看见这张图没有,你就照着画:谷歌图像生成AI掌握多模态指令
用图2的风格画图1的猫猫并给它戴上一顶帽子。谷歌新设计的一种图像生成模型已经能做到这一点了!通过引入指令微调技术,多模态大模型可以根据文本指令描述的目标和多张参考图像准确生成新图像,效果堪比 PS 大神抓着你的手助你 P 图。

在使用大型语言模型(LLM)时,我们都已经见证过了指令微调的重要性。如果应用得当,通过指令微调,我们能让 LLM 帮助我们完成各种不同的任务,让其变成诗人、程序员、剧作家、科研助理甚至投资经理。
现在,大模型已经进入了多模态时代,指令微调是否依然有效呢?比如我们能否通过多模态指令微调控制图像生成?不同于语言生成,图像生成一开始就涉及到多模态。我们可否有效地让模型掌握多模态的复杂性?
为了解决这一难题,Google DeepMind 和 Google Research 提出可将多模态指令方法用于图像生成。该方法可将不同模态的信息交织在一起来表达图像生成的条件(图1左图给出了几个示例)。
具体来说,多模态指令可增强语言指令,比如用户可让生成模型按照指定参照图像的风格对所生成的图像进行渲染。如此一来,就能以对人类而言很直观的交互界面有效地为图像生成任务设定多模态条件。
基于这一思路,该团队打造了一个多模态指令图像生成模型:Instruct-Imagen。

论文地址:https://arxiv.org/abs/2401.01952

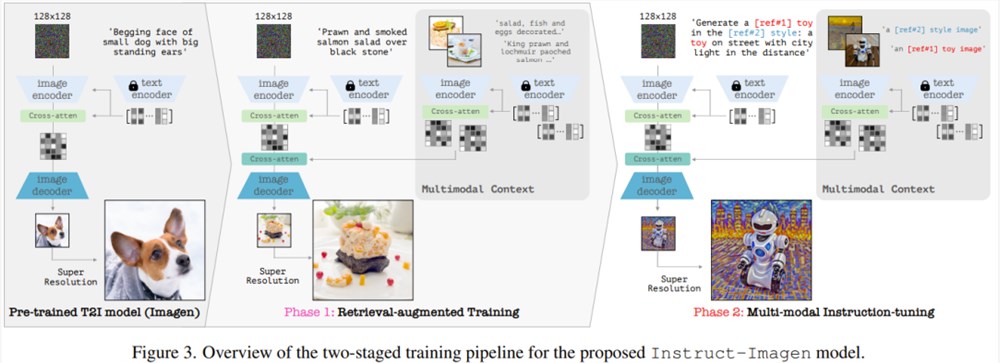
该模型使用了一种两阶段训练方法:首先增强模型处理多模态指令的能力,然后忠实地遵循多模态的用户意图。
在第一阶段,该团队采用了一个预训练的文本到图像模型,其任务是处理额外的多模态输入;之后再对其进行微调,使其能准确地响应多模态指令。具体而言,他们采用的预训练模型是一个扩散模型(diffusion model),并使用相似的 (图像,文本) 上下文对其进行了增强,这些上下文取自一个网络规模级的 (图像,文本) 语料库。
在第二阶段,该团队在多种图像生成任务上对模型进行了微调,其中每个任务都搭配了对应的多模态指令 —— 这些指令中囊括了各自任务的关键要素。经过以上步骤,所得到的模型 Instruct-Imagen 可以非常娴熟地处理多种模态的融合输入(比如草图加用文本指示描述的视觉样式),从而可以生成准确符合上下文且足够亮眼的图像。
如图1所示,Instruct-Imagen 表现卓越,能够理解复杂的多模态指令并生成忠实遵照人类意图的图像,甚至能很好地处理之前从未见过的指令组合。

根据人类的反馈表明,在许多实例中,Instruct-Imagen 不仅能媲美针对特定任务的模型处理对应任务的表现,甚至还能超越它们。不仅如此,Instruct-Imagen 还表现出了强大的泛化能力,可以用于未曾见过和更复杂的图像生成任务。
用于生成的多模态指令
该团队使用的预训练模型是扩散模型并且用户可以为其设定输入条件,具体请参看原论文。
对于多模态指令,为了保证通用性和泛化能力,该团队提出了一种统一的多模态指令格式,其中语言的作用是明确陈述任务的目标,多模态条件则是作为参考信息。
这种新提出指令格式包含两个关键组件:(1) 有效负载文本指令,其作用是详细描述任务目标并给出参考信息标识,比如 [ref#?]。(2) 多模态的上下文,带有配对的 (标识 文本,图像)。然后,该模型使用一个共享的指令理解模型来处理文本指令和多模态上下文 —— 这里并不会限定上下文的具体模态。
图2通过三个示例展示了这一格式可以如何表示之前的各种生成任务,这说明这种格式可以兼容之前的图像生成任务。更重要的是,语言很灵活,因此无需针对模态和任务进行任何专门设计,就能将多模态指令扩展用于新任务。

