AI视野:谷歌Gemini Pro开放;文心一言插件商城上线;谷歌图像生成模型Imagen2发布;阿里推虚拟试穿技术Outfit Anyone
📰🤖📢AI新鲜事
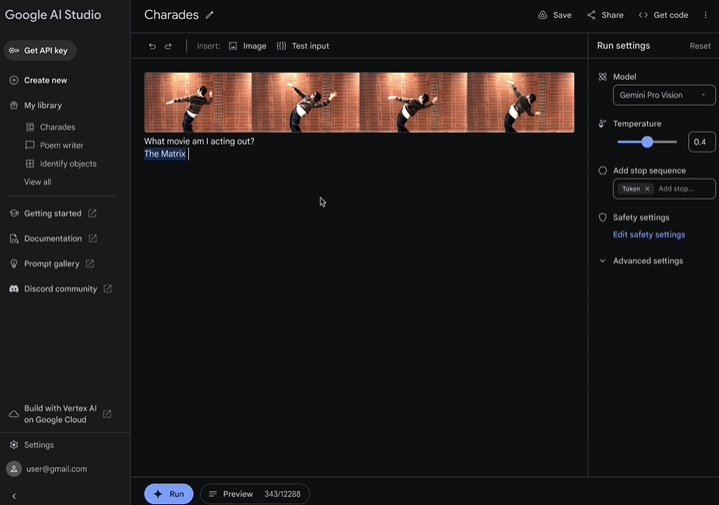
谷歌Gemini Pro开放
谷歌Gemini Pro大模型在研究基准测试中表现优异,支持32K上下文窗口的文本输入和生成功能,向Vertex AI云计算客户和AI Studio开发人员开放,提供多种功能和SDK,为构建AI应用程序提供更多可能性。
【AiBase提要:】
🚀 Gemini Pro性能卓越: 在研究基准测试中,Gemini Pro展现出强大性能,支持32K上下文窗口的文本输入和生成功能,同时支持38种语言。
🌐 多平台支持: Gemini Pro提供Python、Android、Node.js、Swift和JavaScript等多种SDK,帮助开发者在不同平台上构建应用程序。
🔐 全面托管解决方案: 用户可以从免费的Google AI Studio轻松转移到Vertex AI,获得完全的数据控制和其他Google Cloud功能,包括安全性、隐私和数据治理。
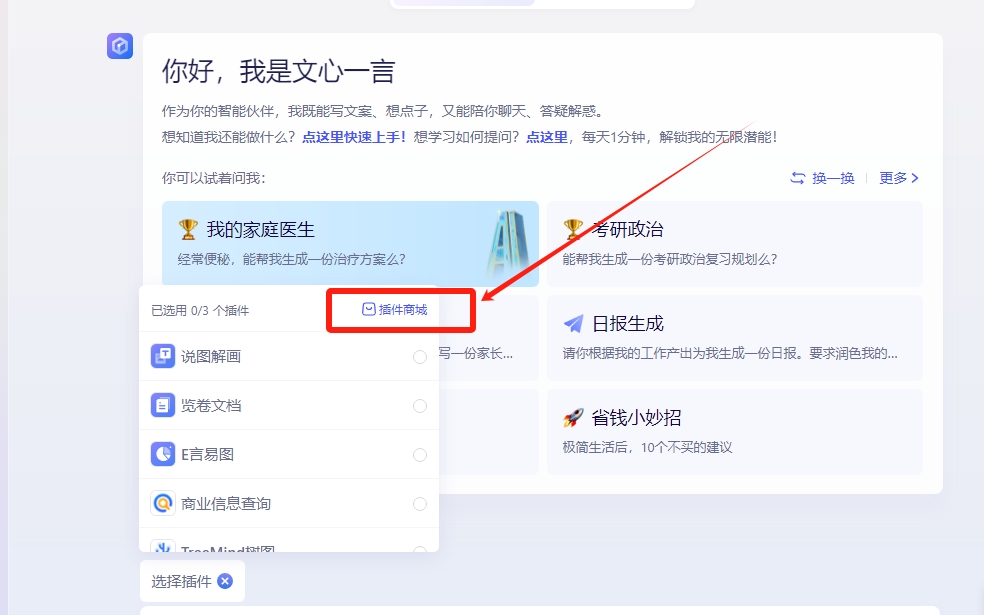
文心一言插件商城上线
百度文心一言插件商城正式上线,提供多功能插件,包括PPT生成、音视频提取、思维导图等,用户可通过简单指令满足多场景需求。插件商城还支持用户自主设计新插件。
【AiBase提要:】
🚀 实用插件覆盖多场景: 百度文心一言插件商城涵盖PPT生成、音视频提取、思维导图等实用场景,提升用户办公效率。
🎨 支持自主设计插件: 用户不仅可使用插件,还能成为设计师,在插件商城设计全新应用,拓展创意空间。
👩💼 多功能插件一键安装: 用户通过简单指令即可安装插件,满足多场景多模态需求,如视频助理、项目管理看板等。
ChatGPT成为Nature年度十大人物
2023年,《自然》杂志评选出年度十大人物,其中包括ChatGPT和OpenAI首席科学家苏茨克维,成为榜单首位非人类入选者,突显人工智能在科学界的引领地位。
【AiBase提要】
🌐 ChatGPT破例入选: 《自然》十大人物榜单首次包含ChatGPT,承认生成式人工智能对科学研究的重大改变。
🚀 人工智能引领科学: OpenAI首席科学家苏茨克维的入选突显人工智能在科学研究中的关键作用。
🌍 多领域卓越成就: 榜单涵盖卫生、环境、物理学等领域,凸显科技创新对全球社会的深远影响。
全国首例AI声音侵权案公开审理
北京互联网法院审理全国首例AI声音侵权案公开审理,配音演员起诉魔音工坊APP和微软等五被告。配音演员以原告声音未经授权被AI化并在APP上售卖为由,将魔音工坊等五家公司诉至北京互联网法院,案件仍在审理中。
【AiBase提要】:
🗣️ 声音侵权指控: 配音演员原告称其声音被AI化后在“魔音工坊”APP上以别名售卖,侵害其声音权。
🤖 被告辩诉: 被告公司否认侵权,称声音产品来源合法,微软声音来自中广影音,不构成侵权。
⚖️ 审理进程: 原告主张人格权侵权,不认可涉及著作权,案件目前在进一步审理中。
iQOO Neo9系列首批搭载自研AI蓝心大模型
