清华、浙大推GPT-4V开源平替!LLaVA、CogAgent等开源视觉模型大爆发
要点:
1、清华、浙大等中国顶尖学府提供了性能优异的GPT-4V开源替代方案。
2、LLaVA、CogAgent和BakLLaVA是三种具有极大潜力的开源视觉语言模型。
3、LLaVA在视觉聊天和推理问答方面表现出接近GPT-4水平的能力。
近期,GPT-4V的开源替代方案在中国的顶尖学府清华、浙大等的推动下,出现了一系列性能优异的开源视觉模型。其中,LLaVA、CogAgent和BakLLaVA是三种备受关注的开源视觉语言模型。
LLaVA是一个端到端训练的多模态大模型,它将视觉编码器和用于通用视觉和语言理解的Vicuna相结合,具备令人印象深刻的聊天能力。而CogAgent是在CogVLM基础上改进的开源视觉语言模型,拥有110亿个视觉参数和70亿个语言参数。
另外,BakLLaVA是使用LLaVA1.5架构增强的Mistral7B基础模型,已经在多个基准测试中优于LLaVA213B。这三种开源视觉模型在视觉处理领域具有极大的潜力。
LLaVA在视觉聊天和推理问答方面表现出接近GPT-4水平的能力。在视觉聊天方面,LLaVA的表现相对于GPT-4的评分达到了85%,在推理问答方面更是达到了92.53%的超过GPT-4的新SoTA。LLaVA在回答问题时,能够全面而有逻辑地生成回答,并且可以以JSON格式输出。
它不仅可以从图片中提取信息并回答问题,还可以将图片转化为JSON格式。LLaVA还可以识别验证码、识别图中的物体品种等,展现出了强大的多模态能力。在性能上接近GPT-4的情况下,LLaVA具有更高的成本效益,训练只需要8个A100即可在1天内完成。
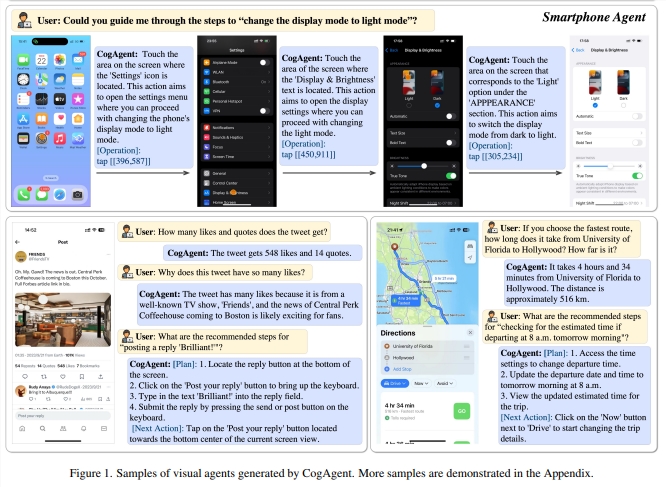
CogAgent作为在CogVLM基础上改进的开源视觉语言模型,拥有更多的功能和性能优势。它支持更高分辨率的视觉输入和对话答题,能够处理超高分辨率图像输入。
论文地址:https://arxiv.org/pdf/2312.08914.pdf
CogAgent还提供了可视化代理的能力,能够返回任何给定任务的计划、下一步行动和带有坐标的具体操作。它还增强了与图形用户界面相关的问题解答功能,可以处理与网页、PC应用程序、移动应用程序等任何图形用户界面截图相关的问题。另外,通过改进预培训和微调,CogAgent还增强了OCR相关任务的能力。这些功能的提升使得CogAgent在多个基准测试上实现了最先进的通用性能。
