视觉编码器VCoder:提高模型在识别图像方面的能力
站长网2024-01-04 11:05:260阅
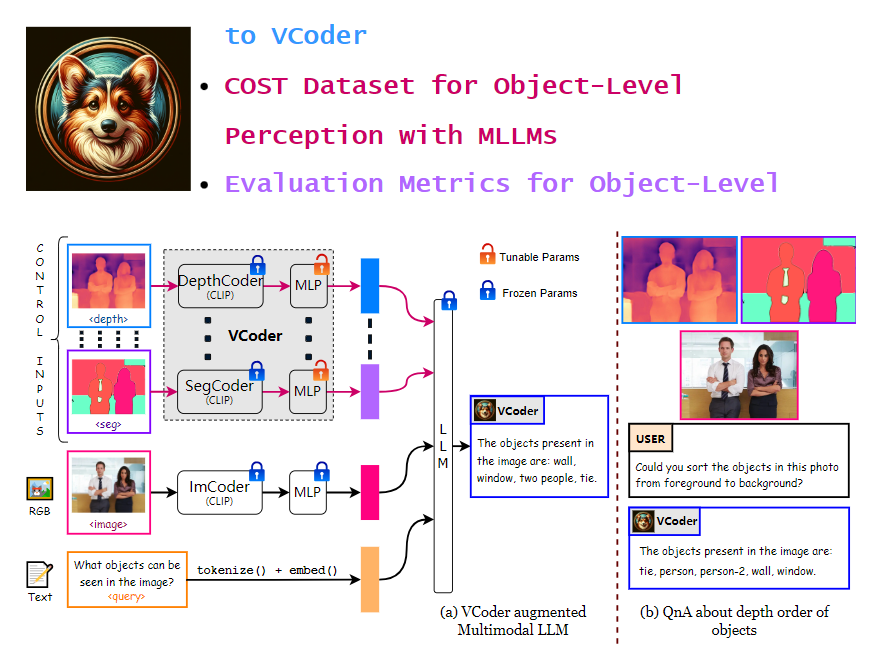
VCoder是一个视觉编码器,旨在提高多模态语言模型(MLLM)在识别图像中的对象和理解图像场景方面的能力。它能够帮助模型更好地理解和分析图像内容。
项目地址:https://top.aibase.com/tool/vcoder
该编码器具有多项功能。首先,它能够增强视觉感知能力,通过提供额外的视觉编码器,使MLLM能够更好地理解和分析图像内容。其次,VCoder能够处理特殊类型的图像,例如分割图和深度图。分割图能够帮助模型识别和理解图像中不同物体的边界和形状,而深度图则提供了物体距离相机远近的信息。最后,VCoder改善了对象感知任务的表现。通过提供额外的感知模态输入,如分割图或深度图,它显著提高了MLLM的对象感知能力,包括更准确地识别和计数图像中的对象。
在实验中,VCoder与开源的多模态LLMs(如MiniGPT-4、InstructBLIP、LLaVA-1.5和CogVLM)进行了比较,并在COST验证集上进行了测试。实验结果表明,VCoder在对象识别任务中表现最佳,特别是在对象计数和识别方面优于基线模型。在处理复杂场景中的对象计数和识别任务时,VCoder展现出更高的准确性,尤其是在场景中有许多实体时。
与GPT-4V进行比较时,实验发现GPT-4V在所有对象识别任务中表现一致,但在对象级感知方面落后于VCoder。
VCoder作为一个视觉编码器,为MLLM提供了更好的视觉感知能力,能够处理特殊类型的图像,并改善了对象感知任务的表现。在与其他模型的比较中,VCoder在对象计数和识别方面表现出色,特别是在复杂场景中。
0000
评论列表
共(0)条相关推荐
微信可以线上送实体礼物了:微信小店“蓝包”功能正灰度测试 逐步覆盖
快科技12月23日消息,微信小店近日开启送礼物”功能的灰度测试,目前一些网友的微信已经可以送礼物”,但还有部分网友表示该功能未上线。对此,微信小店客服表示:送礼物”功能在逐步覆盖中,正在逐步完善相关功能。平台对于入驻的商家都有严格的资质审核,也会监督其日常运营。该功能被曝光后,因为封面为蓝色,与常规红包形成对比,被网友称为蓝包”。站长网2024-12-23 17:33:070000百度萝卜快跑开通武汉天河机场自动驾驶接驳服务
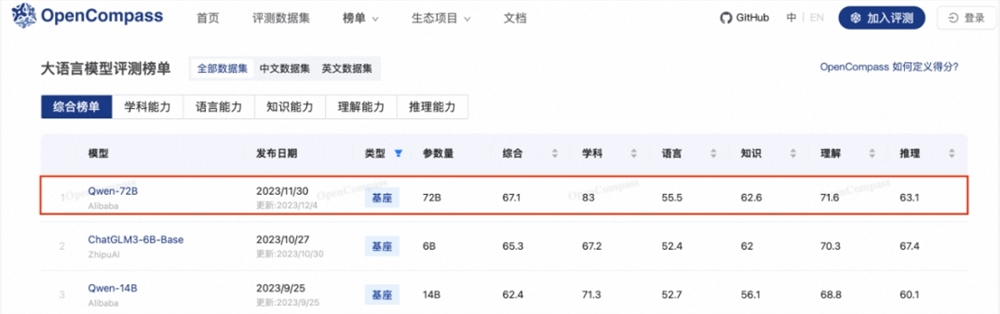
8月25日,百度萝卜快跑宣布开通武汉天河机场的自动驾驶接驳服务,目前已开启用户邀约,受邀用户即日起可率先体验。据悉,这是国内首次实现城市市区到机场之间的自动驾驶出行接驳服务,也是国内自动驾驶运营首次贯通城市道路和高速路线,百度也成为国内首个开通机场自动驾驶接驳服务的企业。站长网2023-08-26 16:12:100000通义千问72B模型荣登大模型评测平台OpenCompass榜首
中国权威的大型模型评估平台OpenCompass最近更新其排名,通义千问72B模型以67.1的高分荣登榜首。OpenCompass是由上海人工智能实验室推出的开源大型模型评估平台,其评估范围涵盖学科、语言、知识、理解和推理五个维度,能够全面评估大型模型的能力。站长网2023-12-13 11:57:480001史上最强小米手环来了!小米手环9正式公布:升级金属机身 多种腕带可选
快科技7月16日消息,今日小米宣布,小米手环9将于7月19日19点2024雷军年度演讲期间正式发布。据悉,小米手环9全新升级金属机身,同时智能体验也有全面升级。从预热海报来看,小米手环9提供了多款款式、颜色的腕带可供选择,包括橡胶带、金属带以及皮质带等,个性化进一步提升。此前,小米手环9已经通过多家机构认证,距离发布仅剩一步之遥。站长网2024-07-16 10:57:500001AI公司奥创光年Mogic AI获千万美元A轮融资
据36氪消息,AI全链路营销公司「奥创光年」(MogicAI)已于近日获得千万美元A轮融资,本轮由凯辉基金领投,老股东真格基金参与投资。本轮融资将主要用于AI视频领域的智能算法、模型研发等技术投入上,以进一步提升产品能力。站长网2023-08-09 08:49:030001