iQOO Neo9系列手机将首次搭载自研AI蓝心大模型,在语言理解、文本创作等领域表现卓越,为用户带来更智慧、流畅、安全的体验。
【AiBase提要】:
🔍 技术亮点: iQOO Neo9系列引入自研AI蓝心大模型,在语言理解和文本创作方面表现优秀,位列中文大模型榜单首位。
🚀 强悍性能: 手机采用超越Pro级全能生态,搭载高性能处理器,Pro版本跑分突破233万分,刷新记录。
🎮 游戏体验提升: 配备独立显示芯片,为玩家带来更出色的游戏体验,提升流畅性和稳定性。
AI主播 Channel1上线
近期热播剧《新闻女王》引发关注,与此同时,美国新闻初创公司Channel1发布了能24/7不间断播报新闻的AI主播,引发新闻界热议。
【AiBase提要:】
🤖 AI主播代替人类主播,Channel1公司推出的复杂模型支持逼真主播形象,可播报多语种新闻。
🌐 该公司强调新闻源来自独立记者、政府文件和外部机构,保证内容真实性,但仍有争议。
💼 Channel1与传统新闻频道不同,采取个性化、消费者选择的制作方式,拟以低成本在2024年上线。
邢波团队提出全开源倡议LLM360
邢波团队提出LLM360全面开源倡议,旨在使大型语言模型训练过程透明,发布两个大型语言模型,并为研究者提供开发经验和性能评估结果。
论文地址:https://arxiv.org/pdf/2312.06550.pdf
项目网页:https://www.llm360.ai/
【AiBase提要:】
🌐 全面开源倡议: 邢波团队的LLM360框架涵盖训练数据、代码、模型检查点和性能指标,为大型语言模型建立全方位的透明标准。
🚀 发布大型语言模型: 框架下发布的AMBER和CRYSTALCODER是基于1.3T和1.4T token的大型语言模型,提供了性能评估和LLM领域的实质经验。
🤝 推动开放合作研究: LLM360的全面开源趋势有望促进更多研究者参与合作,推动人工智能领域的不断创新与进步。
🤖📈💻💡大模型动态
谷歌Deepmind发布最先进的图像生成模型Imagen2
谷歌Deepmind推出Imagen2,一款强大的图像生成模型,通过参考图片和文本生成新图片和局部编辑,具有改进的图像描述理解和支持图像编辑功能。模型在安全性方面采用了数字水印工具SynthID,可在不损害图像质量的情况下防止潜在的风险。

地址:https://deepmind.google/technologies/imagen-2/
【AiBase提要:】
🌟 强大生成功能: Imagen2通过参考图片和文本生成新图片和局部编辑,具有改进的图像描述理解,提高生成图像质量。
🔒 数字水印防护: 模型集成了SynthID数字水印工具,可在不损害图像质量的情况下防止潜在的风险和不良内容。
🎨 灵活的风格控制: Imagen2的扩散技术提供高度灵活性,可通过参考风格图像和文本提示训练模型生成符合相同风格的新图像。
Stability.ai开源图片生3D模型Stable Zero123
Stability.ai在官网开源了基于丰田研究院和哥伦比亚大学联合开源的Zero123模型的优化版本Stable Zero123,通过改进渲染数据集和分数蒸馏,提升了3D模型生成效果和训练效率,可与SDXL高精准图片模型结合使用。
