即插即用,完美兼容:SD社区的图生视频插件I2V-Adapter来了
图像到视频生成(I2V)任务旨在将静态图像转化为动态视频,这是计算机视觉领域的一大挑战。其难点在于从单张图像中提取并生成时间维度的动态信息,同时确保图像内容的真实性和视觉上的连贯性。大多数现有的 I2V 方法依赖于复杂的模型架构和大量的训练数据来实现这一目标。
近期,由快手主导的一项新研究成果《I2V-Adapter: A General Image-to-Video Adapter for Video Diffusion Models》发布,该研究引入了一个创新的图像到视频转换方法,提出了一种轻量级适配器模块,即 I2V-Adapter,它能够在不需要改变现有文本到视频生成(T2V)模型原始结构和预训练参数的情况下,将静态图像转换成动态视频。

论文地址:https://arxiv.org/pdf/2312.16693.pdf
项目主页:https://i2v-adapter.github.io/index.html
代码地址:https://github.com/I2V-Adapter/I2V-Adapter-repo
相比于现有方法,I2V-Adapter 大幅减少了可训练参数(最低可达22M,为主流方案例如 Stable Video Diffusion [1] 的1%),同时具备与 Stable Diffusion [2] 社区开发的定制化 T2I 模型(DreamBooth [3]、Lora [4])与控制工具(ControlNet [5])的兼容性。通过实验,研究者证明了 I2V-Adapter 在生成高质量视频内容方面的有效性,为 I2V 领域的创意应用开辟了新的可能性。

方法介绍
Temporal modeling with Stable Diffusion
相较于图像生成,视频生成的独特挑战在于建模视频帧间的时序连贯性。现有大多数方案都基于预训练的 T2I 模型(例如 Stable Diffusion 和 SDXL [6])加入时序模块对视频中的时序信息进行建模。受到 AnimateDiff [7] 的启发,这是一个最初为定制化 T2V 任务而设计的模型,它通过引入与 T2I 模型解耦的时序模块建模了时序信息并且保留了原始 T2I 模型的能力,能够结合定制化 T2I 模型生成流畅的视频。于是,研究者相信预训练时序模块可以看作是通用时序表征并能够应用于其他视频生成场景,例如 I2V 生成,且无需任何微调。因此,研究者直接利用预训练 AnimateDiff 的时序模块并保持其参数固定。
Adapter for attention layers
I2V 任务的另一难点在于保持输入图像的 ID 信息,现有方案大多使用一个预训练的图像编码器对输入图像进行编码,并将此编码后的特征通过 cross attention 注入至模型中引导去噪的过程;或在输入端将图像与 noised input 在 channel 维度拼接后一并输入给后续的网络。前者由于图像编码器难以捕获底层信息会导致生成视频的 ID 变化,而后者往往需要改变 T2I 模型的结构与参数,训练代价大且兼容性较差。
为了解决上述问题,研究者提出了 I2V-Adapter。具体来说,研究者将输入图像与 noised input 并行输入给网络,在模型的 spatial block 中,所有帧都会额外查询一次首帧信息,即 key,value 特征都来自于不加噪的首帧,输出结果与原始模型的 self attention 相加。此模块中的输出映射矩阵使用零初始化并且只训练输出映射矩阵与 query 映射矩阵。为了进一步加强模型对输入图像语义信息的理解,研究者引入了预训练的 content adapter(本文使用的是 IP-Adapter [8])注入图像的语义特征。
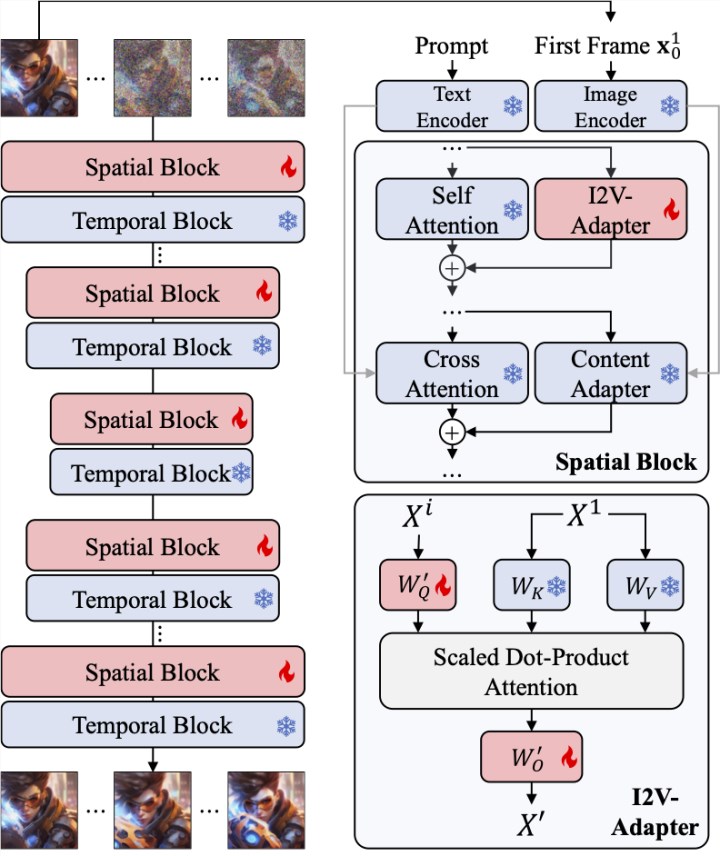
Frame Similarity Prior
为了进一步增强生成结果的稳定性,研究者提出了帧间相似性先验,用于在生成视频的稳定性和运动强度之间取得平衡。其关键假设是,在相对较低的高斯噪声水平上,带噪声的第一帧和带噪声的后续帧足够接近,如下图所示:

