AI视野:通义千问上线通义舞王;斯坦福炒虾机器人爆火;Midjourney艺术家数据库泄露;Meta发布AI调试工具HawkEye;小冰大模型获备案
新鲜AI产品点击了解:https://top.aibase.com/
🤖📱💼AI应用
通义千问上线通义舞王
阿里云通义千问APP近日上线了一项名为“通义舞王”的免费功能,用户只需在APP内输入相应口令并上传照片,系统即可生成个性化的舞蹈视频。
【AiBase提要】
💃 用户可以在通义千问APP内输入“通义舞王”或“全民舞王”等口令,上传照片后即可生成个性化的舞蹈视频。
💃 目前提供了12种热门舞蹈模板,用户可以让各种形象在网络上跳起热门舞蹈。
💃 这一功能是由阿里通义实验室自研的视频生成模型Animate Anyone实现的,其在Github上备受关注。
Meta发布生成式AI调试工具HawkEye
Meta发布了一款名为HawkEye的生成式AI调试工具,旨在解决机器学习模型在生产中面临的挑战。HawkEye引入了分支决策系统,通过实施决策树来加速识别和解决模型异常问题,并计划将其开源,推动整个行业在AI运维方面取得重要进展。
【AiBase提要:】
🚀Meta发布生成式AI调试工具HawkEye,解决机器学习模型在生产中的挑战。
⚙️HawkEye引入分支决策系统,加速识别和解决模型异常问题。
🌐Meta计划开源HawkEye,推动整个行业在AI运维方面取得进展。
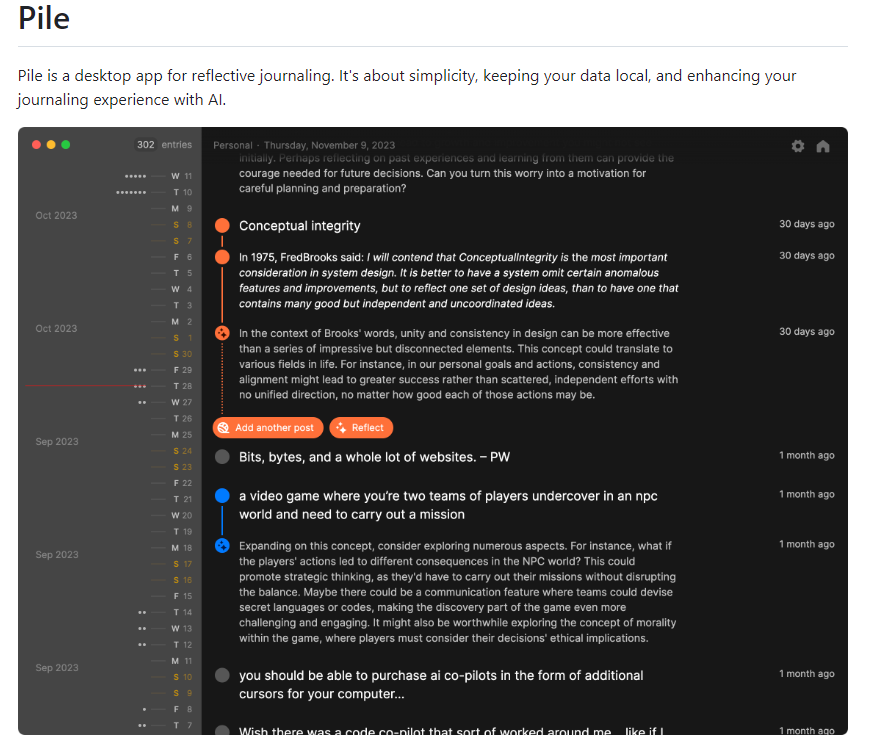
Pile:一款内置OpenAI API的AI日记软件
Pile是一款内置OpenAI API的AI日记软件,可以帮助用户撰写和保存日记条目,记录思考和经历。
项目地址:https://top.aibase.com/tool/pile
【AiBase提要】
Pile是一款整洁美观的AI日记软件,内置OpenAI API,帮助撰写和保存日记,扩展思维广度。
AI搜索功能快速查找日记内容,对话式交互帮助理解思考过程。
Pile也注重用户的隐私和数据安全,保证用户的日记内容不会被泄露。
🤖📈💻💡大模型动态
小冰大模型获备案
小冰公司宣布已获得“小冰大模型”国内备案,结束静默期,正式发布一系列产品。
【AiBase提要:】
1️⃣小冰克隆人允许创作者通过小冰框架技术克隆自己并向粉丝发布;
2️⃣歌手克隆人分支X Studio已推出4.0版本,洛天依宣布加入;
3️⃣小冰数字员工升级为小冰大模型数字员工,为企业客户提供完整的数字化解决方案。
网易有道推出子曰大模型2.0
教育科技公司网易有道推出了国内首个教育大模型“子曰”2.0版本,并发布AI家庭教师“小P老师”。