项目地址:https://github.com/cvlab-columbia/zero123
【AiBase提要:】
💡 Stable Zero123是Stability.ai对Zero123模型的优化版本,通过改进渲染数据集和分数蒸馏,提升了3D模型生成效果和训练效率。
🔄 与最新开源的SDXL高精准图片模型结合使用,相当于3D模型的扩展插件,拓展了生成式AI的应用领域。
🌐 通过使用高质量数据集Objaverse-XL,Stable Zero123在生成过程中更好地理解和生成3D模型,为研究提供强大的工具。
全国首个古籍大语言模型“荀子”发布
南京农业大学研发的“荀子”古籍大语言模型整合了超过20亿字的古籍语料库,旨在推动古籍研究和保护,提高中华传统文化传承效率,实现大语言模型与古籍处理深度融合。
地址:https://github.com/Xunzi-LLM-of-Chinese-classics/XunziALLM/blob/main/README.md
【AiBase提要:】
📚 全面整合语料库: “荀子”大语言模型包含超过20亿字的传世古籍文献,以推动古籍研究和传承为宗旨。
💻 多功能应用场景: 模型提供智能标引、翻译、诗歌生成、阅读理解等功能,显著提高古籍处理和研究效率。
👩🏫 专家高度评价: 在发布会上,多家高校、出版机构和互联网企业的专家学者高度评价了该模型的实用性。
魔搭社区上线Mistral AI 首个开源 MoE 模型
Mistral AI最近在魔搭社区上线了首个开源MoE模型Mixtral8x7B,这是一个由8个专家网络组成的混合专家模型,拥有70亿参数,支持32k token上下文长度,在MT-Bench评测上达到了8.3分,与GPT3.5相当。
【AiBase提要:】
🚀 模型介绍: Mistral AI发布开源MoE模型Mixtral8x7B,由8个专家网络组成,拥有70亿参数,支持32k token上下文长度。
📈 性能评估: 在MT-Bench评测上,Mixtral8x7B达到8.3分,与GPT3.5相当,展现出卓越的性能。
🌐 社区上线: Mixtral8x7B模型正式在魔搭社区上线,为开发者提供了一个交流、分享的平台。
Mixtral-8x7B-v0.1模型:
https://www.modelscope.cn/models/AI-ModelScope/Mixtral-8x7B-v0.1/summary
Mixtral-8x7B-Instruct-v0.1模型:
https://www.modelscope.cn/models/AI-ModelScope/Mixtral-8x7B-Instruct-v0.1/summary
Mistral-7B-Instruct-v0.2新模型:
https://www.modelscope.cn/models/AI-ModelScope/Mistral-7B-Instruct-v0.2/summary
🤖📱💼AI应用
美图上线AI绘画与图片生成应用WHEE App
美图旗下WHEE移动端App正式上线,由MiracleVision4.0大模型提供支持,为用户提供一站式AI视觉创作服务,包括AI绘画、图片生成、修图、扩图、3D效果等功能,并汇集各领域创作者作品,促进创作者交流与合作。
