突破性AI方法WHAM:精确有效地预测视频中3D人体运动
**划重点:**
1. 🌐 WHAM(World-grounded Humans with Accurate Motion)方法成功结合3D人体运动和视频背景,实现精准的全球坐标下3D人体运动重建。
2. 💡 该方法通过模型自由和基于模型的方法,利用深度学习技术,有效地从单眼视频中准确估计3D人体姿态和形状。
3. 🚀 WHAM在全球坐标系下取得了令人瞩目的成果,通过融合运动上下文和足地接触信息,最小化足滑动,提高国际协调性。
在最新的研究中,卡内基梅隆大学(CMU)和马克斯·普朗克智能系统研究所的研究人员共同发布了一项名为WHAM(World-grounded Humans with Accurate Motion)的创新性AI方法。这一方法在精准性和效率方面实现了从视频中准确估计3D人体运动的突破。
3D人体运动重建是一个复杂的过程,涉及准确捕捉和建模人体在三维空间中的运动。当处理由移动摄像机在现实世界环境中拍摄的视频时,这一任务变得更加具有挑战性,因为这些视频通常包含脚滑等问题。然而,CMU和马克斯·普朗克智能系统研究所的研究人员通过WHAM方法成功解决了这些挑战,实现了精准的3D人体运动重建。
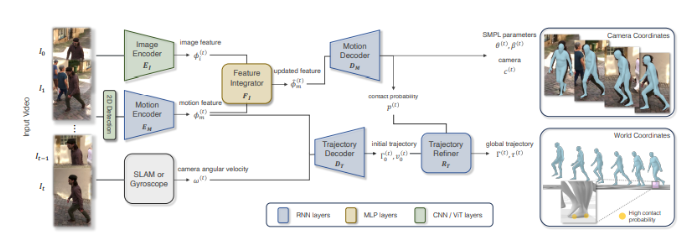
从图像中恢复3D人体姿势和形状的两种方法:无模型和基于模型。它强调了在基于模型的方法中使用深度学习技术来估计统计身体模型的参数。现有的基于视频的3D人体姿势估计方法通过各种神经网络体系结构引入时间信息。一些方法使用额外的传感器,如惯性传感器,但它们可能会产生侵扰。WHAM通过有效地结合3D人体运动和视频上下文,利用先验知识,并在全球坐标系中准确重建3D人体活动而脱颖而出。

该研究解决了从单眼视频中准确估计3D人体姿势和形状的挑战,强调了全球坐标一致性、计算效率和真实足地接触。利用AMASS运动捕捉和视频数据集,WHAM结合了运动编码器-解码器网络,用于将2D关键点转换为3D姿势,具有用于时间线索的特征整合器,以及用于全局运动估计考虑足地接触的轨迹细化网络,提高了在非平面表面上的准确性。
WHAM采用单向RNN进行在线推断和精确的3D运动重建,具有用于上下文提取的运动编码器和用于SMPL参数、相机平移和足地接触概率的运动解码器。利用边界框归一化技术有助于运动上下文的提取。在人体网格恢复的预训练图像编码器通过特征整合器网络捕捉和整合图像特征与运动特征。轨迹解码器预测全局方向,而细化过程最小化足滑动。在合成AMASS数据上进行训练,WHAM在评估中优于现有方法。

WHAM超越了当前的最先进方法,在逐帧和基于视频的3D人体姿势和形状估计中表现出卓越的准确性。通过利用运动上下文和足地接触信息实现了精确的全球轨迹估计,最小化了足滑动,并提高了国际协调性。该方法整合了2D关键点和像素的特征,提高了3D人体运动重建的准确性。在野外基准测试中,WHAM在MPJPE、PA-MPJPE和PVE等指标上展现出卓越的性能。轨迹细化技术进一步提升了全局轨迹估计,并通过改善的误差指标证明了减少足滑动的效果。
