苹果最新研究:将有限内存推理速度提高25倍
站长网2023-12-21 11:04:570阅
近年来,大型语言模型(LLMs)在自然语言处理任务中表现卓越,但其对计算和内存的高需求对于内存有限的设备构成了挑战。
本文提出了一种在设备内存有限的情况下,通过将模型参数存储在闪存中,并在推断时按需将其加载到DRAM,实现了高效运行LLMs的方法。
论文地址:https://arxiv.org/pdf/2312.11514.pdf
方法包括构建与闪存内存行为协调的推断成本模型,通过减少从闪存传输的数据量和以更大、更连续的块读取数据的方式进行优化。
在这个框架内,引入了两种关键技术:窗口化策略通过重用先前激活的神经元来减少数据传输,行列捆绑技术通过适应闪存的顺序数据访问增加了从闪存读取的数据块的大小。
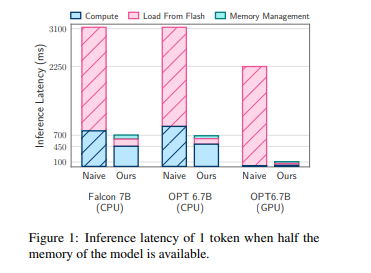
这两种方法使得能够运行比可用DRAM容量大两倍的模型,相较于朴素加载方法,CPU和GPU的推断速度分别提高了4-5倍和20-25倍。同时,结合稀疏感知、上下文自适应加载和硬件导向设计,为在内存有限的设备上进行LLMs推断打开了新的可能性。
0000
评论列表
共(0)条相关推荐
资源整合串联MCN机构,百度百家号总有新玩法
随着内容平台的加速反战,用户对于内容质量的要求越来越高,平台之间的竞争也愈发激烈。如今,各平台既要盘活已有的优质创作者,又要扶持新的有生力量,以丰富平台内容生态。2023年,快手选择在内容和变现上,对创作者进行扶持。抖音则在作者页开放广告位,以帮助创作者变现。小红书、网易号、视频号、百度百家号等平台也相继推出扶持计划,帮助站内创作者发展与进步。站长网2023-10-31 18:12:490004欧盟对微软捆绑 Teams 展开反垄断调查,或面临巨额罚款
据报道,欧盟监管机构已经开始对微软将视频和聊天应用Teams与其他Office应用捆绑的行为展开反垄断调查。欧盟委员会担心这种捆绑行为可能构成垄断,并限制了其他竞争对手在办公通讯和视频应用领域的发展。具体而言,欧盟监管机构对微软的做法表示担忧,指出微软没有给用户选择不包含Teams的权利,可能阻碍了其他公司的竞争。微软365,即前身为Office365的产品,包括了一系列办公应用。站长网2023-07-28 10:09:270000AMD、Intel业绩暴雷 NVIDIA成了全村的希望:AI关键一战
快科技5月3日消息,PC、数据中心市场的需求下滑已经让科技巨头面临巨大的业绩压力,Intel、AMD这几天都发布了财报,一个营收下滑36%,一个营收下滑9%,都是近年来罕见的情况。谁能在整个业界都不太好的情况下力挽狂澜?现在全村的希望都放在NVIDIA身上了,该公司预计在5月24日发布上季度财报。站长网2023-05-03 09:15:420000微软测试新版画图工具,增加一键去除背景AI功能
文章概要:1.微软正在测试新版画图工具,该工具允许用户一键去除图像背景。2.新功能已推出给WindowsInsiders,Canary和DevChannels可体验。3.这一改进将使画图工具更加实用,减少了用户使用第三方应用的需要。站长网2023-09-08 12:07:080000Repilot开源:自动程序修复的高效补丁生成工具
Repilot是一款旨在提高程序修复效率的工具,它结合了语义导向的代码补全引擎和大型语言模型,能够自动生成有效的程序补丁。Repilot的核心功能包括错误修复、智能代码补全、与大型语言模型的集成、Docker支持以及详细的文档支持。如果您是开发人员或软件维护者,Repilot可能会成为您提高工作效率的得力助手。站长网2023-09-19 11:35:320000