Instruct-Imagen
Instruct-Imagen 的基础是多模态指令。基于此,该团队基于一种预训练的文本到图像扩散模型设计了模型架构,即级联扩散模型(cascaded diffusion model),使其可以完全采用输入的多模态指令条件。
具体来说,他们使用了 Imagen 的一个变体版本,参阅论文《Photorealistic text-to-image diffusion models with deep language understanding》,并基于他们的内部数据源进行了预训练。其完整模型包含两个子组件:(1) 文本到图像组件,其任务是仅使用文本 prompt 生成128×128分辨率的图像;(2) 文本条件式超分辨率模型,其可将128分辨的图像提升至1024分辨率。
至于对多模态指令的编码,可见图3(右),其中展示了 Instruct-Imagen 编码多模态指令的数据流。
以两阶段方法训练 Instruct-Imagen
Instruct-Imagen 的训练流程分为两个阶段。
第一阶段是检索增强式文本到图像训练,即使用经过增强的检索到的近邻 (图像,文本) 对继续训练文本到图像的生成。
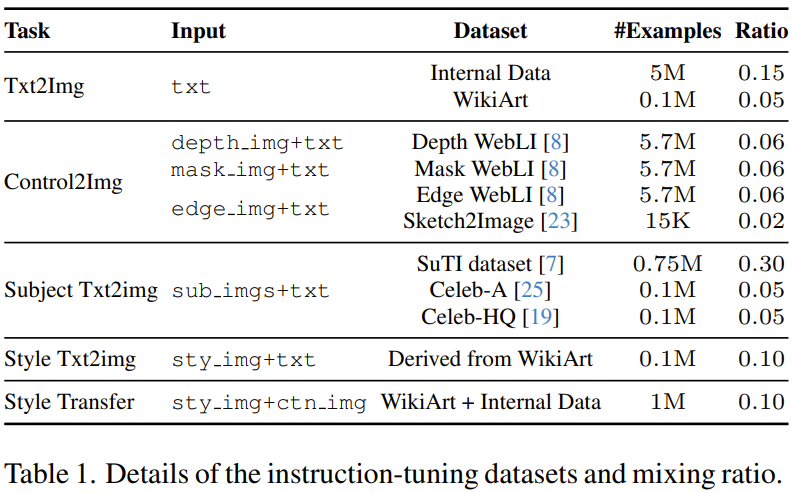
第二阶段则是对第一阶段的输出模型进行微调,这会用到混合的多样化的图像生成任务,其中每个任务都搭配了对应的多模态指令。具体来说,该团队使用了5个任务类别的11个图像生成数据集,见表1。
在这两个训练阶段中,模型都是端到端优化的。
实验
该团队对新提出的方法和模型进行了实验评估,并深度分析了 Instruct-Imagen 的设计和失败模式。
实验设置
该团队在两种设置下对模型进行了评估,即领域内任务评估和零样本任务评估,其中后一种设置比前一种设置更具挑战性。
主要结果
图4比较了 Instruct-Imagen 和基准方法及之前的方法,结果表明其在领域内评估和零样本评估上足以媲美之前的方法。

这表明多模态指令训练可以增强模型在训练数据有限的任务(比如风格化生成)上的性能,同时还能维持在数据丰富的任务(比如生成像照片的图像)上的效果。如果没有多模态指令训练,多任务基准往往会得到较差的图像质量和文本对齐效果。
举个例子,在图5的上下文风格化(in-context stylization)示例中,多任务基准难以分辨风格与物体,于是在生成结果中复现了物体。出于类似的原因,其在风格迁移任务上也表现很差。这些观察凸显了指令微调的价值。

不同于依赖针对特定任务的当前方法或训练,Instruct-Imagen 通过利用组合不同任务的目标的指令并在上下文中执行推理,可以高效地管理组合式任务(无需微调,每个示例需要18.2秒)。
如图6所示,Instruct-Imagen 在指令跟随和输出质量方面总是优于其它模型。

