub所需的令牌。
两个基准套件,nous和openllm,满足不同的评估需求:
1. Nous套件:*开发者可以将其LLM结果与OpenHermes-2.5-Mistral-7B、Nous-Hermes-2-SOLAR-10.7B或Nous-Hermes-2-Yi-34B等模型进行比较。Teknium的LLM-Benchmark-Logs可作为评估比较的有价值参考。
2. Open LLM套件:该套件允许开发者将其模型与列在Open LLM排行榜上的模型进行基准测试,促进社区内更广泛的比较。
在LLM AutoEval中进行故障排除得到了对常见问题的明确指导。例如,“Error: File does not exist”情景提示用户激活调试模式并重新运行评估,便于检查日志以识别和纠正与缺少的JSON文件相关的问题。在“700Killed”错误的情况下,警告用户硬件可能不足,特别是在尝试在像RTX3070这样的GPU上运行Open LLM基准套件时。最后,对于过时的CUDA驱动程序的不幸情况,建议用户启动新的pod以确保LLM AutoEval工具的兼容性和平稳运行。
LM AutoEval是一款为开发者在复杂的LLM评估领域中航行提供帮助的有前途的工具。作为一个为个人使用而设计的不断发展的项目,鼓励开发者谨慎使用,并为其发展做出贡献,确保在自然语言处理社区中持续增长和实用性。
