Meta 宣布开源多感官 AI 模型 ImageBind:整合文本、音频、视觉等六种类型数据
Meta 宣布推出一个新的开源 AI 模型,可以连接多种数据流,包括文本、音频、视觉数据、温度和动作读数。
图片来自 Meta
该模型目前仅是一个研究项目,没有立即的消费者或实际应用,但它指向了未来可以创建沉浸式、多感官体验的生成式 AI 系统,并表明了 Meta 在对手 OpenAI 和 Google 日益注重保密的时候仍在分享 AI 研究。
该研究的核心概念是将多种类型的数据链接到一个单一的多维度索引中(或者使用 AI 术语中的「嵌入空间」)。这个想法可能有点抽象,但正是这个概念支持了生成式 AI 的最近繁荣。
例如,像 DALL-E、Stable Diffusion 和 Midjourney 之类的 AI 图像生成器在训练阶段都依赖于系统,这些系统在连接文本和图像时共同寻找视觉数据中的模式,并将这些信息与图像的描述相连。这是使这些系统能够生成遵循用户文本输入的图片的基础。许多生成视频或音频的 AI 工具也是如此。
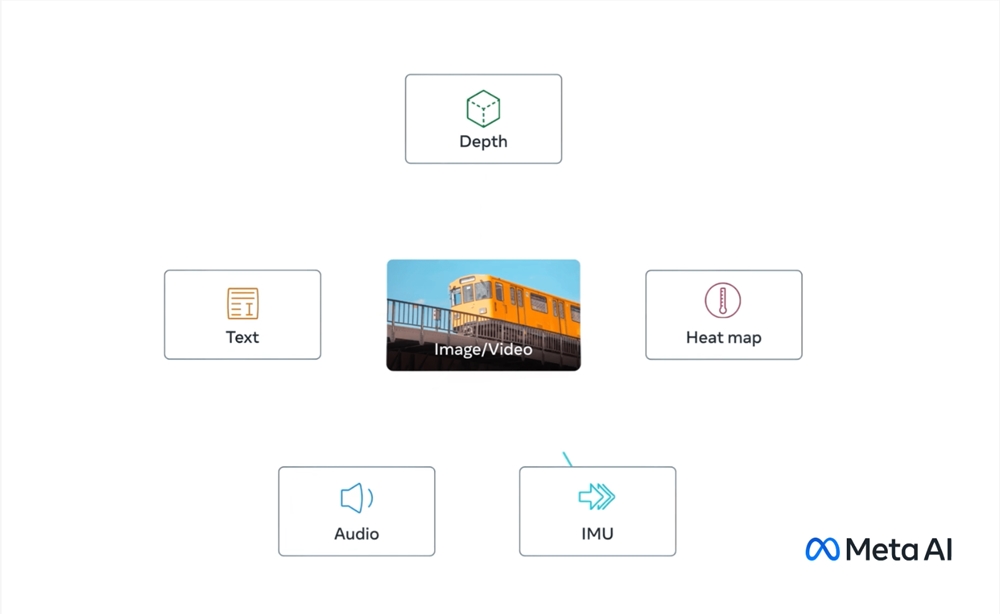
Meta 表示,它的模型 ImageBind 是第一个将六种类型的数据组合到一个单一的嵌入空间中的模型。包括在模型中的六种类型的数据是:视觉(以图像和视频形式呈现);热量(红外图像);文本;音频;深度信息;以及最有趣的——由惯性测量单元(IMU)生成的运动读数。(IMU 可在手机和智能手表中找到,在那里它们用于执行各种任务,比如从横向到纵向切换手机,区分不同类型的体育活动等。)
这个想法是未来的 AI 系统将可以像当前的 AI 系统对文本输入一样交叉参考这些数据。例如,想象一下一个未来的虚拟现实设备,它不仅可以生成音频和视觉输入,还可以生成你在物理舞台上的环境和动作。你可以要求它模拟一次长途航海,它不仅会把你放在一艘船上,背景中有海浪的声音,还会让你感受到甲板的摇摆和海洋空气的凉爽微风。
Meta 在一篇博客文章中指出,未来的模型可以增加其他感官输入流,包括「触摸、语音、气味和大脑功能磁共振成像信号」。它还声称,这项研究「将机器带到了人类能够同时、全面、直接地从许多不同形式的信息中学习的能力更近了一步」。(当然,这取决于这些步骤的大小。)
当然,这一切都非常推测性的,目前应用这些研究的可能性将会更加有限。例如,去年,Meta 展示了一种由文本描述生成短且模糊的视频的 AI 模型。像 ImageBind 这样的工作展示了系统未来版本如何整合其他数据流,例如生成与视频输出匹配的音频。
对于业内观察者来说,这项研究也很有趣,因为 Meta 正在开源其基础模型——这是人工智能世界中越来越受到关注的做法。
