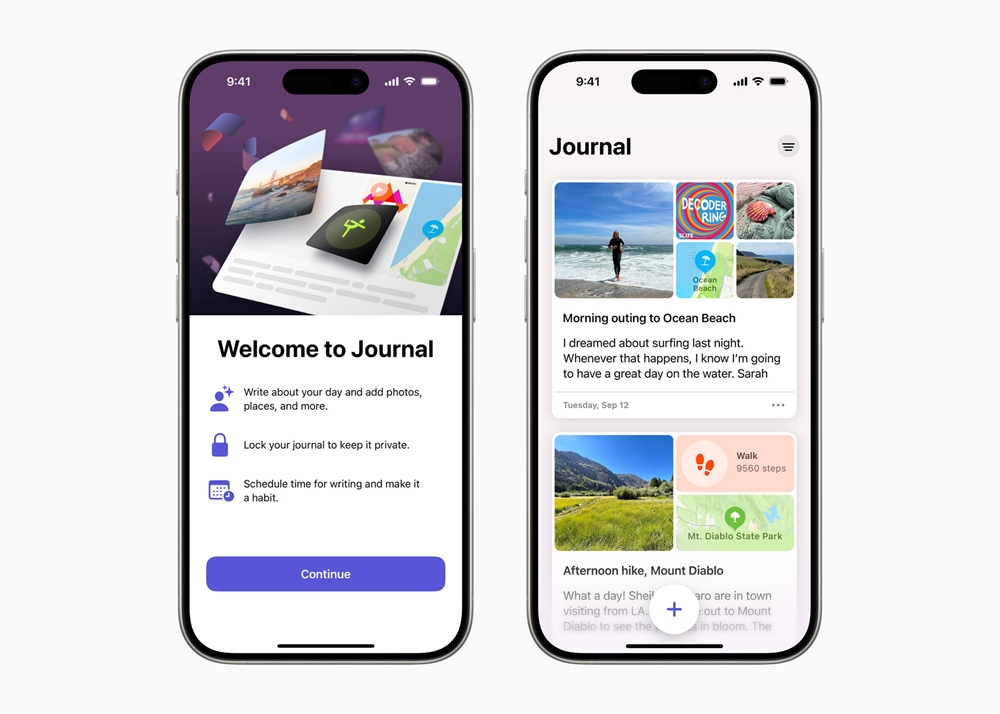
无需文本标注,TF-T2V把AI量产视频的成本打下来了!华科阿里等联合打造
在过去短短两年内,随着诸如LAION-5B 等大规模图文数据集的开放,Stable Diffusion、DALL-E2、ControlNet、Composer ,效果惊人的图片生成方法层出不穷。图片生成领域可谓狂飙突进。
然而,与图片生成相比,视频生成仍存在巨大挑战。首先,视频生成需要处理更高维度的数据,考虑额外时间维度带来的时序建模问题,因此需要更多的视频 - 文本对数据来驱动时序动态的学习。然而,对视频进行准确的时序标注非常昂贵。这限制了视频 - 文本数据集的规模,如现有 WebVid10M 视频数据集包含10.7M 视频 - 文本对,与 LAION-5B 图片数据集在数据规模上相差甚远,严重制约了视频生成模型规模化的扩展。
为解决上述问题,华中科技大学、阿里巴巴集团、浙江大学和蚂蚁集团联合研究团队于近期发布了 TF-T2V 视频方案:
论文地址:https://arxiv.org/abs/2312.15770
项目主页:https://tf-t2v.github.io/
即将开源代码地址:https://github.com/ali-vilab/i2vgen-xl (VGen 项目)
该方案另辟蹊径,提出了基于大规模无文本标注视频数据进行视频生成,能够学习丰富的运动动态。
先来看看 TF-T2V 的视频生成效果:
文生视频任务
提示词:生成在冰雪覆盖的土地上有一只冰霜般的大生物的视频。
提示词:生成一只卡通蜜蜂的动画视频。
提示词:生成包含一辆未来幻想摩托车的视频。
提示词:生成一个小男孩快乐微笑的视频。
提示词:生成一个老人感觉头疼的视频。
组合式视频生成任务
给定文本与深度图或者文本与素描草图,TF-T2V 能够进行可控的视频生成:
也可以进行高分辨率视频合成:
半监督设定
在半监督设定下的 TF-T2V 方法还可以生成符合运动文本描述的视频,如 「人从右往左跑」。
方法简介
TF-T2V 的核心思想是将模型分为运动分支和表观分支,运动分支用于建模运动动态,表观分支用于学习视觉表观信息。这两个分支进行联合训练,最终可以实现通过文本驱动视频生成。
为了提升生成视频的时序一致性,作者团队还提出了一种时序一致性损失,显式地学习视频帧之间的连续性。
值得一提的是,TF-T2V 是一种通用的框架,不仅适用于文生视频任务,还能应用于组合式视频生成任务,如 sketch-to-video、video inpainting、first frame-to-video 等。
具体细节和更多实验结果可以参考原论文或者项目主页。
此外,作者团队还把 TF-T2V 作为教师模型,利用一致性蒸馏技术得到了 VideoLCM 模型:
论文地址:https://arxiv.org/abs/2312.09109
项目主页:https://tf-t2v.github.io/
