Stable Diffusion团队放大招!新绘画模型直出AI海报,实现像素级图像生成
开源AI绘画扛把子,Stable Diffusion背后公司StabilityAI再放大招!
全新开源模型DeepFloyd IF,一下获星2千 并登上GitHub热门榜。

DeepFloyd IF不光图像质量是照片级的,还解决了文生图的两大难题:
准确绘制文字。(霓虹灯招牌上写着xxx)
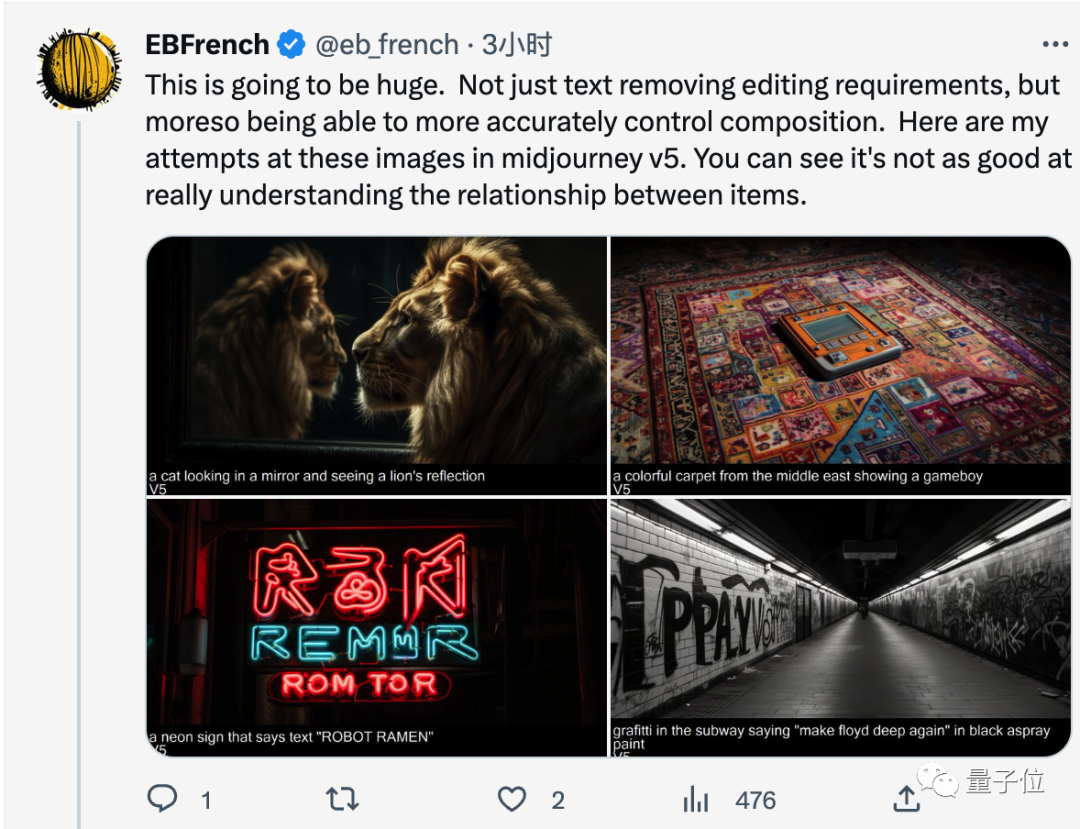
以及准确理解空间关系。(一只猫照镜子看见狮子的倒影)
网友表示,这可是个大事,之前想让Midjourney v5在霓虹灯招牌上写个字AI都是瞎划拉两笔,对于镜子理解的也不对。
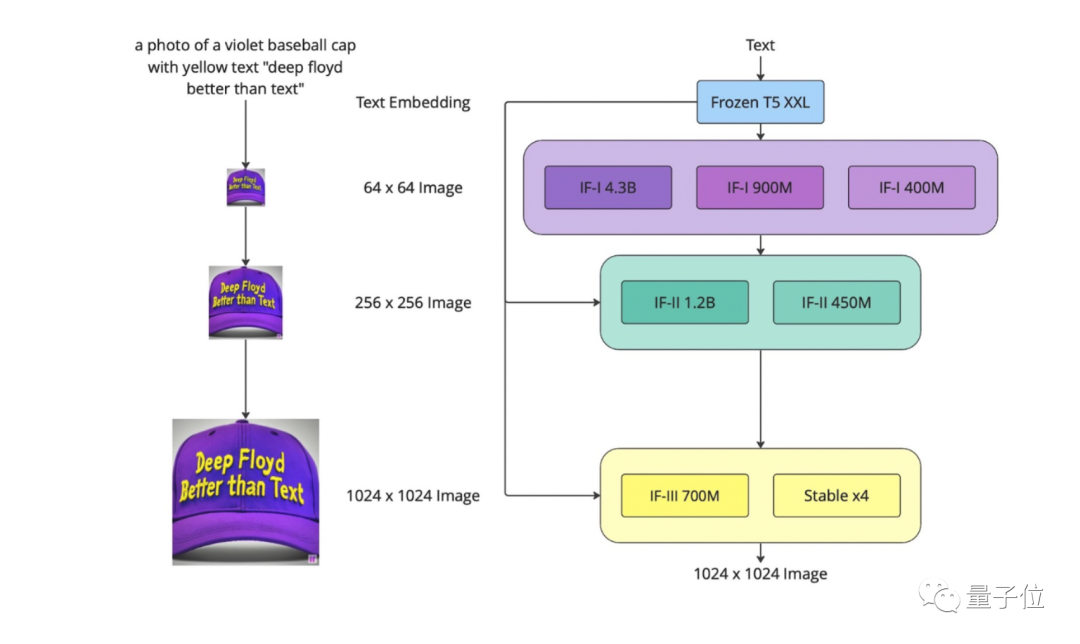
使用DeepFloyd IF,可以把指定文字巧妙放置在画面中任何地方。
霓虹灯招牌、街头涂鸦、服饰、手绘插画,文字都会以合适的字体、风格、排版出现在合理的地方。
这意味着,AI直出商品渲染图、海报等实用工作流程又打通一环。
还在视频特效上开辟了新方向。
目前DeepFloyd IF以非商用许可开源,不过团队解释这是暂时的,获得足够的用户反馈后将转向更宽松的协议。

有需求的小伙伴可以抓紧反馈起来了。
像素级图像生成
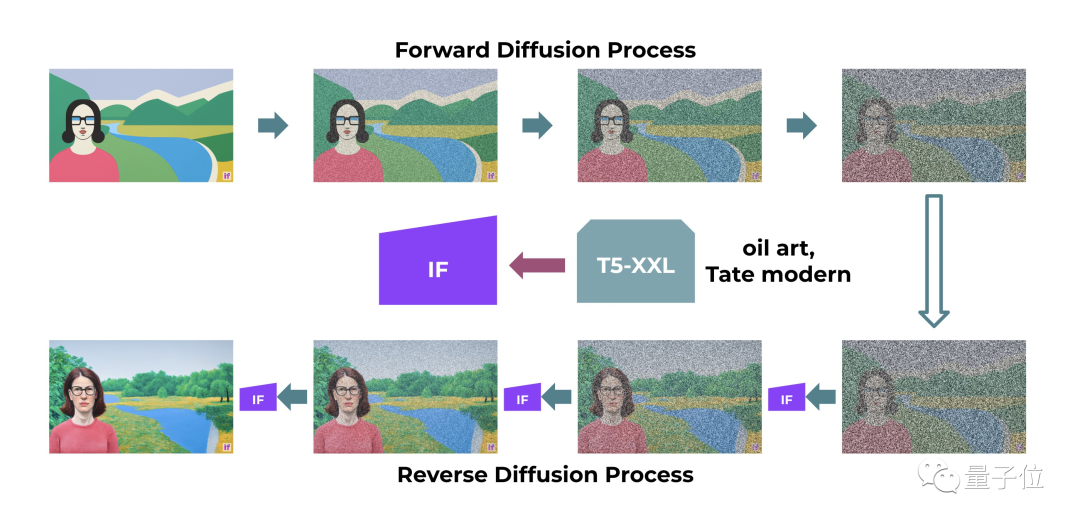
DeepFloyd IF仍然基于扩散模型,但与之前的Stable Diffusion相比有两大不同。
负责理解文字的部分从OpenAI的CLIP换成了谷歌T5-XXL,结合超分辨率模块中额外的注意力层,获得更准确的文本理解。
负责生成图像的部分从潜扩散模型换成了像素级扩散模型。
也就是扩散过程不再作用于表示图像编码的潜空间,而是直接作用于像素。

