智源研究院开源发布新一代生成式多模态基础模型 Emu2
2023年12月21日,智源研究院发布了新一代多模态基础模型 Emu2。Emu2通过大规模自回归生成式多模态预训练,显著推动了多模态上下文学习能力的突破。
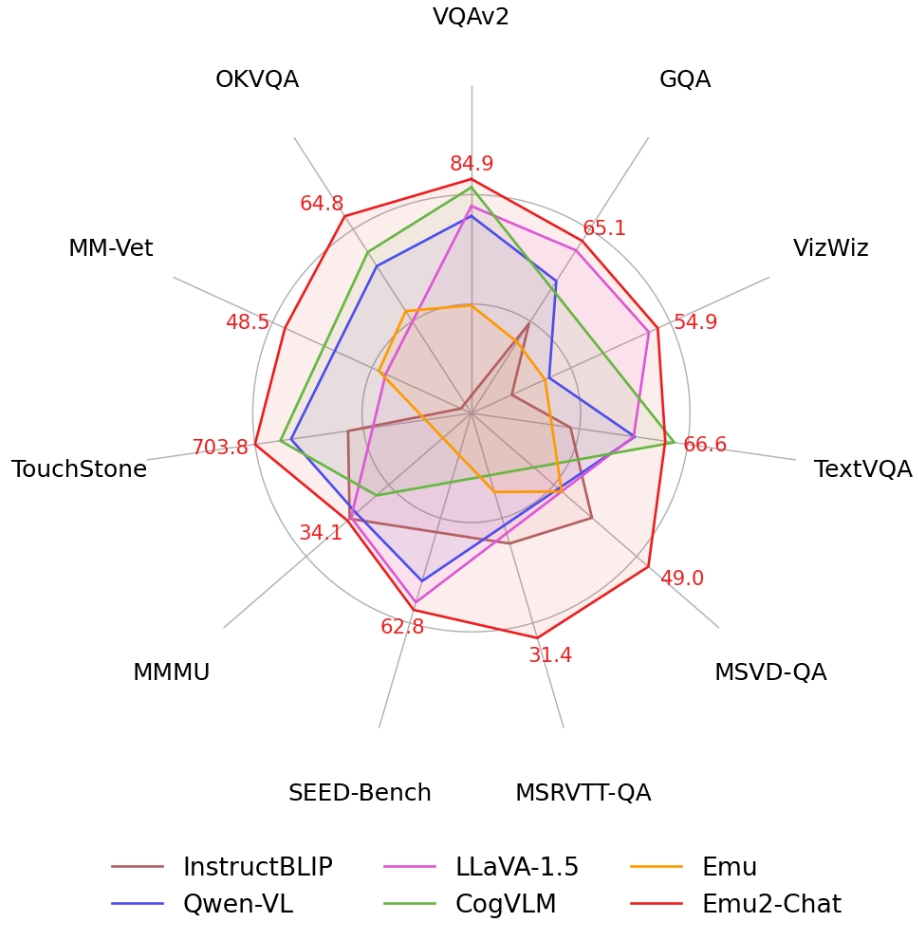
Emu2在少样本多模态理解任务上表现出色,超越了主流多模态预训练大模型 Flamingo-80B 和 IDEFICS-80B。在 VQAv2、OKVQA、MSVD、MM-Vet、TouchStone 等多个少样本理解、视觉问答、主体驱动图像生成任务上,Emu2取得了最优性能。
Emu2是目前最大的开源生成式多模态模型,基于 Emu2微调的 Emu2-Chat 和 Emu2-Gen 模型分别是目前开源的性能最强的视觉理解模型和能力最广的视觉生成模型。Emu2-Chat 可以精准理解图文指令,实现更好的信息感知、意图理解和决策规划。Emu2-Gen 可以接受图像、文本、位置交错的序列作为输入,实现灵活、可控、高质量的图像和视频生成。
Emu2使用了更简单的建模框架,并训练了从编码器语义空间重建图像的解码器,将模型规模化到37B 参数。Emu2采用大量图、文、视频的序列,建立了基于统一自回归建模的多模态预训练框架,将图像、视频等模态的 token 序列直接和文本 token 序列交错在一起输入到模型中训练。
通过对多模态理解和生成能力的评测,Emu2在少样本理解、视觉问答、主体驱动图像生成等任务上取得了最优性能。在16-shot TextVQA 等场景下,Emu2相较于 Flamingo-80B 超过12.7个点。在 DreamBench 主体驱动图像生成测试上,Emu2比之前的方法取得了显著提升。
Emu2具备全面且强大的多模态上下文学习能力,可以照猫画虎地完成多种理解和生成任务。Emu2-Chat 经过对话数据指令微调,可以精准理解图文指令,完成多模态理解任务。Emu2-Gen 可以接受任意 prompt 序列作为输入,生成高质量的图像和视频。
Emu2的训练方法是在多模态序列中进行生成式预训练,使用统一的自回归建模方式。相比于 Emu1,Emu2采用了更简单的建模框架,训练了更好的解码器,并将模型规模化到37B 参数。
项目:https://baaivision.github.io/emu2/
模型:https://huggingface.co/BAAI/Emu2
代码:https://github.com/baaivision/Emu/Emu2