反对开源的人——比如 OpenAI——表示这种做法对创作者是有害的,因为竞争对手可以复制他们的工作,而且这可能会有潜在的危险,使恶意行为者利用最先进的 AI 模型。支持者回应说,开源允许第三方审查系统的问题并改进其缺陷。他们注意到这甚至可能提供商业利益,因为它实质上允许公司招募第三方开发人员作为不付费的工作人员来改进他们的工作。
Meta 迄今一直坚定地站在开源阵营,虽然并非没有困难。(例如,它最新的语言模型 LLaMA 今年早些时候在网上泄漏。)在许多方面,它在人工智能领域缺乏商业成就(该公司没有与 Bing、Bard 或 ChatGPT 等聊天机器人竞争的实际产品)使其能够采用这种方法。对于现在,在 ImageBind 上,它继续这个策略。
腾讯日赚4亿重燃电商梦,视频号带货大变局终于要来了
2023年,腾讯日赚4.3亿元,视频号终于扛起“全村的希望”。一月底,马化腾在腾讯年会上称,视频号不负众望,让腾讯在短视频时代重新具备一个坚实的抓手,2024年会大力发展直播电商。这可能是视频号发力直播电商的集结号,亦是腾讯重燃电商梦的又一关键时刻。站长网2024-03-23 13:49:540001谷歌AI搜索惨败,竟教唆网友自杀!
【新智元导读】隔壁OpenAI都杀疯了,谷歌还在收集badcase?搜索引擎AIOverview上线之后,没想到谷歌AI的邪恶程度远超想象:教唆网友自杀/谋杀、吃毒蘑菇,甚至无法识别混淆信息,犯常识错误......这几天,谷歌AI搜索给出的奇葩结果,可是被网友吵翻了天。究竟有多离谱?有人就问了这么一个问题,「如何不让芝士从披萨上滑落」?站长网2024-05-27 19:38:120000OpenAI发布最新旗舰大模型GPT-4o:免费试用 价格五折速度提高一倍
GPT-4o具体特性一览:GPT-4o模型发布:OpenAI发布了GPT-4o模型,其中"o"代表Omni,意为全能。该模型能够接受文本、音频和图像的任意组合作为输入,并生成相应的文本、音频和图像输出。免费开放:GPT-4o的所有能力将免费向所有用户开放,但新语音模式会在未来几周内优先对ChatGPTPlus会员开放。站长网2024-05-14 08:38:540000从3个核心维度,理解百度战略布局电商业务的底层逻辑
1最近几年,百度公司的表现让笔者刮目相看。除了在搜索引擎主战场稳住基本盘之外,其正在多个新业务领域遍地开花。站长网2023-05-26 18:12:070001瑞幸回应喝茅台联名咖啡能否开车:驾驶人员不建议饮用
今日,贵州茅台与瑞幸咖啡联合推出的联名咖啡“酱香拿铁”正式上市开卖。这款咖啡使用了53度贵州茅台酒,酒精度低于0.5%,并配备了白酒风味厚奶,零售价为38元/杯,使用优惠券后预计19元/杯。据瑞幸官方小程序客服回应,这款咖啡的酒精含量低于0.5度,但未成年人、孕妇、驾驶人员、酒精过敏者不建议饮用。站长网2023-09-04 10:39:300000