官方还提供了一组DeepFloyd IF与其他AI绘画模型的直观对比。

可以看出,使用T5做文本理解的谷歌Parti和英伟达eDiff-1也都可以准确绘制文字,AI不会写字这事就是CLIP的锅。
不过英伟达eDiff-1不开源,谷歌的几个模型更是连个Demo都不给,DeepFloyd IF就成了更实际的选择。
具体生成图像上DeepFloyd IF与之前模型一致,语言模型理解文本后先生成64x64分辨率的小图,再经过不同层次的扩散模型和超分辨率模型放大。
在这种架构上,通过把指定图像缩小回64x64再使用新的提示词重新执行扩散,也实现以图生图并调整风格、内容和细节。
并且不需要对模型做微调就可直接实现。
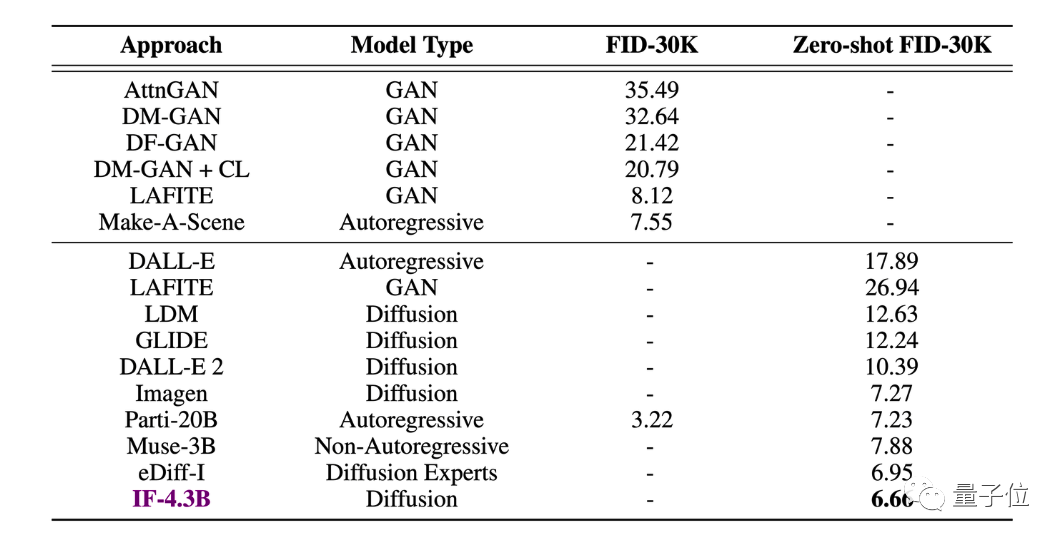
另外,DeepFloyd IF的优势还在于,IF-4.3B基础模型是目前扩散模型中U-Net部分有效参数是最多的。
在实验中,IF-4.3B取得了最好的FID分数,并达到SOTA(FID越低代表图像质量越高、多样性越好)。
谁是DeepFloyd
DeepFloyd AI Research是StabilityAI旗下的独立研发团队,深受摇滚乐队平克弗洛伊德影响,自称为一只“研发乐队”。
主要成员只有4人,从姓氏来看均为东欧背景。
这次除了开源代码外,团队在HuggingFace上还提供了DeepFloyd IF模型的在线试玩。
我们也试了试,很可惜的是目前对中文还不太支持。
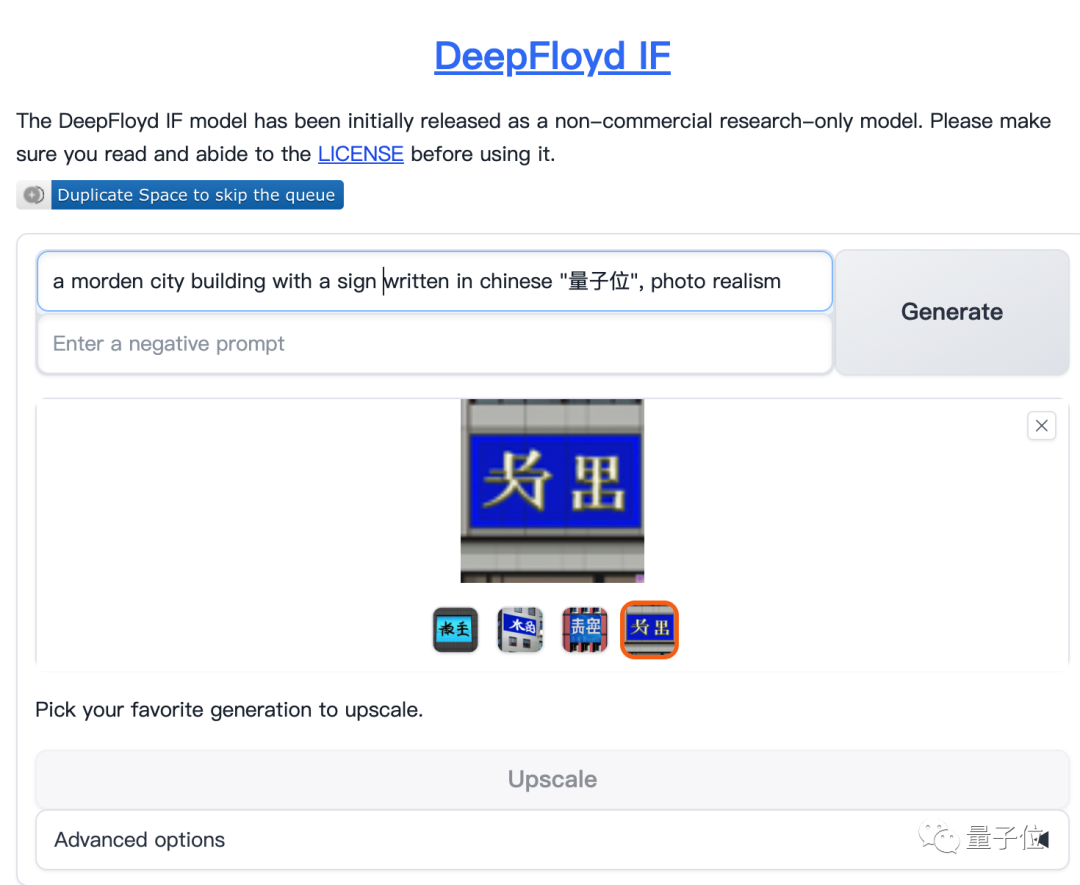
原因可能是其训练数据集LAION-A里面中文内容不多,不过既然开源了,相信在中文数据集上训练好的变体也不会太晚出现。

One More Thing