即将开源代码地址:https://github.com/ali-vilab/i2vgen-xl (VGen 项目)
不同于之前视频生成方法需要大约50步 DDIM 去噪步骤,基于 TF-T2V 的 VideoLCM 方法可以只需要进行大约4步推理去噪就生成高保真的视频,极大地提升了视频生成的效率。
一起来看看 VideoLCM 进行4步去噪推理的结果:
具体细节和更多实验结果可以参考 VideoLCM 原论文或者项目主页。
总而言之,TF-T2V 方案为视频生成领域带来了新思路,克服了数据集规模和标注难题带来的挑战。利用大规模的无文本标注视频数据,TF-T2V 能够生成高质量的视频,并应用于多种视频生成任务。这一创新将推动视频生成技术的发展,为各行各业带来更广阔的应用场景和商业机会。
小米眼镜官博上线 旗下首款AI眼镜将发布
站长之家(ChinaZ.com)2月7日消息:近日,有网友发现小米眼镜官方微博已经正式上线,其认证主体为小米通讯技术有限公司。这一消息引发了业界和消费者的广泛关注。00008人生产销售假冒苹果Airpods获利约2200万 被判有期徒刑
据深圳市中级人民法院消息,苹果公司是“Airpods”和“AirpodsPro”商标的所有权人,这两个商标涵盖耳机等产品。被告罗某洲、马某华等人生产了假冒苹果公司注册商标的蓝牙耳机,并将其销售以牟利。这些侵权的蓝牙耳机和包装上不论是否印有苹果公司注册商标,在连接苹果手机的蓝牙后,屏幕会弹出“Airpods”或“AirpodsPro”的提示。站长网2023-04-23 15:43:250002ChatGPT或将应用于iPhone 苹果接近与OpenAI达成协议
站长之家(ChinaZ.com)5月11日消息:苹果似乎即将迈出与OpenAI达成历史性合作的一步。据知情人士透露,双方正紧锣密鼓地敲定一份协议,旨在将备受瞩目的ChatGPT技术集成至即将发布的iPhone操作系统iOS18中。站长网2024-05-11 15:46:340000谁在小红书直播间“赛博相亲”?
00后玩起了一种新鲜的社交方式——赛博相亲。一个典型的举动是,在社交网络上直播交友。比如,年轻人在小红书的赛博相亲,是更看重个人特质和共同爱好,而非传统的家庭背景、物质条件。常见的话题有生活方式、星座、MBTI人格测试、游戏、动漫等,寻找"灵魂伴侣"和“同好”。当然,城市坐标、身高、年龄乃至体重,也是他们不回避的重点。站长网2024-05-25 06:37:040000小米618开门红:全渠道支付金额突破71亿元
就在刚刚,小米手机公布618最新战报称,小米618开门红全渠道支付金额突破71亿元。其中,京东开门红:小米手机包揽安卓手机品牌累计销量/销额双第一;Xiaomi13斩获4000-5999元价位段安卓手机累计销量第一RedmiK60斩获2000-2999元价位段累计销量第一RedmiNote12Turbo斩获1500-1999元价位段累计销量第一站长网2023-06-05 23:57:150001