于是,研究者假设所有帧结构相似,并在加入一定量的高斯噪声后变得难以区分,因此可以把加噪后的输入图像作为后续帧的先验输入。为了排除高频信息的误导,研究者还使用了高斯模糊算子和随机掩码混合。具体来说,运算由下式给出:

实验结果
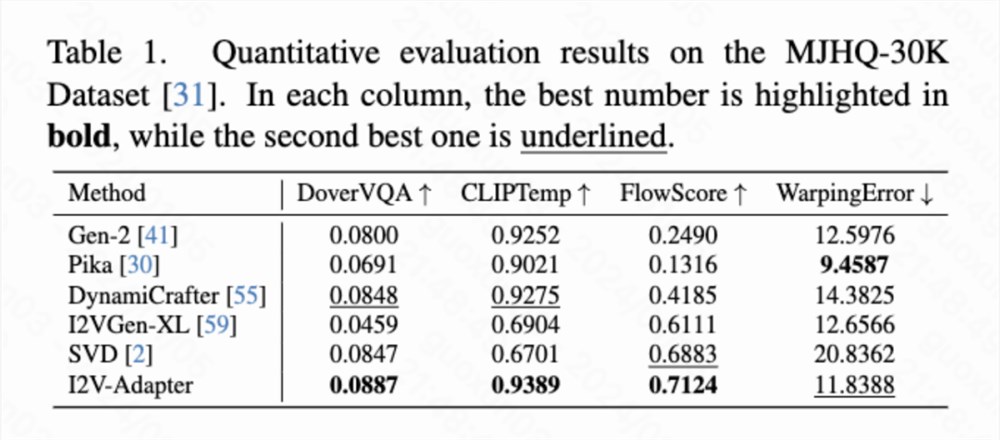
定量结果
本文计算了四种定量指标分别是 DoverVQA (美学评分)、CLIPTemp (首帧一致性)、FlowScore (运动幅度) 以及 WarppingError (运动误差) 用于评价生成视频的质量。表1显示 I2V-Adapter 得到了最高的美学评分,在首帧一致性上也超过了所有对比方案。此外,I2V-Adapter 生成的视频有着最大的运动幅度,并且相对较低的运动误差,表明此模型的能够生成更加动态的视频并且同时保持时序运动的准确性。
定性结果
Image Animation(左为输入,右为输出):




w/ Personalized T2Is(左为输入,右为输出):




w/ ControlNet(左为输入,右为输出):