不仅如此,在多模态上下文中存在多个参考的情况下,多任务基准模型无法将文本指令与参考对应起来,导致一些多模态条件被忽略。这些结果进一步展现了新提出的模型的有效性。
模型分析和消融研究
该团队对模型的限制和失败模式进行了分析。
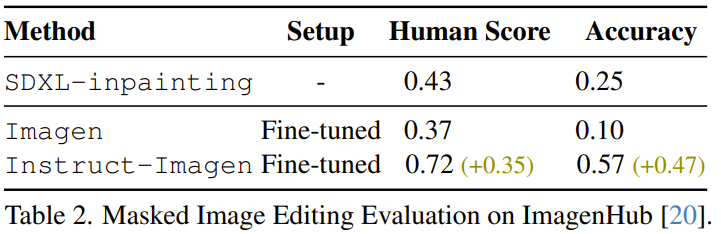
比如该团队发现,微调后的 Instruct-Imagen 可以编辑图像。如表2所示,通过比较之前的 SDXL-inpainting、在 MagicBrush 数据集上微调过的 Imagen 以及微调后的 Instruct-Imagen,可以发现微调后的 Instruct-Imagen 大幅优于专门为基于掩码的图像编辑设计的模型。
但是,微调后的 Instruct-Imagen 却会在编辑后的图像中生成伪影,尤其是超分辨率步骤之后的高分辨率输出,如图7所示。研究者表示,这是由于该模型之前没有学习过直接从上下文准确地复制像素。

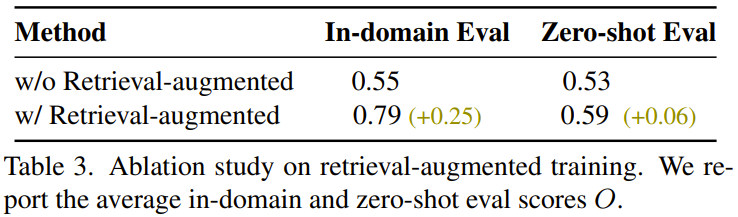
该团队还发现,检索增强式训练有助于提升泛化能力,结果如表3所示。
对于 Instruct-Imagen 的失败模式,研究者发现,当多模态指令更复杂时(至少3个多模态条件),Instruct-Imagen 难以生成遵从指令的结果。图8给出了两个示例。