总的来说,这项研究的主要观点可以总结为以下几点:
1. WHAM引入了一种结合3D人体运动和视频背景的开创性方法。
2. 该技术增强了3D人体姿势和形状的回归。
3. 该方法使用了一个全球轨迹估计框架,包括运动上下文和足地接触。
4. 该方法解决了足滑动的问题,并确保在非平面表面上准确跟踪3D运动。
5. WHAM的方法在包括3DPW、RICH和EMDB在内的多样化基准数据集上表现出色。
6. 该方法在全球坐标系中实现了高效的人体姿势和形状估计。
7. 该方法的特征整合和轨迹细化显著提高了运动和全局轨迹的准确性。
8. 通过深入的剖析研究,验证了该方法的准确性。
论文网址:https://arxiv.org/abs/2312.07531
项目网址:https://wham.is.tue.mpg.de/
重启与OpenAI的谈判,苹果为iOS 18的AI找“备胎”
如果说在AI大模型崭露头角的2023年,苹果方面的做法是观望,那么到了2024年,他们显然已经不再认为这一轮人工智能浪潮是“AI炒作”(AIhype)了。继此前300亿参数规模的MM1模型亮相后,苹果又在不久前在AI开源社区HuggingFace放出了自研的开源“小模型”OpenELM。站长网2024-05-04 12:36:240000微软发布声音克隆技术Personal Voice 提供1分钟样本即可生成AI语音
微软近日发布了一项名为PersonalVoice的新技术,该技术可以克隆用户的声音,并且能够复制出与原声音完全一致的人工智能语音。用户只需提供1分钟的语音样本,PersonalVoice就能在几秒钟内生成相应的AI语音。站长网2023-11-17 11:17:140002StyleMamba:一种高效的文本驱动图像风格转换的ai模型
划重点:⭐StyleMamba是一种用于文本驱动图像风格转移的有效框架,使用文本提示来指导风格化过,同时保持原始图像内容。⭐️该研究团队提出了两种独特的损失函数,二阶方向损和掩码损失,以确保图像与文本提示之间的局部和全局风格一致性。⭐️StyleMamba的效果经过多项测试和定性分析确认,优于当前基线方法的性能。站长网2024-05-11 18:13:410000高斯绘画工具开源 可用于艺术创作和机器学习研究
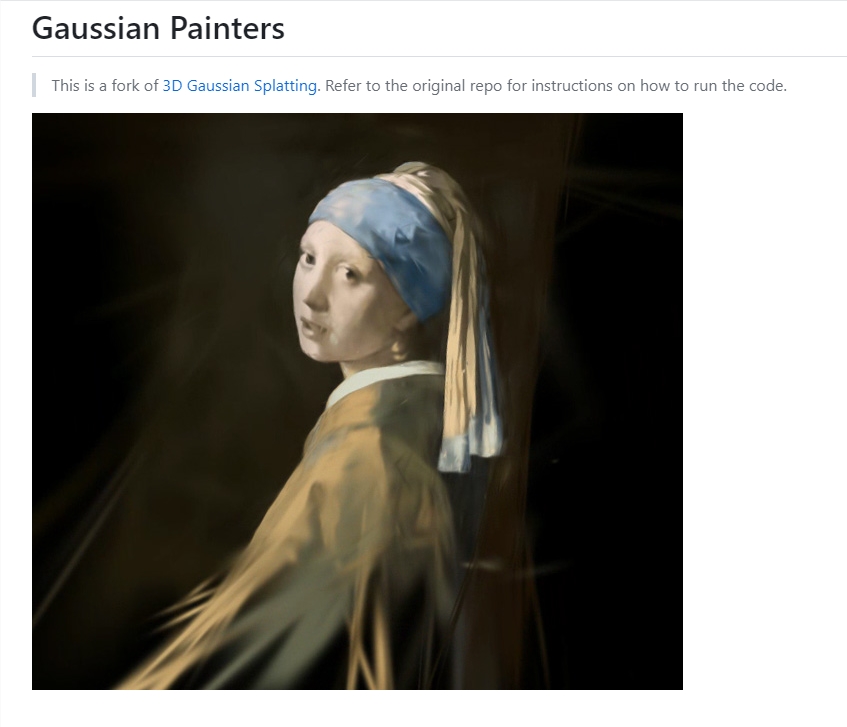
高斯绘画器是一个使用三维高斯斑点绘制图像的框架。它基于高斯斑点渲染技术,可以以非常逼真的方式渲染和重建图像。该项目提供了一个使用Python编写的开源实现,可以用于艺术创作和机器学习研究。项目地址:https://github.com/ReshotAI/gaussian-painters站长网2023-09-05 10:38:080000谷歌 DeepMind 首席执行官:人工智能风险类似于气候危机,世界不能拖延应对
站长网2023-10-25 09:12:210000