【AiBase提要:】
👉 网易有道推出国内首个教育大模型“子曰”2.0版本。
👉 发布AI家庭教师“小P老师”,提供全学段、全学科的答疑支持。
👉 推出虚拟人口语私教Hi Echo2.0和有道速读,提升英语口语能力和快速理解文档内容。
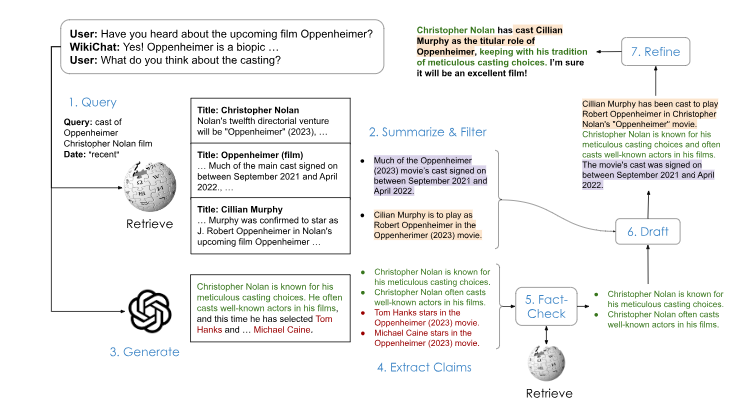
维基百科 大模型打败幻觉!斯坦福WikiChat性能领先GPT-4
斯坦福研究人员利用维基百科数据训练大模型WikiChat,成功减轻了幻觉问题,并在事实准确性和对话性方面超过了其他模型。通过优化和改进,WikiChat在各个方面的性能都显著领先,尤其在事实准确性方面达到了97.3%。
论文地址:https://aclanthology.org/2023.findings-emnlp.157.pdf
项目代码:https://top.aibase.com/tool/wikichat
【AiBase提要:】
1. 斯坦福研究人员利用维基百科数据训练了大模型WikiChat,成功减轻了幻觉问题,并在事实准确性和对话性方面超过了其他模型。
2. 通过优化和改进,WikiChat在各个方面的性能都显著领先,尤其在事实准确性方面达到了97.3%。
3. 通过检索增强生成的方法,研究人员成功解决了大模型的幻觉问题,提高了模型的事实准确性和对话性能。
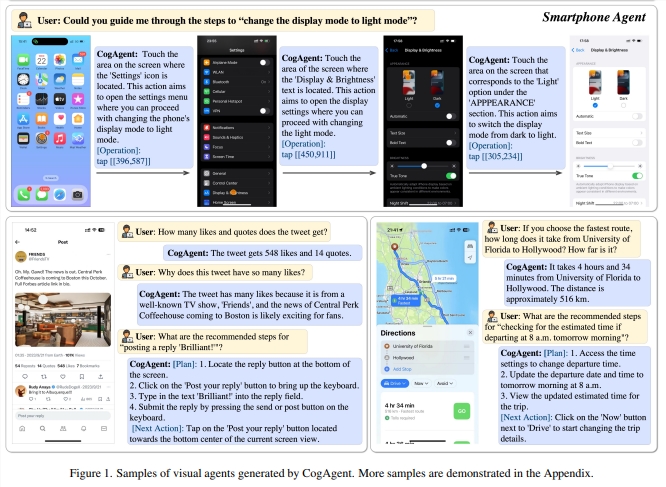
清华、浙大推GPT-4V开源平替!LLaVA、CogAgent等开源视觉模型大爆发
近期,清华、浙大等学府推动下出现了一系列性能优异的开源视觉模型,其中LLaVA、CogAgent和BakLLaVA备受关注。
论文地址:https://arxiv.org/pdf/2312.08914.pdf
【AiBase提要】
1️⃣ LLaVA、CogAgent和BakLLaVA是具有极大潜力的开源视觉语言模型。
2️⃣ LLaVA在视觉聊天和推理问答方面表现接近GPT-4水平。
3️⃣ CogAgent拥有更多功能和性能优势,支持高分辨率图像输入和OCR任务。
📰🤖📢AI新鲜事
斯坦福炒虾机器人爆火全网!成本仅22万元
斯坦福华人团队开发的炒虾机器人MobileALOHA成为了全网的热议话题。这个机器人能够炒菜、洗碗等各种复杂任务,仅用50个演示就能够让机器人始终如一地完成一项任务。

论文地址:https://mobile-aloha.github.io/resources/mobile-aloha.pdf
【AiBase提要】
斯坦福华人团队开发的炒虾机器人Mobile ALOHA刷屏全网,能完成各种复杂任务。
