大模型被偷家!腾讯港中文新研究修正认知:CNN搞多模态不弱于Transfromer
在Transformer占据多模态工具半壁江山的时代,大核CNN又“杀了回来”,成为了一匹新的黑马。
腾讯AI实验室与港中文联合团队提出了一种新的CNN架构,图像识别精度和速度都超过了Transformer架构模型。
切换到点云、音频、视频等其他模态,也无需改变模型结构,简单预处理即可接近甚至超越SOTA。
团队提出了专门用于大核CNN架构设计的四条guideline和一种名为UniRepLKNet的强力backbone。
只要用ImageNet-22K对其进行预训练,精度和速度就都能成为SOTA——
ImageNet达到88%,COCO达到56.4box AP,ADE20K达到55.6mIoU,实际测速优势很大。
在时序预测的超大数据上使用UniRepLKNet,也能达到最佳水平——
例如在全球气温和风速预测上,它就超越了Nature子刊上基于Transformer的前SOTA。
更多细节,我们接着看作者投稿。
“Transformer时代”,为什么还需要CNN
在正式介绍UniRepLKNet的原理之前,作者首先解答了两个问题。
第一个问题是,为什么在Transformer大一统各个模态的时代还要研究CNN?
作者认为,Transformer和CNN只不过是相互交融的两种结构设计思路罢了,没有理由认为前者具有本质的优越性。
“Transformer大一统各个模态”正是研究团队试图修正的认知。
正如2022年初ConvNeXt、RepLKNet和另外一些工作问世之前,“Transformer在图像任务上吊打CNN”是主流认知。
这几项成果出现后,这一认知被修正为“CNN和Transformer在图像任务上差不多”。
本研究团队的成果将其进一步修正:在点云、音频、视频上,CNN比我们想象的强太多了。
在时序预测这种并不是CNN传统强项的领域(LSTM等曾是主流,最近两年Transformer越来越多),CNN都能超过Transformer,成功将其“偷家”。
因此,研究团队认为,CNN在大一统这一点上可能不弱于Transformer。
第二个问题是,如何将一个为图像任务设计的CNN用于音频、视频、点云、时序数据?
出于对简洁和通用性的永恒追求,将UniRepLKNet用于其他模态时,不对模型架构主体做任何改变(以下实验用的全都是UniRepLKNet-Small)。
只需要将视频、音频、点云、时序数据给处理成C×H×W的embedding map(对于图像来说,C=3),就能实现到其他模态的过渡,例如:
把音频的频谱图(Time×Frequency)看成是一幅单通道图像,即C=1,H=T,W=F;
将点云进行三视图投影,得到三幅单通道图像,C=3,H和W可以随意指定;
将视频中的各帧拼接到一起,极为简单地得到一张大图(例如,16帧的3×224×224视频拼接得到3×896×896的输入);
对时序数据,借鉴CorrFormer中的embedding layer将数据转换为隐空间中的张量然后简单粗暴地将其reshape成一幅单通道图像。
后文展示的结果将会证明,如此简单的设计产生的效果是极为优秀的。
大卷积核CNN架构设计
2022年,RepLKNet提出了用超大卷积核(从13×13到31×31)来构建现代CNN以及正确使用超大卷积核的几个设计原则。
但从架构层面看,RepLKNet只是简单地用了Swin Transformer的整体架构,并没有做什么改动。
当前大核CNN架构设计要么遵循现有的CNN设计原则,要么遵循现有的Transformer设计原则。
在传统的卷积网络架构设计中,当研究者向网络中添加一个3×3或5×5卷积层时,往往会期望它同时产生三个作用:
增大感受野
提高抽象层次,例如从线条到纹理、从纹理到物体的局部
通过增加深度而一般地提高表征能力(越深,参数越多,非线性越多,拟合能力越高)
那么,设计大卷积核CNN架构时,应该遵循怎样的原则呢?
