阿里文生视频挑战Gen-2、Pika,1280×720分辨率无压力,3500万文本-视频对显奇效
图源备注:图片由AI生成,图片授权服务商Midjourney
文生视频领域又卷起来了!
文生视频可以精细到什么程度?最近,阿里巴巴的一项研究给出了答案:1280×720分辨率没有压力,而且生成效果非常连贯。
这些 demo 来自阿里联合浙江大学、华中科技大学提出的文生视频模型 I2VGen-XL,该模型能够生成各种类别的高质量视频,如艺术画、人像、动物、科幻图等。生成的视频具有高清、高分辨率、平滑、美观等优点,适合广泛的视频内容创作任务。在与 Gen2、Pika 生成效果对比上, I2VGen-XL 生成的视频动作更加丰富,主要表现在更真实、更多样的动作,而 Gen-2和 Pika 生成的视频似乎更接近静态。
除了生成效果,这项工作更令人印象深刻的一点是研究人员在数据上下的工夫。为了提高生成效果的多样性,研究人员收集了大约3500万单镜头文本 - 视频对和60亿文本 - 图像对来优化模型,这是一个非常庞大的数据集,其后续潜力令人期待。
论文细节
论文地址:https://arxiv.org/pdf/2311.04145.pdf
论文主页:https://i2vgen-xl.github.io/page04.html
该研究表示得益于扩散模型的快速发展,视频合成最近取得了显著的进步。然而,它在语义的准确性、清晰度和时空连续性方面仍然面临挑战。
出现这种状况的原因一方面是由于缺乏良好的经过对齐的文本 - 视频数据,另一方面在于视频本身复杂的内在结构,使得模型难以同时保证语义和质量的卓越性。
为了解决上述问题,研究者受到 SDXL 方法的启发,提出了一种级联的 I2VGen-XL 方法,其能够生成具有连贯空间和运动动态化以及细节连续的高清视频。
I2VGen-XL 旨在从静态图像生成高质量视频。因此,它需要实现两个关键目标:语义一致性,即准确预测图像中的意图,然后在保持输入图像的内容和结构的同时生成精确的运动;高时空一致性和清晰度,这是视频的基本属性,对于确保视频创作应用的潜力至关重要。为此,I2VGenXL 通过由两个阶段组成的级联策略分解这两个目标:基础阶段和改进阶段。
基础阶段旨在保证低分辨率下生成视频的语义连贯,同时还要保留输入图像的内容和主体信息。为了达到这一目标,研究者设计了两个分层编码器,即固定 CLIP 编码器和可学习内容编码器,分别提取高级语义和低级细节,然后将其合并到视频扩散模型中。
改进阶段:将视频分辨率提高到1280×720,并改进生成视频中存在的细节和伪影。具体来说,研究者使用简单的文本作为输入来训练一个独特的视频扩散模型,并优化了其初始的600个去噪 step。通过使用噪声去噪过程,该研究实现了从低分辨率视频生成具有时间和空间一致性的高清视频。
具体而言:
基础阶段。基于 VLDM,本文设计的第一阶段是低分辨率(即448×256),主要侧重于在输入图像上结合多级特征提取,包括高级语义和低级细节学习。
高级语义学习。该研究表示用 CLIP 的视觉编码器来提取语义特征,这种方法可以学习高级语义,但忽略了图像中精细细节的感知。为了缓解这个问题,本文结合了一个额外的可训练全局编码器来学习具有相同形状的互补特征,其架构如表1所示。
低级细节。为了减少细节的损失,本文采用从 VQGAN 编码器(即 D.Enc.)提取的特征,并将它们直接添加到第一帧的输入噪声中。
改进阶段。经过基础阶段可以获得具有多样化且语义准确的运动的低分辨率视频。然而,这些视频可能会遇到各种问题,例如噪声、时间和空间抖动以及变形。因此,改进模型有两个主要目标:i)增强视频分辨率,将其从448×256增加到1280×720或更高;ii) 提高视频的时空连续性和清晰度,解决时间和空间上的伪影问题。
为了提高视频质量,该研究训练了一个单独的 VLDM,专门处理高质量、高分辨率数据,并对第一阶段生成的视频采用 SDEdit 引入的噪声去噪过程。
该研究还使用 CLIP 对文本进行编码,并通过交叉注意力将其嵌入到3D UNet 中。然后,基于基础阶段的预训练模型,研究者使用精心挑选的高质量视频训练高分辨率模型,所有视频的分辨率都大于1280×720。
此外,该研究还收集了3500万个高质量 single-shot 视频和60亿张图像,以达到增强 I2VGen-XL 多样性和稳健性的目的。
最后,广泛的实验评估结果表明 I2VGen-XL 可以同时增强生成视频的语义准确性、细节的连续性和清晰度。此外,该研究还将 I2VGenXL 与当前的顶级方法进行了比较,结果都表明 I2VGenXL 在各种数据上的有效性。
实验结果
与 Gen2和 Pika 的比较结果
为了证明新方法的有效性,研究者将 I2VGen-XL 的性能与 Gen-2和 Pika 进行了比较,二者被公认为是目前文生视频领域最先进的方法。如图4所示,作者使用这两种方法的网页界面生成了三种类型图像的视频,包括虚拟、写实和抽象绘画。