Demo:https://huggingface.co/spaces/BAAI/Emu2
论文:https://arxiv.org/abs/2312.13286
AI 虚拟代理将取代搜索引擎 专家:到2026年搜索量将下降25%
据权威机构Gartner公司预测,到2026年,传统搜索引擎的数量将会下降25%,而AI聊天机器人和其他虚拟代理将夺走搜索营销的市场份额。Gartner公司的副总裁分析师AlanAntin指出,自然搜索和付费搜索一直是技术营销人员重要的渠道,但随着生成式人工智能(GenAI)解决方案的崛起,这一局面即将发生改变。站长网2024-02-20 10:03:090000谷歌暂停AI图像生成功能:承认存在技术缺陷
谷歌周五承认,其人工智能工具Gemini在生成历史人物图像时出现错误,导致图像显示出明显的种族偏差。本周早些时候,媒体发现Gemini生成了不同种族的纳粹分子和美国开国元勋的图像。例如,当提示生成“1800年代美国参议员”的图像时,Gemini生成了一名黑人男性。站长网2024-02-24 10:04:300000Neuralink脑机接口实验因受试者健康问题暂停,替代候选人待定
站长之家(ChinaZ.com)6月29日消息:在脑机接口技术领域引起广泛关注的Neuralink公司,由埃隆·马斯克创立,原计划于上周一进行其设备在第二名受试者体内的植入手术。然而,美国巴罗神经病学研究所首席执行官迈克尔·劳顿近日透露,由于受试者的健康状况,这一手术已被紧急叫停。图源备注:图片由AI生成,图片授权服务商Midjourney站长网2024-06-29 16:22:470000人工智能“淘金热”提振硅谷
本文要点:1.生成式AI的兴起为美国带来大量风投资金,今年已达146亿美元,远超过过去两年总和。2.专家认为生成式AI是1995年以来最具变革性的技术趋势。3.AI公司重新获得投资人青睐,扭转了今年早些时候整体风投放缓的局面。近期,商业界和科技界对生成式AI的兴趣激增,让硅谷的创业公司与行业巨头重新焕发活力,争相站在技术创新的最前沿。站长网2023-08-29 16:40:220000Cortana在Windows 11上谢幕,“死”于生成式 AI 之手的第一款语音助手
曾几何时,语音助手成为手机、电脑等智能设备上必备的功能之一,一时间之间,苹果的Siri、微软的Cortana(小娜)、Google的Assistant、三星的Bixby、小米的小爱、华为的Ceila等层出不穷。站长网2023-08-04 18:02:210000













