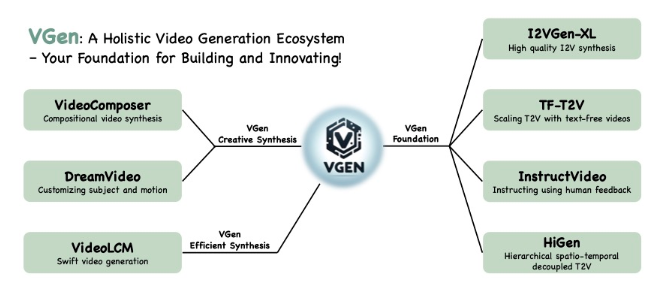
阿里团队推新AI模型I2VGen-XL:单张静止图像就能生成高质量视频
视频合成最近取得了显著的进步,这得益于扩散模型的快速发展。然而,它在语义准确性、清晰度和时空连续性方面仍然存在挑战。它们主要源于文本-视频数据的稀缺性和视频的复杂固有结构,使得模型难以同时确保语义和定性的卓越性。
阿里巴巴、浙江大学和华中科技大学的研究人员提出了一种级联的 I2VGen-XL 方法,该方法通过解耦这两个因素来增强模型性能,并通过利用静态图像作为关键指导形式来确保输入数据的对齐。
项目体验网址:https://top.aibase.com/tool/i2vgen-xl
I2VGen-XL 由两个阶段组成:
i) 基础阶段通过使用两个分层编码器来保证连贯的语义并保留输入图像中的内容。
ii) 细化阶段通过合并额外的简短文本来增强视频的细节,并将分辨率提高到1280x720。
目前文本到视频合成的主要挑战之一是高质量视频文本对的收集。为了丰富 I2VGen-XL 的多样性和鲁棒性,研究人员收集了一个庞大的数据集,其中收集了大约3500万个单镜头文本-视频对和60亿个文本-图像对来优化模型。通过这种方式,I2VGen-XL可以同时提高语义的准确性、细节的连续性和生成视频的清晰度。
所提出的模型利用潜在扩散模型(LDM),这是一种生成模型类,可以学习扩散过程来生成目标概率分布。在视频合成的情况下,LDM逐渐从高斯噪声中恢复潜在目标,保留视觉流形并重建高保真视频。I2VGen-XL采用LDM(简称VLDM)的3D UNet架构,以实现有效且高效的视频合成。
细化阶段对于增强空间细节、细化面部和身体特征以及减少局部细节中的噪声至关重要。研究人员分析了频域细化模型的工作机制,强调了其在保留低频数据和提高高清视频连续性方面的有效性。
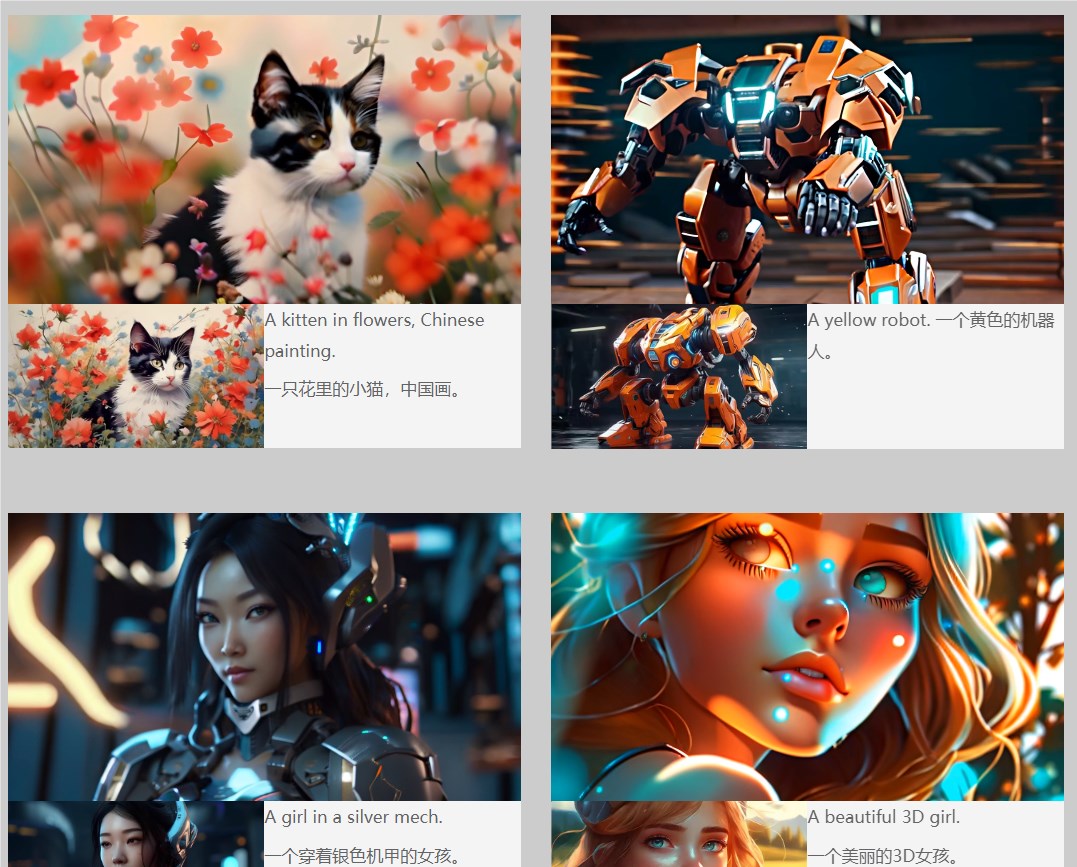
在与 Gen-2和 Pika 等顶级方法的实验比较中,I2VGen-XL 展示了更丰富、更多样化的运动,强调了其在视频生成方面的有效性。研究人员还对人脸、3D卡通、动漫、中国画、小动物等多种图像进行了定性分析,展示了该模型的泛化能力。
项目:https://i2vgen-xl.github.io/
论文网址:https://arxiv.org/abs/2311.04145
微信音频放大招:免费听周杰伦,下一步做播客