项目网址:https://github.com/mlabonne/llm-autoeval?tab=readme-ov-file
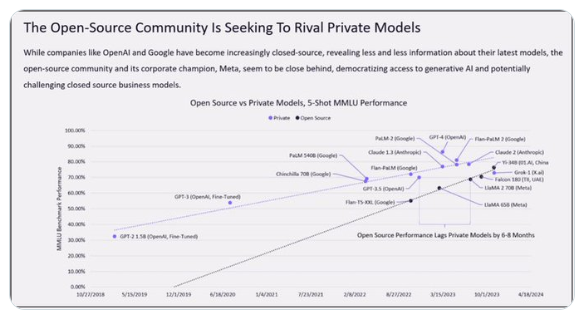
2024年最重要AI图引热议 开源AI模型正在超越专有模型!
要点:2024年最重要AI图表显示,开源本地模型正在超越大规模、基于云的昂贵封闭模型,受到LeCun等专业人士的认可。在5-ShotMMLU基准测试中,代表开源模型和闭源模型性能的两条线将在两年内相交,显示开源社区推动更易于访问的生成式AI,挑战传统闭源AI开发模式。Meta和IBM牵头成立AI联盟,旨在支持开放创新和开放科学,有50多家科技公司、高校和机构加入,显示全球支持开源的势头。站长网2023-12-20 14:55:23000030天涨粉100万,AI猫猫“卖惨”成新晋流量密码
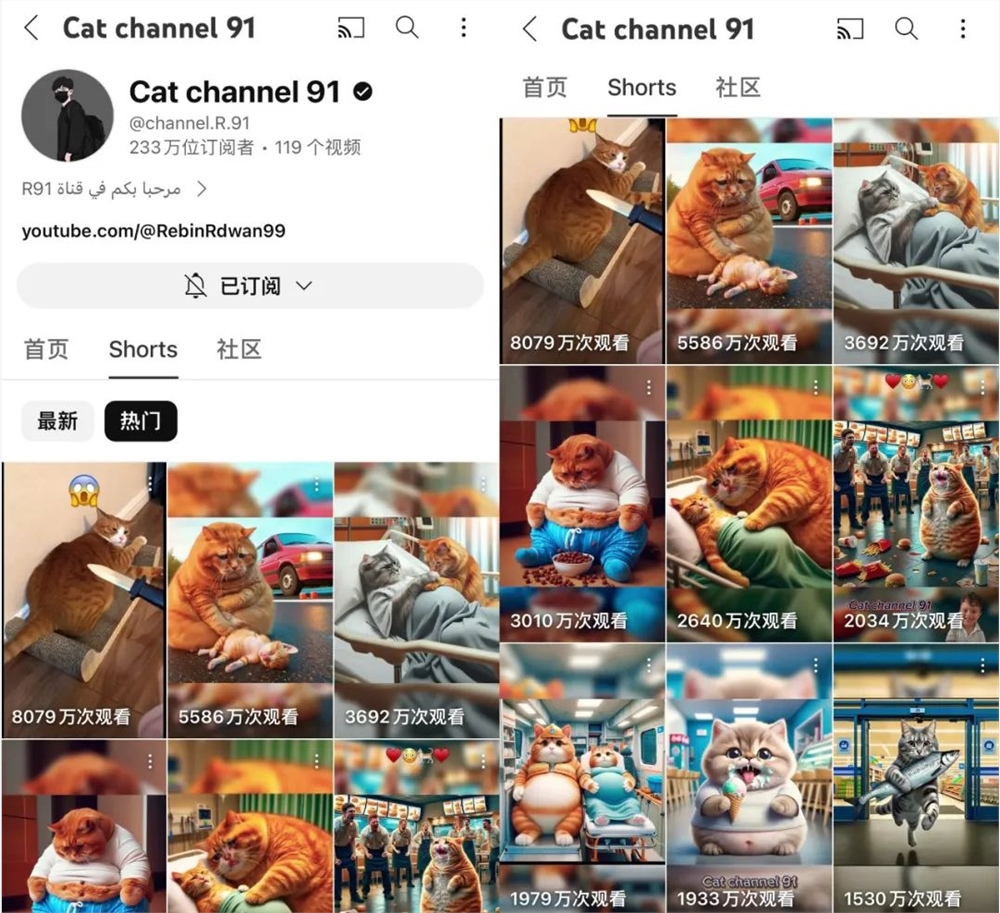
AI猫猫剧情号,火了。当魔性洗脑的“喵喵”音乐响起,一张张以猫猫为故事主角的画面,会像设定了自动播放的PPT一样呈现在你的眼前。这样的一条视频,目前在YouTubeShorts(以下简称油管)上获得了超5000万次观看和300多万点赞。站长网2024-03-15 17:48:300002南洋理工发布提高AI视频生成内容一致性方法FreeInit
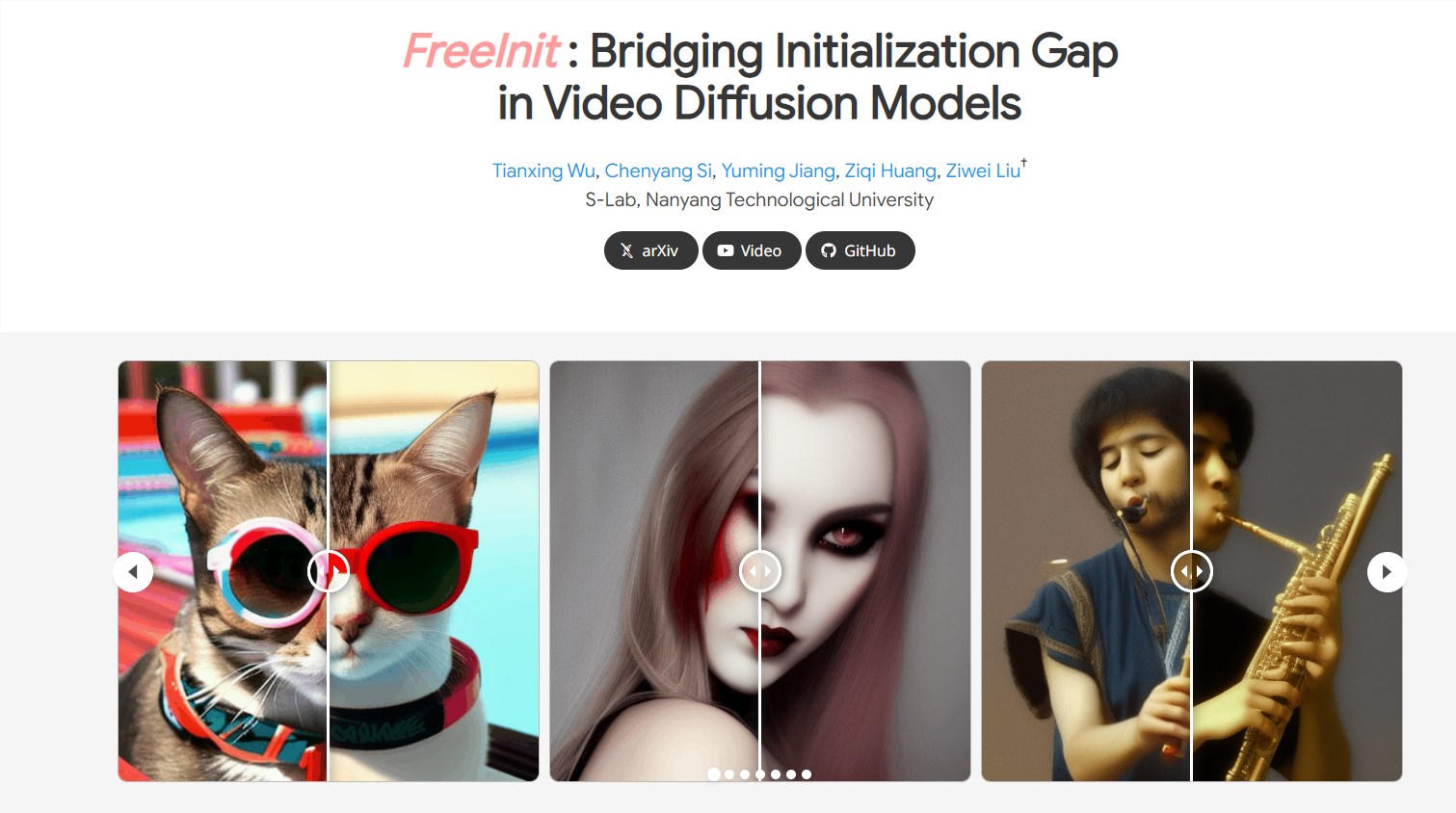