该机器人通过模仿学习,能够执行各种复杂的任务,并支持全身远程操控。
机器人成本低廉,仅为22万元,软件和硬件全部开源。
Midjourney训练AI使用的艺术家数据库名单泄露引发争议
Midjourney训练AI用的艺术家数据库泄露,包括知名艺术家如Banksy、David Hockney等。
【AiBase提要】
🔍Midjourney训练AI使用的艺术家数据库名单泄露,引发社交媒体批评和版权诉讼。
💬Midjourney首席执行官确认使用4000多位艺术家的名字进行生成式AI训练。
🤔该事件引发对未受监管的生成式AI发展的担忧,可能导致更多诉讼和国会听证会。
ChatGPT在儿科疾病诊断中错误率高达83%
发表在《美国医学会儿科杂志》上的一项研究表明,ChatGPT-4在儿科医学病例的诊断方面的准确率仅为17%,较去年一般医学病例的39%更低。
【AiBase提要:】
1. ChatGPT-4在儿科医学病例诊断方面准确率仅17%,比一般医学病例低39%。
2. ChatGPT难以识别疾病关系,需在准确可信的医学文献上进行专门培训。
3. 通过特定医学数据的培训和调整,有望提高聊天机器人的诊断准确性。
商汤科技推AI台灯元萝卜SenseRobot
商汤科技发布了一款名为“元萝卜SenseRobot”的台灯产品,该台灯具备AI离座感应和自动延时关灯功能,方便节能和使用。

【AiBase提要:】
元萝卜SenseRobot”外观设计灵感来源于宇航和科幻元素。
台灯产品中的AI坐姿提醒和AI专注度检测功能十分关键,能够准确识别不良坐姿,并通过语音提醒孩子矫正坐姿。
该台灯具备AI离座感应和自动延时关灯功能,方便节能和使用。
网友发掘最新旅游方式 靠Midjourney V6“游”遍中国
知名博主“快刀青衣”利用Midjourney V6生成了9个国内著名景点的效果图,包括少林寺、天坛、长城、桂林山水、九寨沟、兵马俑等,通过AI“游”遍中国。
【AiBase提要】
1️⃣ 利用Midjourney V6生成的景点效果图让网友可以“游”遍中国的著名景点。
2️⃣ Midjourney V6版本更真实、更详细,但保留了对景点最美好的想象,不再有明显的AI痕迹。
3️⃣ Midjourney V6更倾向于使用光影效果增加图片的真实感,吸引了大量网友参与讨论、分享和二次创作。
👨💻💡🎯聚焦开发者
面部图像修复突破性AI方法Dual-Pivot Tuning
加利福尼亚大学洛杉矶分校和Snap Inc.的研究团队开发了一种名为“Dual-Pivot Tuning”的个性化图像恢复方法。其主要目标是确保恢复的图像对个体的身份和降质输入图像具有高保真度,同时保持自然外观。