DeepFloyd IF并不是Stability AI昨晚在开源上的唯一动作
语言模型方面,他们也推出了首个开源并引入RLHF技术的聊天机器人StableVicuna,基于小羊驼Vicuna-13B模型实现。
目前代码和模型权重已开放下载。
完整的桌面和移动界面也即将发布。

Deepfloyd IF在线试玩:
https://huggingface.co/spaces/DeepFloyd/IF
代码:
https://github.com/deep-floyd/IF
StableVicuna在线试玩:
https://huggingface.co/spaces/CarperAI/StableVicuna
权重下载:
https://huggingface.co/CarperAI/stable-vicuna-13b-delta
参考链接:
[1]https://deepfloyd.ai/deepfloyd-if
[2]https://stability.ai/blog/deepfloyd-if-text-to-image-model
[3]https://stability.ai/blog/stablevicuna-open-source-rlhf-chatbot
[4]https://stable-diffusion-art.com/how-stable-diffusion-work/
—完—
万兴天幕大模型4月28日公测 文生视频支持60秒+内容
万兴科技公布其旗下音视频多媒体大模型——万兴“天幕”将于4月28日迎来公开测试阶段。公司副总裁朱伟指出,尽管大模型在文本和图像领域已经实现了生产力的商业化应用,但在音视频领域,由于数据集不足、视频内容结构复杂、算力成本高昂等问题,其成熟应用仍需时间。他预测,随着技术的不断进步,2024年有望成为AI视频领域的爆发年,届时视频大模型将迎来快速迭代。站长网2024-04-18 20:47:440000谷歌因隐私问题被迫推迟 Bard 聊天机器人在欧盟的发布