本文指出,应该解耦上述三种要素,需要什么效果就用对应的结构来实现:
用少量大卷积核保证大感受野。
用depthwise3×3等小卷积提高特征抽象层次。
用一些高效结构(如SE Block、Bottleneck structure等)来提高模型的深度从而增强其一般的表示能力。
这样的解耦之所以能够实现,正是大卷积核的本质优势所保证的,即不依赖深度堆叠的大感受野。
经过系统研究,本文提出了大卷积核CNN设计的四条Architectural Guidelines。
根据这些guideline,本文提出的UniRepLKNet模型结构如下——
每个block主要由depthwise conv、SE Block和FFN三个部分组成。
其中depthwise conv可以是大卷积核(图中所示的Dilated Reparam Block,其使用膨胀卷积来辅助大核卷积来捕捉稀疏的特征而且可以通过结构重参数化方法等价转换为一个卷积层),也可以只是depthwise3x3。
多项表现超越Transformer
作为图像模态中的老三样,ImageNet、COCO、ADE20K上的结果自然是不能少。论文中最多只用ImageNet-22K预训练,没有用更大的数据。
虽然大核CNN本来不是很重视ImageNet(因为图像分类任务对表征能力和感受野的要求不高,发挥不出大kernel的潜力),但UniRepLKNet还是超过了最新的诸多模型,其实际测速的结果尤为喜人。
例如,UniRepLKNet-XL的ImageNet精度达到88%,而且实际速度是DeiT III-L的三倍。量级较小的UniRepLKNet相对于FastViT等专门设计的轻量级模型的优势也非常明显。
在COCO目标检测任务上,UniRepLKNet最强大的竞争者是InternImage:
UniRepLKNet-L在COCO上不及InternImage-L,但是UniRepLKnet-XL超过了InternImage-XL。
考虑到InternImage团队在目标检测领域的积淀非常深厚,这一效果也算很不容易了。
在ADE20K语义分割上,UniRepLKNet的优势相当显著,最高达到55.6的mIoU。与ConvNeXt-XL相比超出了整整1.6。
为了验证UniRepLKNet处理时序数据的能力,本文挑战了一个数据规模超大的《Nature》级别的任务:全球气温和风速预测。
尽管UniRepLKNet本来是为面向图像任务设计的,它却能超过为这个任务而设计的CorrFormer(前SOTA)。
这一发现尤为有趣,因为这种超大规模时间序列预测任务听起来更适合LSTM、GNN和Transformer,这次CNN却将其“偷家”了。
在音频、视频和点云任务上,本文的极简处理方法也都十分有效。
One More Thing
除了提出一种在图像上非常强力的backbone之外,本文所报告的这些发现似乎表明,大核CNN的潜力还没有得到完全开发。
即便在Transformer的理论强项——“大一统建模能力”上,大核CNN也比我们所想象的更为强大。
本文也报告了相关的证据:将kernel size从13减为11,这四个模态上的性能都发生了显著降低。
此外,作者已经放出了所有代码,并将所有模型和实验脚本开源。
论文地址:
https://arxiv.org/abs/2311.15599
美法院判AI无版权,但争议远没结束
生成式AI起势之后,版权问题一直挥之不去。日前,美国华盛顿一家法院裁定,在没有任何人类输入内容的情况下,完全由人工智能创作的艺术作品不受版权保护。这一裁定,令AI的前景蒙上一层阴影。AI的版权之争,迎来终局了吗?对AI的创作,各界为何仍有争议?AI革命之下,版权保护未来将如何演绎?版权之争,从成品走向数据这起判例,要追溯到2018年。站长网2023-09-01 18:17:240000PhotoMaker:一张照片即可生成个性化人物形象
PhotoMaker是一种新型的技术,它利用多张照片作为身份ID,获取人物特征,然后创造出一个新的、个性化的人物图像。这项技术具有多种功能,包括根据文字描述制作照片、混合多个人的特征、改变年龄或性别、添加艺术风格以及将艺术品或旧照片中的人物带入现代。项目地址:https://top.aibase.com/tool/photomaker站长网2024-01-16 10:55:500002不用排队2小时 导航去餐厅吃饭 高德地图能帮你提前取号排队了
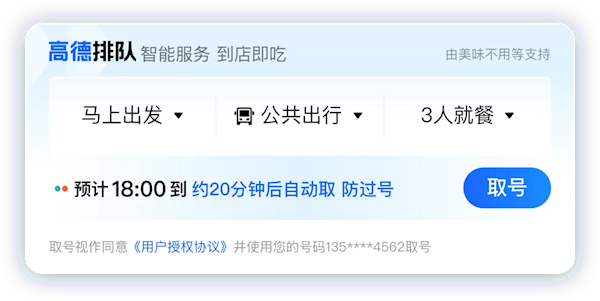
快科技7月1日消息,好不容易约上了三五好友,找到一间满意的餐厅,结果到店取号一看,前方排队40桌,预计等待时间2小时。为了避免这样的糟糕经历,高德地图上线了餐厅排队的功能。你只需打开高德地图APP,搜索想去的餐厅,进入详情页面,就能查看当前的排队预定情况。站长网2024-07-01 18:15:430002AI狂潮推动纳斯达克100指数创下自1999年以来最佳表现
**划重点:**1.🌐全球股市在人工智能狂热和美联储宽松赌注推动下接近历史高位,标志着股市在2023年迎来了一个辉煌的年份。2.💼在经历了2008年以来最严重的年度抛售后,股市在交易员加大对美联储在2024年结束升息行动并开始宽松政策的押注后,经历了今年的大逆转。0001阿里云发布通义千问2.5版 性能赶超GPT-4 Turbo
阿里云今日正式发布通义千问2.5版本,该版本在模型性能上全面赶超了GPT-4Turbo,展现了其强大的技术实力。与此同时,通义千问最新开源的1100亿参数模型Qwen1.5-110B在多个基准测评中取得了卓越成绩,超越了Meta的Llama-3-70B模型,成为开源领域的新星。站长网2024-05-09 19:41:540000