谁能想到,微信竟让数亿网友“薅”到了周杰伦的羊毛。4月20日,微信更新了iOS8.0.36版本,其中最引人关注的莫过于可以在微信免费收听QQ音乐各种付费歌曲,直接让#微信可免费听周杰伦#这一话题登上了微博热搜,截至目前阅读量超过2.2亿次。实际上,不只是音乐,微信还支持用户收听类似播客内容。此次将触角伸向音频,是其发力图文、视频、直播多个领域之后,补足自身内容板块的又一重要动作。站长网2023-04-23 09:21:500000奇安信发布奇安信大模型Q-GPT 可降低数据安全风险
8月25日,奇安信集团发布了Q-GPT(奇安信大模型)安全机器人和大模型卫士。大模型卫士集安全风险发现、大模型访问控制、数据泄露管控、违法违规行为溯源、大模型应用分析等为一体,可以帮助企业更安全地向大模型要生产力。据悉,奇安信大模型卫士可为企业在使用大模型过程中提供四重防护:第一是防止数据投喂造成的敏感数据泄露。包括建立内部技术监管手段,防止员工向大模型投喂敏感数据。站长网2023-08-26 17:01:240000蚂蚁集团、OpenAI、科大讯飞等联合编制 大模型安全国际标准发布
快科技4月17日消息,第27届联合国科技大会在瑞士日内瓦召开。世界数字技术院(WDTA)发布了一系列突破性成果,包括《生成式人工智能应用安全测试标准》和《大语言模型安全测试方法》两项国际标准。据悉,这两项国际标准是由OpenAI、蚂蚁集团、科大讯飞、谷歌、微软、英伟达、百度、腾讯等数十家单位的多名专家学者共同编制而成。其中《大语言模型安全测试方法》由蚂蚁集团牵头编制。站长网2024-04-18 17:15:150000小红书的年轻人爱上“剩菜盲盒”,他们真薅到羊毛了吗?
近期,消费市场悄然刮起一阵“剩菜盲盒”风潮。在小红书上,不少网友晒出了自己购买剩菜盲盒的感受:“19.9元竟然开出了4盒自助餐菜品,值哭了好吗”、“幸好我是深漂打工人,太快乐了”、“香港酒店剩菜盲盒,份量多到吃不完”、“长沙15.9元的自助餐盲盒,拎着感觉有一斤”。从“消费升级”到“消费降级”,年轻人试图在省钱与品质之间找寻平衡,而“剩菜盲盒”似乎成了这一诉求的完美载体。站长网2025-02-13 14:59:370000跳过安卓开屏广告App“李跳跳”宣布将无限期停更
今日凌晨,跳过安卓App开屏广告应用“大小姐李跳跳”公众号宣布,“李跳跳”APP将无限期停止更新,原因是被控涉嫌“不正当竞争”。该公众号发文称,“李跳跳”收到了来自国内互联网大厂的律师函,声称“李跳跳”可用于过滤、屏蔽该公司旗下浏览器的广告服务,并吸引用户下载、使用涉案软件,违反了《反不正当竞争法》第二条、第十二条第二款第四项的规定,构成不正当竞争。站长网2023-08-25 16:15:580000