要点:FreeInit方法提升视频扩散模型生成的时空一致性。通过发现噪声初始化在视频扩散模型中存在的隐含训练-推理差距,提出了FreeInit,无需额外训练,不引入可学习参数。FreeInit通过迭代优化推理初始噪声的时空低频组件,弥补训练和推理之间的初始化差距,显著提高生成结果的时空一致性。站长网2023-12-14 10:09:220000研究称:澳大利亚在AI监管中处于落后地位
🔍划重点:-澳大利亚在AI领域的资金和监管方面被认为滞后,尤其在美国发布AI监管行政命令后,专家发出了警告。-澳大利亚政府虽然签署了布莱切利宣言,但尚未宣布对AI安全调查的回应,导致专家担心澳大利亚可能被抛在国际竞争之后。-尽管已收到超过500份关于AI的建议意见,但政府在资金支持和监管细节上的不足表明澳大利亚需要采取更积极的措施来保障AI的安全发展。站长网2023-11-07 14:29:100004暴雪魔兽世界国服正式服今日开服
今天,《魔兽世界》的国服正式重新开放,根据暴雪的计划,原定开服时间是中午12:00,但玩家的实际体验显示,服务器开放时间比预期提前了,玩家们现在已经可以登录并进入游戏。玩家在首次登录游戏时,会触发全新的战团系统转换流程,这个过程可能会持续20分钟以上。此外,由于数据量处理的需要,玩家在登录时可能会遇到排队等待的情况。站长网2024-08-01 09:58:090000