项目体验网址:https://top.aibase.com/tool/personalized-restoration-via-dual-pivot-tuning
【AiBase提要:】
1. 🌐 图像修复是一个复杂的挑战,研究人员提出了名为“Dual-Pivot Tuning”的突破性AI方法,可以实现人脸模糊变高清。
2. 🤳 该方法使用有限的高质量个体图像集,以保持图像对个体身份的高保真性。
3. 📊 实验证明,“Dual-Pivot Tuning”技术在盲目和少数样本的个性化面部图像修复方面优于其他方法。
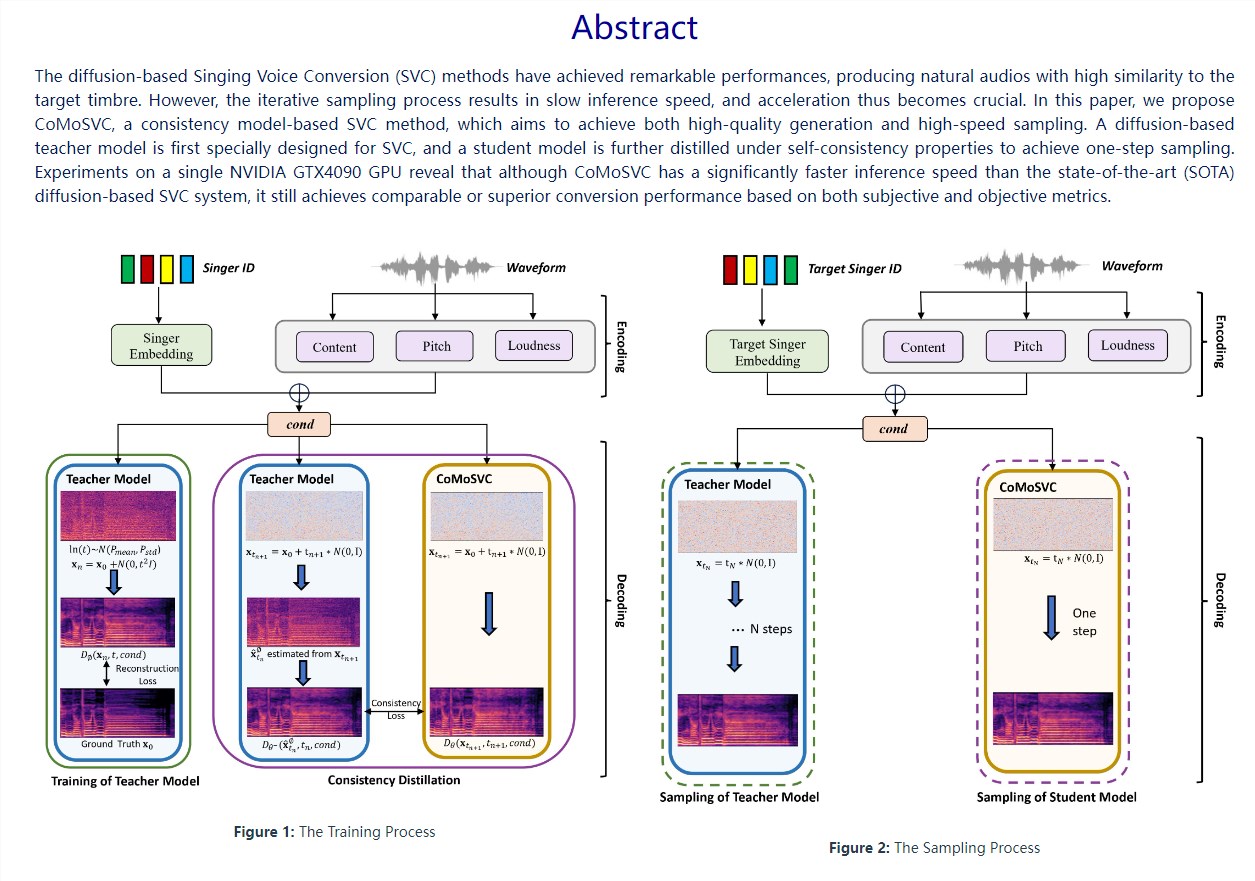
香港大学和微软推高效声音转换方法CoMoSVC
CoMoSVC是一种创新技术,可以将一个人的歌声转换成另一个人的歌声。这个项目由香港大学和微软亚洲研究员共同开发,通过一步采样实现快速高质量的声音转换,为音频转换领域带来重大进步。
项目地址:https://top.aibase.com/tool/comosvc
论文地址:https://arxiv.org/pdf/2401.01792.pdf
【AiBase提要:】
🔬 CoMoSVC设计了基于扩散的教师-学生模型,能理解和模仿不同歌手的声音特征,并快速有效地进行声音转换。
⚡️ CoMoSVC实现了一步采样,加快了处理速度,同时保持音频质量。
⚡️这项技术的出现将为音频转换带来更加高效和方便的解决方案。
HandRefiner:解决AI生图手部畸形难题
HandRefiner是一种可以修正形状不正常的手部图像的方法。在生成图像方面,目前的图像生成模型已经非常出色,但是在生成人类手部的图像时常常会出现问题,例如手指数量不对或者手形怪异。

模型下载地址:https://top.aibase.com/tool/handrefiner
项目地址:https://github.com/wenquanlu/HandRefiner/
【AiBase提要:】
能够精确地识别和修正生成图像中的畸形手部,保持图像其他部分的一致性
利用合成数据进行训练,学习不同手的样子来修正手部。
也可以用来修正脚或耳朵
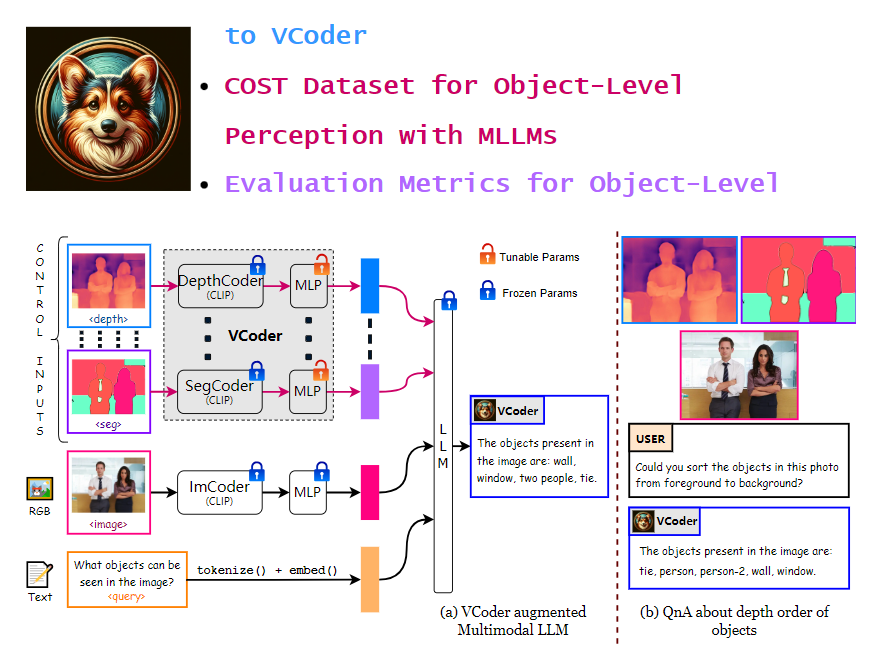
视觉编码器VCoder:提高模型在识别图像方面的能力
VCoder是一个视觉编码器,旨在提高多模态语言模型(MLLM)在识别图像中的对象和理解图像场景方面的能力。它能够帮助模型更好地理解和分析图像内容。
项目地址:https://top.aibase.com/tool/vcoder