【AiBase提要:】
🎨 全方位创作服务: WHEE App整合MiracleVision4.0大模型,提供AI绘画、图片生成等全方位创作服务,用户只需用自然语言描述需求即可轻松上手使用。
🤝 创作者交流平台: 应用内汇集各领域创作者的作品,为创作提供灵感来源,同时促进创作者之间的交流与合作。
📚 用户支持与指导: 提供创作指南和模型训练指南,帮助用户更好地使用和理解应用程序。
谷歌推出AI音乐创作工具“MusicFX”
谷歌推出的AI音乐创作工具“MusicFX”利用Google的MusicLM和DeepMind的SynthID技术,让用户通过几句话即可生成原创音乐,同时强调负责任的AI创新。
体验网址:https://top.aibase.com/tool/music-fx
【AiBase提要:】
🚀 MusicFX使用谷歌和DeepMind技术,使用户通过几句话即可创作音乐,标志性的AI音乐创作工具。
🛡️ 工具强调负责任的AI创新,通过公众参与和隐私保护解决潜在问题,保护原创艺术家声音和风格。
🌐 MusicFX可能颠覆音乐产业,降低音乐创作门槛,但伴随AI生成内容对版权和音乐原创性的挑战。
GoLinks发布企业人工智能搜索引擎GoSearch
GoSearch是GoLinks推出的人工智能搜索引擎,通过多模态搜索和AI核心技术,提供企业高效的信息检索体验,减轻员工认知负担,支持实时索引和兼容100多个数据源。
【AiBase提要:】
🚀 GoSearch发布: GoLinks的GoSearch旨在解决大型企业在软件应用堆栈中信息泛滥的问题,提高工作效率,支持多模态搜索,如图像、截图、笔记和URL等。
🧠 AI核心技术: GoSearch利用人工智能核心技术,不仅可查找文档,还能理解用户意图,提供信息摘要,减轻员工认知负担,实现细致入微的索引。
🌐 全面搜索功能: GoSearch实时索引数据,兼容100多个数据源,包括Google Workspace和Salesforce,通过多模式搜索提供集成的企业搜索体验,标志着企业搜索领域的一场革命。
👨💻💡🎯聚焦开发者
阿里推虚拟试穿技术Outfit Anyone
阿里推出的Outfit Anyone虚拟试穿技术采用双流条件扩散模型,处理模特和服装数据,通过衣物图像实现逼真的虚拟试穿效果,结合Animate Anyone技术,轻松制作任意角色的换装视频。

项目地址:https://humanaigc.github.io/outfit-anyone/
体验地址:https://huggingface.co/spaces/HumanAIGC/OutfitAnyone
【AiBase提要】
👗 多样性试穿体验: Outfit Anyone采用双流条件扩散模型,处理模特、服装和文本提示,实现逼真虚拟试穿效果,包括对各种古怪和独特服装风格的处理。
👥 泛化能力强大: 技术展示了对各种体型和动漫角色的泛化能力,支持不同生活背景和新动画角色的试穿需求。
🎥 轻松换装视频制作: 结合Animate Anyone技术,实现了更丰富的试穿体验,用户可以轻松制作任意角色的换装视频。
斯坦福华人提出全新视频生成框架WonderJourney