从这些结果中可以得出以下个结论:i) 动作的丰富性:I2VGen-XL 的结果显示出更真实、更多样的动作,例如最上方的例子。相比之下,Gen-2和 Pika 生成的视频似乎更接近静态,这表明 I2VGen-XL 实现了更丰富的运动;ii) ID 保留程度:从这三个样本中可以看出,Gen-2和 Pika 成功地保留了物体的身份特征,而 I2VGen-XL 则丢失了输入图像的一些细节。在实验中,作者还发现 ID 保留程度和运动强度之间存在一定的权衡关系。I2VGen-XL 在这两个因素之间取得了平衡。
改进模型分析
图3展示了改进阶段前后生成的视频。这些结果表明,空间细节得到了大幅提升,包括面部和身体特征的细化,以及局部细节中噪音的明显减少。
为了进一步阐明改进模型的工作机制,本文在图7的频域中分析了在此过程中生成的视频中发生的空间和时间变化。图7a 显示了四个空间输入的频谱,表明:低质量视频表现出与高频范围内的噪声相似的频率分布,而高质量视频表现出与输入图像的频率分布更相似。将其与图7b 所示的空间频率分布相结合,可以观察到改进模型有效地保留了低频数据,同时在高频数据中表现出更平滑的变化。从时间维度的角度来看,图7d 呈现了低质量视频(上)和高质量视频(下)的时间曲线,表明高清视频的连续性有了明显的改善。此外,结合图7b 和图7e 可以看出,改进模型在空间和时间域中保留了低频分量,减少了中频分量,并增强了高频分量。这表明时空域中的伪影主要存在于中频范围。
定性分析
该研究还对更广泛的图像进行了实验,包括人脸、3D 卡通、动漫、国画、小动物等类别。结果如图5所示,图中可以观察到生成的视频考虑了图像的内容和合成视频的美感,同时还表现出有意义且准确的动作。例如,在第六行,模型准确地捕捉到了小猫可爱的嘴巴动作。这些结果表明 I2VGen-XL 表现出有前途的泛化能力。
生成稳定的人体运动仍然是视频合成的主要挑战。因此,该研究还专门验证了 I2VGen-XL 在人体图像上的稳健性,如图8所示。可以观察到,该模型对人体的预测和生成的运动相当真实,具有人体的大部分特征。
文本 - 视频
文本到视频合成目前面临的主要挑战之一是高质量视频 - 文本对的收集,这使得与图像合成相比,实现视频和文本之间的语义对齐更加困难。因此,将 Stable Diffusion 等图像合成技术与图像到视频合成相结合,有助于提高生成视频的质量。事实上,为了尊重隐私,该研究几乎所有样本都是由两者结合生成的。另外,在图6中是本文单独生成的样本,可以观察到视频和文本表现出很高的语义一致性。
中国信通院:编制纸鸢开放人工智能模型许可证,促大模型落地
据报道,中国信息通信研究院联合产业各方共同编制“纸鸢”开放人工智能模型许可证,旨在为共同打造具有变革意义的大模型开源项目奠定坚实基础。中国信通院云大所开源和软件安全部主任郭雪表示,为充分发挥大型模型的通用性优势,促进大型模型技术在产业中真正落地,中国信息通信研究院联合产业各方共同编制“纸鸢”开放人工智能模型许可证,下一步将发布《纸鸢开放人工智能模型许可证(征求意见稿)》。站长网2023-05-30 15:47:090000商汤科技推出“商汤日日新”生成式大模型
商汤科技宣布推出大模型体系“商汤日日新大模型”,包括自然语言生成、文生图、感知模型标注、以及模型研发功能。此外,商汤科技还宣布推出了商汤自研中文语言大模型应用平台“商量”。今年3月,商汤科技还发布了多模态多任务通用大模型“书生(INTERN)2.5”。站长网2023-04-12 12:30:050002获赞百万、轻松变现?AI短视频是“风口”还是“骗局”
用AI做短视频获赞百万、涨粉几十万,门槛低还轻松变现?AI热潮之下,短视频平台上出现了许多用AI制作的账号:用Deepseek写文案,用即梦做图、生成视频,再用剪辑软件进行编辑。尤其是今年以来、利用AI生成古人形象、配上养生内容的“AI养生”十分火热。然而,这类账号真的那么容易上手吗?普通人到底能不能赚到钱?或许,比起“挖矿”的,行动更快的是“卖铲子”的人。AI做短视频获赞百万0000荣耀首款AI PC!荣耀MagicBook Pro 16正式发布
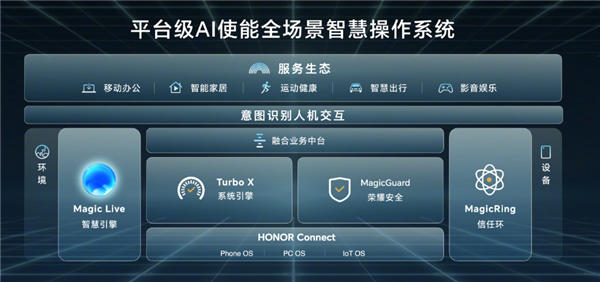
快科技3月18日消息,今晚荣耀召开春季旗舰新品发布会,正式发布了荣耀首款AIPC荣耀MagicBookPro16,售价稍后公布。荣耀MagicBookPro16搭载了MagicLive智慧引擎,支持AI智慧搜索功能,可实现文档内容精准搜索,并行业首次实现了图片内容精准搜索。站长网2024-03-19 06:58:260000李书福为宗庆后写吊唁信:浙商的优秀代表
站长之家(ChinaZ.com)2月26日消息:得知宗庆后先生逝世的消息后,众多业界企业家纷纷发文悼念,其中包括阿里巴巴的马云、小米的雷军等。作为同为浙江的企业家,吉利汽车的创始人兼董事长李书福更是亲笔撰写了一篇深情的怀念文章。站长网2024-02-26 14:26:000000