BakLLaVA是使用LLaVA1.5架构增强的Mistral7B基础模型,具备更好的性能和商用能力。BakLLaVA在多个基准测试中优于LLaVA213B,并且可以在某些数据上进行微调和推理。虽然BakLLaVA在训练过程中使用了LLaVA的语料库,不允许商用,但BakLLaVA2则采用了更大的数据集和更新的架构,超越了当前的LLaVA方法,具备商用能力。
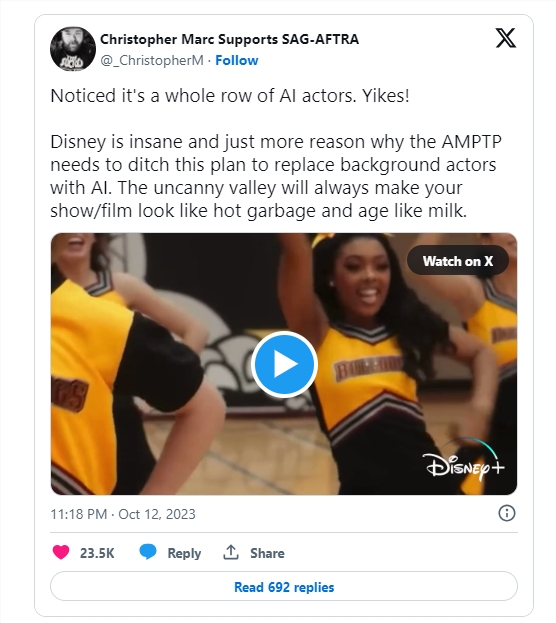
迪士尼因电影中使用的CGI生成的背景演员太假被嘲笑
要点:1.近期,迪士尼因在电影《PromPact》中使用明显不真实的CGI生成的背景演员而受到嘲笑。2.迪士尼的此举引发了有关电影制作中使用计算机生成影像的激烈辩论,担心这将取代人类演员。3.演员工会SAG-AFTRA提出了“NOFAKES法案”,旨在保护人声和肖像权,但是否能被电影制片厂和国会接受尚未确定。站长网2023-10-16 09:37:0900002023云计算十大关键词发布 “中小企业上云”入选
凤凰网科技讯7月26日消息,7月25日,由中国信息通信研究院(以下简称“中国信通院”)和中国通信标准化协会联合主办的2023年可信云大会在北京召开,大会发布了“2023云计算十大关键词”。站长网2023-07-26 21:38:540000Text2Immersion:可通过文本直接生成3D场景
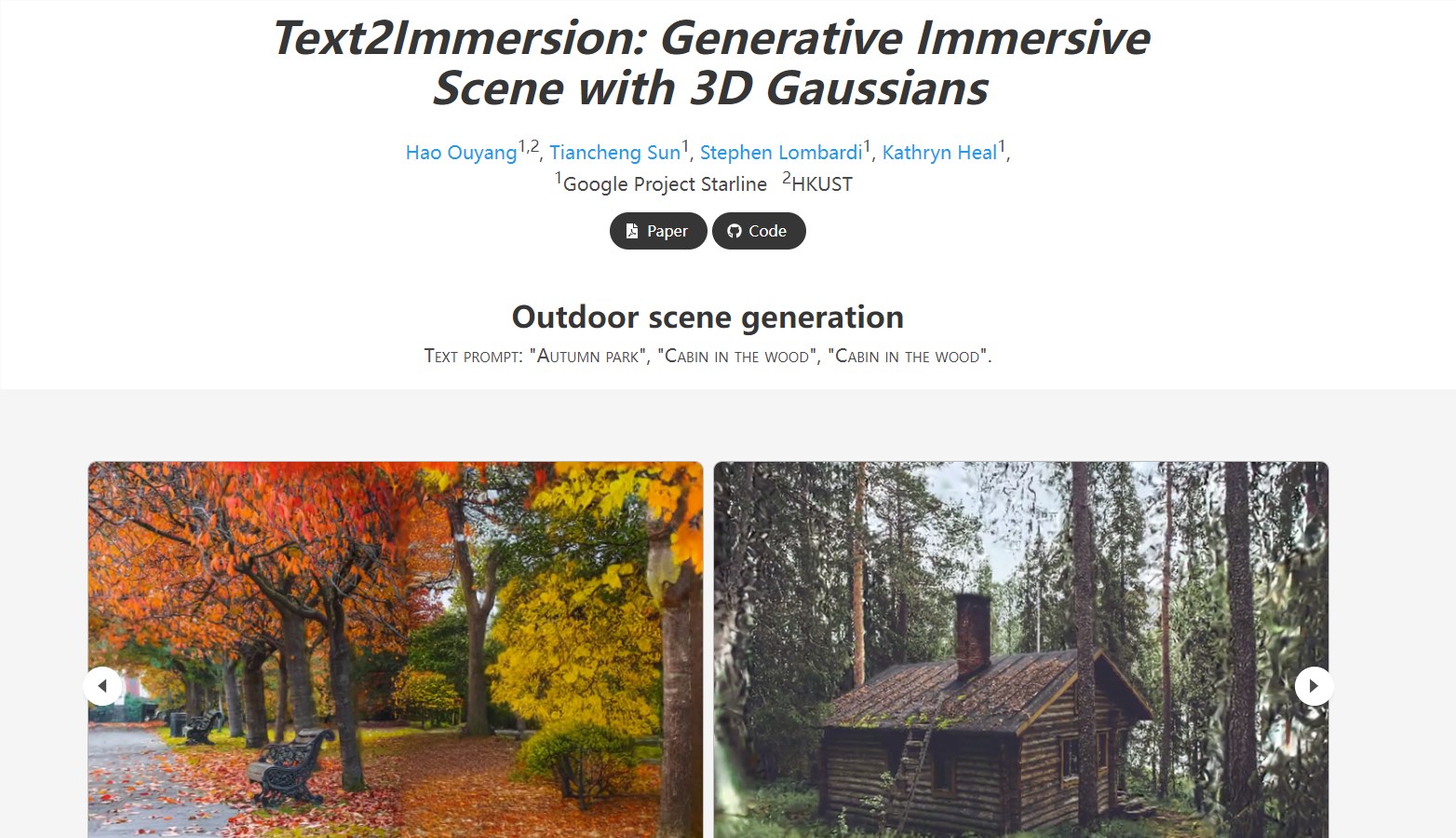
Text2Immersion是一种创新的方法,通过文本提示生成高质量的3D沉浸式场景。该项目的流程首先利用预训练的2D扩散和深度估计模型逐步生成高斯云,然后在高斯云上进行细化阶段,通过插值和细化来增强生成场景的细节。体验地址:https://ken-ouyang.github.io/text2immersion/index.html站长网2024-01-03 12:04:070000网信办开展“清朗・网络戾气整治”专项行动 严惩“开盒挂人”等违规行为
11月17日,中央网信办决定开展为期一个月的“清朗・网络戾气整治”专项行动,以严惩网络空间中的戾气问题。本次行动将重点围绕社交、短视频、直播等平台,集中整治“开盒挂人”“网络厕所”等7大类问题。0000