下面再展示一些在训练中未曾见过的复杂任务上的结果。


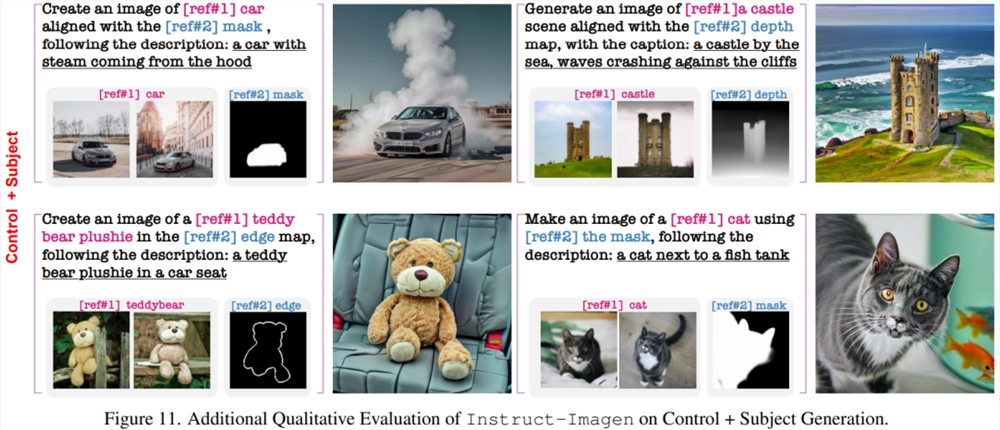
该团队也进行了消融研究证明其设计组件的重要性。
不过,出于安全性考虑,谷歌目前还没有发布该研究的代码和 API。
请参阅原始论文以获取更多详细信息。
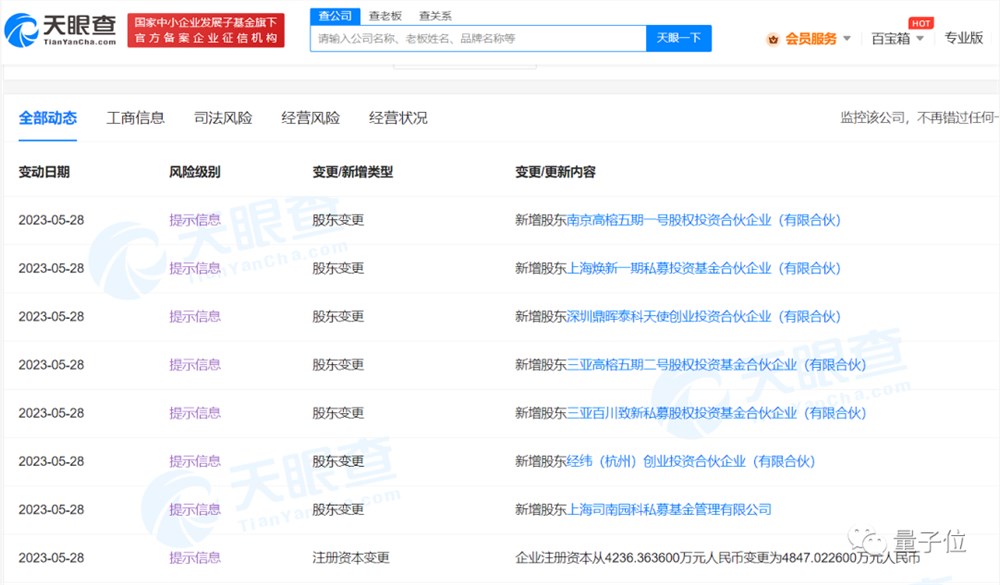
稚晖君刚拿了百度投资,估值被曝已超独角兽
“华为天才少年”稚晖君创业项目,刚被百度投了!量子位获悉,稚晖君创业项目智元机器人,日前完成了第三轮融资,市场估值被曝在十几亿美元左右。天眼查App显示,本轮新增股东包括李彦宏旗下三亚百川致新私募股权投资基金合伙企业(有限合伙),以及经纬、高榕等一线VC,注册资本增至约4847.02万元。智元机器人关联公司名为上海智元新创技术有限公司,成立于2023年2月,法定代表人为舒远春。站长网2023-05-30 14:05:040001时装品牌Selkie创始人:生成式人工智能可以成为艺术家的工具
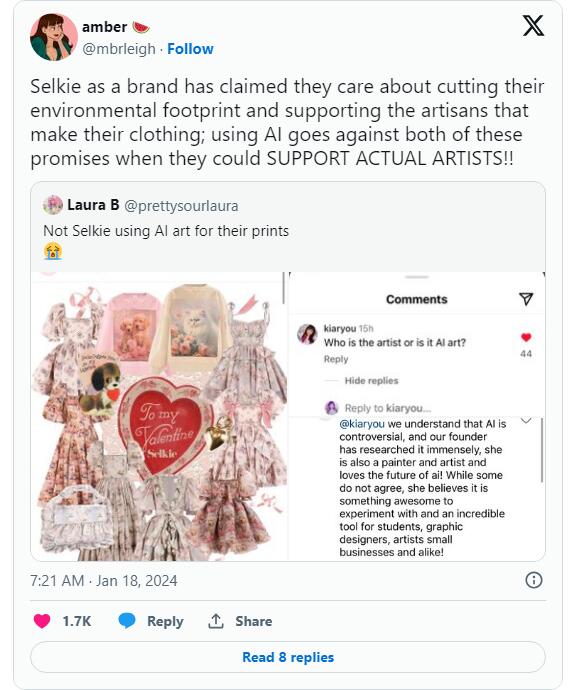
在社交媒体平台Instagram和TikTok上风靡一时的时尚品牌Selkie,近日宣布推出备受期待的情人节系列,然而,该系列的设计却引发了一场关于人工智能在艺术中使用的激烈争议。站长网2024-01-22 09:55:220000花2980被割韭菜?大V不要做低价社群,又累又不赚钱还烂口碑!
各位村民好,我是村长。就在前不久,关于某大V收了2980的社群会员费,割了一波韭菜。在社群、IP圈子搞得沸沸扬扬,余波未平。会员交了2980以后,刚入群的前几天,群里面还是比较热闹的,还有新人发红包、小助理活跃气氛。但是现在群里面没有新人加入了、也没有分享有价值的信息、小助理也换了四五波人。该会员最早是被这位大V的才华、影响力所吸引,抱着期待加入社群的。站长网2023-07-04 15:58:110000新型神经网络ResFields 擅长理解随时间变化的复杂 3D 场景
ResFields提出了一种新的神经网络结构,可以更好地表示复杂的时空信号。该方法的核心思想是在多层感知机(MLP)中替换一个或多个层,使用依赖时间的可训练残差权重参数。这种结构可以显著提升MLP的时空建模能力。项目地址:https://markomih.github.io/ResFields/站长网2023-09-13 10:26:490000亚马逊推出搭载英伟达 H100 GPU 的新 Amazon EC2 P5 实例 助力 AI 训练与推理
站长之家(ChinaZ.com)7月27日消息:AWS用户现在可以访问AI训练和推理领域业界基准测试中展示的领先性能。图片来自NVIDIA这家云计算巨头正式推出了由英伟达H100TensorCoreGPU提供支持的新AmazonEC2P5实例。该服务允许用户通过浏览器一键扩展生成式AI、高性能计算(HPC)和其他应用程序。站长网2023-07-27 09:59:030001