【AiBase提要】
💡VCoder提供额外的视觉编码器,使多模态语言模型(MLLM)能够更好地理解和分析图像内容。
💡VCoder能够处理特殊类型的图像,如分割图和深度图,提升模型识别和理解图像中不同物体的能力。
💡VCoder在对象识别任务中优于基线模型,在复杂场景中表现出更高的准确性和对象计数能力。
WPS AI宣布接入WPS Mac版 提供内容生成等功能
WPS宣布,Mac版的WPS已经接入了WPSAI,这将带来内容生成、内容修改和辅助阅读等功能。现在,用户可以通过WPSAI一键生成文章大纲、讲话稿、会议纪要等文件,完成文章续写、扩充篇幅、润色段落等任务,以及利用WPSAI提炼长文档的重点,为外文文件进行解释和总结。站长网2023-10-24 17:28:140002史上最「蠢」AI凶手?剧本杀被人类一秒揪出,开发者小哥紧急调教
【新智元导读】AI剧本杀,开本了!最近,两位开发者在黑客马拉松期间创作了一款AI游戏「山庄谋杀案」,我们需要和五位AI嫌疑人对话,揪出真正的凶手。没想到,小编一番试玩后,结局出乎意料……想玩剧本杀但凑不齐人发车?别苦恼了!可以和AI一起博弈破案了,人机推理大战,速速上车!小编们亲自测评,竟然表示「猪脑过载」「ez求转人工」「素材局不收徒」「暂时不考虑FBI邀请」?站长网2024-07-11 14:20:460000反转!美国饮食失调协会下线AI客服 人类员工回归
在解雇了所有员工并用聊天机器人取而代之后,最新报道称,美国饮食失调协会(NEDA)再度宣布其求助热线已经宣布将让人类回归,并下线AI聊天机器人。站长网2023-06-03 15:40:240000stablevideo公测 用户每天可免费生成15个视频
StabilityAI官方的SVD视频生成平台已经开始公测。这个平台的功能是在SVD模型基础上增加了镜头控制的能力,让用户可以更灵活地生成视频。据介绍,这些视频是通过一些图片生成的。产品入口:https://top.aibase.com/tool/stable-video在公测阶段,每天用户可以享有150的免费额度,可以用来生成15个视频。用户们可以尽情体验这个平台带来的乐趣。站长网2024-02-22 17:50:400001苹果计划收购德国AI初创公司Brighter AI以增强隐私功能
有消息称,苹果正计划收购德国人工智能初创公司BrighterAI,该公司专注于匿名化人脸和车牌数据。据了解,苹果计划利用此次收购来增强其产品AppleVisionPro的隐私功能。这项收购意在帮助苹果最大限度地降低在公共场合拍摄的视频或照片中捕获可识别信息的风险。站长网2024-02-05 11:27:080000