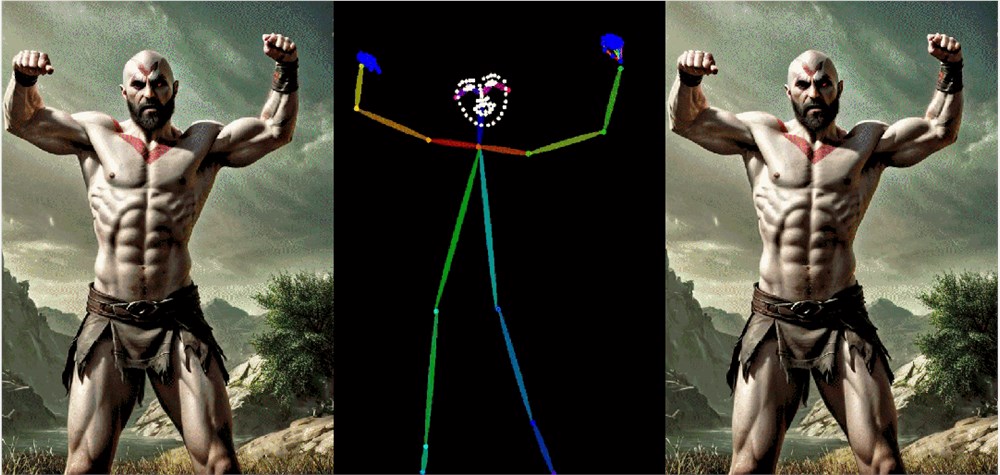

总结
本文提出了 I2V-Adapter,一种即插即用的轻量级模块,用于图像到视频生成任务。该方法保留原始 T2V 模型的 spatial block 与 motion block 结构与参数固定,并行输入不加噪的第一帧与加噪的后续帧,通过注意力机制允许所有帧与无噪声的第一帧交互,从而产生时序连贯且与首帧一致的视频。研究者们通过定量与定性实验证明了该方法在 I2V 任务上的有效性。此外,其解耦设计使得该方案能够直接结合 DreamBooth、Lora 与 ControlNet 等模块,证明了该方案的兼容性,也促进了定制化与可控图像到视频生成的研究。
让“郭德纲”说英语相声 HeyGen的视频生意不好做
听郭德纲的新相声了吗?飙英语的那种。最近,一段“郭德纲用英语说相声”的视频在社交平台传疯了。视频中,老郭用自己声音说的英语不仅发音准确,嘴型自然,语法错误都少。实际上,这段视频又是AI技术参与的二创作品,这个“没有翻译腔的真正翻译”作品被网友怒赞,不少人觉得,即使是真人配音也无法达到这样传神的效果。站长网2023-11-09 14:16:000000快来领取!华为给升级HarmonyOS NEXT Beta 版的用户送了一份见面礼
大家期待已久的纯血鸿蒙”终于来了!前段时间,HarmonyOSNEXT面向开发者和先锋用户启动Beta,受到了众多用户的支持。不少花粉纷纷第一时间报名升级,抢先感受纯血鸿蒙”带来的全新体验。站长网2024-08-17 09:51:360000受益于AI热潮,芯片制造设备供应商 Lam Research 收入超预期
芯片制造设备供应商LamResearch(LRCX.O)预测季度收入高于华尔街预期,因为半导体制造商争先恐后地满足人工智能(AI)技术日益普及所推动的需求激增。在ChatGPT引起消费者和投资者的关注后,各行业的企业都在竞相整合人工智能功能,使像Lam这样对芯片供应链至关重要的公司受益。站长网2023-07-27 17:40:500000蜜雪冰城进军炸串:便宜得不像话
摆小吃摊之后,蜜雪冰城最近又悄然进军了炸串业务,依旧高质低价”,引发网友热议。在蜜雪冰城小程序可以看到,郑州、北京的部分蜜雪冰城店铺已经开设了炸货业务,鸡肉小串售价10元30串、一份鸡排售价9.9元、一份黄金鸡柳售价8元对比隔壁正新鸡排的13元一份鸡排、喜姐炸串10元20串鸡肉小串,确实很有杀伤力,网友也赞叹果然没有白白在正新鸡排旁呆这么多年”。站长网2023-08-29 10:41:490000抖音货架到底值不值得做?服务商:我们准备放弃了......
为了货架电商,抖音投入百亿扶持,将其当做最重要的运营方向。但某入局了货架电商的服务商,却说“要放弃了”。近期,某抖音服务商跟新播场分享了他们做抖音货架电商的经历。他表示,综合来看,无论是现在被鼓吹的商品卡,还是行业讨论了很久的商城,对于他们而言很难有增长效果。实际上,如今行业内不看好抖音货架电商的还大有人在,问题大多围绕在价格内卷、会让兴趣电商失去竞争力等。站长网2023-07-06 22:09:460002