谷歌在欧盟推出其人工智能聊天机器人Bard的计划不得不推迟,因为该机器人的主要数据监管机构对隐私问题提出了担忧。爱尔兰数据保护委员会周二表示,这家科技巨头迄今为止提供的有关其生成人工智能工具如何保护欧洲人隐私的信息不足以证明其在欧盟的推出是合法的。根据欧盟通用数据保护条例(GDPR),这家总部位于都柏林的机构是谷歌在欧洲的主要数据监管机构。站长网2023-06-14 13:54:270000JetBrains 推出新 AI 编码助手,结合多个大型语言模型以实现供应商中立
JetBrains于当地时间周三发布了一款新的AI编码助手,这款助手能够从开发者的集成开发环境(IDE)获取信息,并将其反馈给AI软件,以提供编码建议、代码重构和文档支持。这家开发工具公司声称,其AI助手是第一个供应商中立的此类产品,因为它使用了多个大型语言模型,而不是依赖单一的AI平台。站长网2023-12-08 10:43:220001元宇宙平台Decentraland与Inworld合作 引入人工智能NPC
Decentraland是一个知名的元宇宙平台,他们与人工智能公司Inworld合作,利用人工智能技术为其虚拟世界注入更多生命力。站长网2023-08-11 16:10:530000周星驰首部短剧上线:首集播放量超千万,徐志胜登上热搜
周星驰首部短剧终于来了。6月2日下午17:00,抖音账号“九五二七剧场”上线短剧《金猪玉叶》第一集。据悉,九五二七剧场是周星驰发起的短剧剧场厂牌,《金猪玉叶》则是九五二七剧场上线的首部短剧,由周星驰出品、易小星监制、马史导演。站长网2024-06-03 17:01:240000