上海AI实验室等开源,音频、音乐统一开发工具包Amphion
上海AI实验室、香港中文大学数据科学院、深圳大数据研究院联合开源了一个名为Amphion的音频、音乐和语音生成工具包。
Amphion可帮助开发人员研究文本生成音频、音乐等与音频相关的领域,可以在一个框架内完成,以解决生成模型黑箱、代码库分散、缺少评估指标等难题。
Amphion包含了数据处理、通用模块、优化算法等基础设施。同时针对文本到语音、歌声转换、文本到音频生成等任务,提供了特定的框架、模型和开发说明,还内置了各类神经语音编解码器和评价指标。
尤其是对于那些刚接触生成式AI开发的新手来说,Amphion非常容易上手。
开源地址:https://github.com/open-mmlab/Amphion
论文地址:https://arxiv.org/abs/2312.09911
以下是Amphion包含的各种模型
文本到语音合成
Amphion内置的文本到语音合成模型,涵盖从传统到当前最先进的技术。例如,FastSpeech2使用前馈式Transformer架构实现快速语音合成;
VITS
2利用潜在扩散模型合成高质量语音。融合了条件变分自编码器,可实现端到端的语音合成;Vall-E使用神经编解码器语言模型一键实现零资源的语音合成;NaturalSpeech
开发者可根据业务需求,选择使用不同的模型进行语音合成。
歌声转换
Amphion提供了提取说话人无关表示的各类基于内容的特征,例如,来自WeNet、Whisper和ContentVec的预训练语音特征。
同时实现了多种声学解码器架构,比如基于扩散模型、变压器和变分自编码器的方法。
此外,借助内置的神经语音编解码器合成声波输出,开发者可以灵活配置不同模块,进行不同歌声风格转换。
文本到音频生成
Amphion使用了主流的潜在扩散生成模型。该模型包含一个将频谱映射到潜空间的变分自动编码器,一个接受文本并输出条件的T5编码器,以及一个扩散网络生成最终音频。
用户只需给出音频描述文本,就可以生成语义一致的背景音效。
神经语音编解码器
Amphion提供了丰富的编解码器算法选项,涵盖主流的自动回归模型、流模型、对抗生成模型、扩散模型等。
例如,WaveNet使用膨胀卷积实现高质量语音合成;HiFi-GAN应用多尺度判别器实现高保真的语音重构等,可满足不同业务场景的需求。
性能评估模块
为了帮助开发者全面评估生成语音的质量和性能,Amphion提供了丰富的评估模块。
评估基频建模、能量建模、频谱失真、可懂度等语音维度,可帮助开发者简单直观地比较不同模型的性能。
开发团队表示,未来,会持续更新这个工具包,加入更多与语音相关的模型,打造成最好用的开源语音工具包之一。
本文素材来源Amphion论文,如有侵权请联系删除
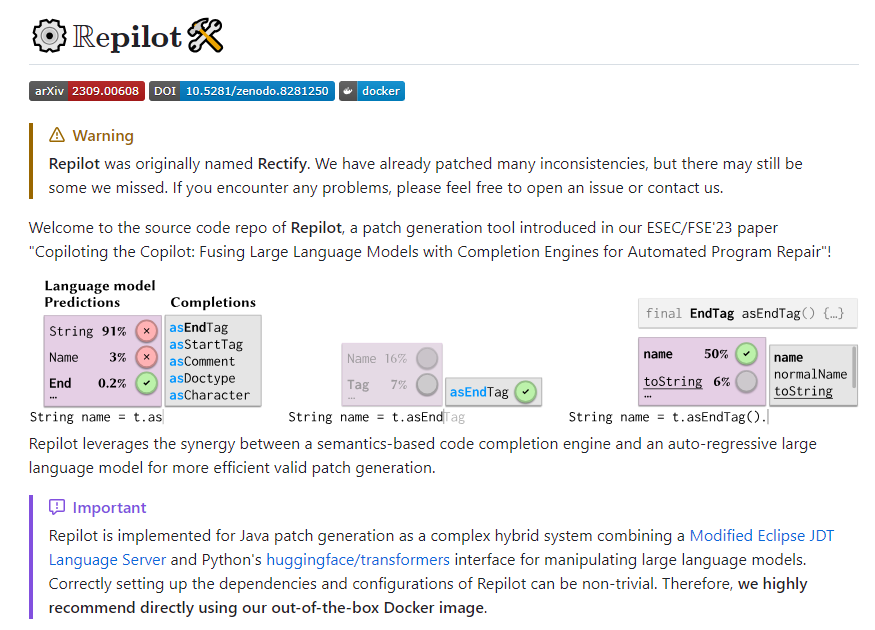
Repilot开源:自动程序修复的高效补丁生成工具
Repilot是一款旨在提高程序修复效率的工具,它结合了语义导向的代码补全引擎和大型语言模型,能够自动生成有效的程序补丁。Repilot的核心功能包括错误修复、智能代码补全、与大型语言模型的集成、Docker支持以及详细的文档支持。如果您是开发人员或软件维护者,Repilot可能会成为您提高工作效率的得力助手。站长网2023-09-19 11:35:320000OpenAI宫斗没有赢家
发生在全球最顶级的人工智能公司OpenAI的一场宫斗闹剧,演变为一场“集体自杀”,最后似乎又复活了,CEO阿尔特曼回归,只是董事会发生了改组。然而引发这场闹剧背后的根源,人工智能研究的公益性与商业性冲突,仍然存在。这场闹剧,没有谁是赢家。OpenAI风雨飘摇,大伤元气;微软也暴露了自己作为重要股东,对OpenAI毫无约束力的bug;挑起战争的几个人更是被踢出了董事会。站长网2023-11-24 14:11:550000AI改变澳大利亚求职方式,AI招聘工具越来越普及
划重点1.人工智能在澳大利亚的招聘领域日益普及,被用于筛选简历和初步面试,对求职者产生了深远影响。2.尽管AI在提高招聘效率方面有好处,但也引发了公平和歧视问题,研究表明AI筛选应聘者会强化对妇女和文化少数群体的偏见。3.求职者面临着缺乏透明度的问题,他们不清楚招聘过程如何评审他们,而澳大利亚法律也没有明确规定必须通知求职者AI筛选的细节。站长网2023-10-24 17:28:160001华为7月服务日开启:手机免费贴膜 99元换原装电池
华为推出了7月服务日活动,为消费者提供了六大专属权益。这一活动将在每个月的第一个周五、周六和周日连续三天进行。活动入口位于华为商城APP的“我的服务日”页面。在此次活动中,华为手机用户可以享受免费的贴膜、清洁、保养和系统升级服务,同时华为笔记本电脑、指定型号耳机和智能眼镜的用户也可以享受免费的外观清洁和保养服务。站长网2023-07-10 09:15:390000月流水超「原神」,出海合成的天花板还在往上抬
这两天,SensorTower公布了2024年11月中国手游海外收入Top30,其中最值得注意的是柠檬微趣旗下Merge-2手游「GossipHarbor」排名首次超过「原神」,上升至畅销榜Top4,刷新历史最高排名。「GossipHarbor」的当月流水也超过了MoonActive旗下的「TravelTown」,成为全球月流水最高的合成类游戏。0000