斯坦福华人研究人员推出的WonderJourney框架,通过一句话或一张图生成连贯的3D场景,融合语言模型和视觉模块,展现出无限的创意可能。

项目网址:https://kovenyu.com/wonderjourney/
【AiBase提要:】
🌐 全新框架设计: WonderJourney采用模块化工具,可从任何位置开始,通过简短文本或图像生成连贯的3D场景序列。
🎨 文本驱动的创意: 利用Language Model生成场景描述,通过视觉模块生成彩色点云,展示多样化的可控制的奇妙之旅。
🚀 重要突破与应用: WonderJourney开创了3D场景生成领域,为用户提供强大而灵活的工具,通过简单输入创造丰富的3D视觉体验,为艺术、影视等领域带来新可能性。
微软推压缩技术LLMLingua
微软推出LLMLingua,采用独特粗细压缩技术,解决大型语言模型中长提示带来的计算效率问题,实现高达20倍的压缩比例。

项目网址:https://github.com/microsoft/LLMLingua
论文网址:https://arxiv.org/pdf/2310.05736.pdf
【AiBase提要】
🔄 动态预算控制: LLMLingua采用动态预算控制,在大比例压缩下分配压缩比例,保持提示的语义完整性。
🎯 标记级迭代压缩算法: 引入标记级迭代压缩算法,实现复杂压缩并保持关键提示信息。
🔄 指令调整方法: 提出基于指令调整的方法,解决语言模型分布不一致问题,提高小型语言模型与大型LLM的兼容性。
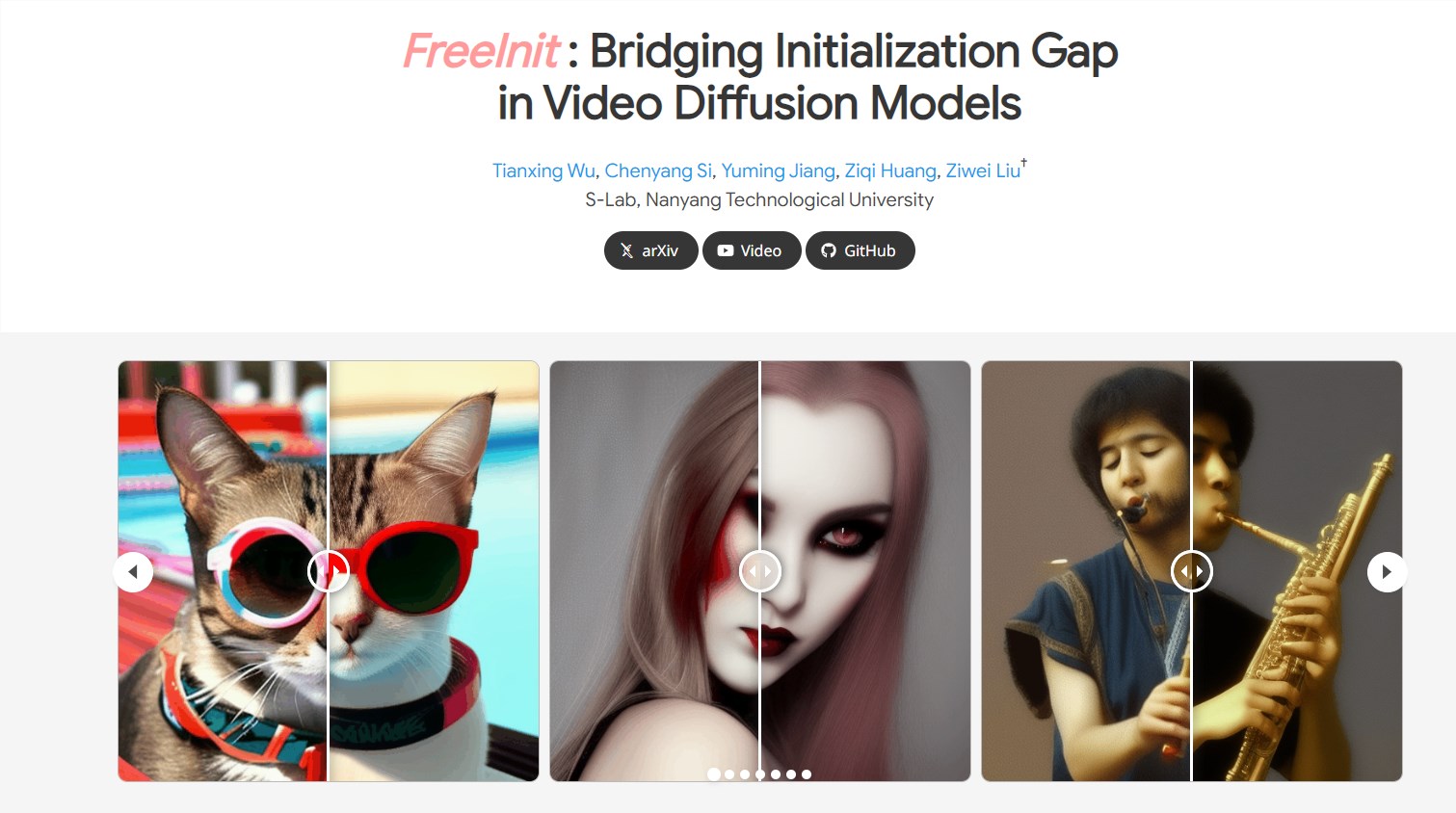
南洋理工发布提高AI视频生成内容一致性方法FreeInit
南洋理工大学推出名为FreeInit的方法,通过优化推理初始噪声的时空低频组件,显著提高人工智能视频生成的内容一致性,为视频创作和人工智能应用带来新可能性。
项目地址:https://tianxingwu.github.io/pages/FreeInit/
【AiBase提要】
💡 FreeInit方法创新: 通过迭代优化推理初始噪声的时空低频组件,无需额外训练,显著提高视频生成的时空一致性。
💻 隐含训练-推理差距揭示: 研究视频扩散模型的噪声初始化,发现训练-推理差距,提出FreeInit填补初始化差距,改善生成结果。
🚀 技术前景展望: FreeInit方法的发布为人工智能视频生成领域带来新突破,有望提高视频生成的质量和时间一致性,为未来发展带来更多可能性。
谷歌发布开源虚拟人物库“VALID”
谷歌AR&VR与佛罗里达中央大学合作发布开源虚拟人物库“VALID”,含210个全套虚拟人物,代表七个不同种族,旨在促进多样性和包容。研究结果显示对亚洲、黑人和白人虚拟人物的一致认知,但其他种族存在认知歧义。同族偏见影响了虚拟人物辨识,强调参与者种族对研究的影响。库提供开放访问,支持Unity和Unreal等游戏引擎,挑战刻板印象,为虚拟人物研究和应用提供多样性视角。

项目网址:https://github.com/google/valid-avatar-library
论文:https://www.frontiersin.org/articles/10.3389/frvir.2023.1248915/full
【AiBase提要】
🌐 谷歌AR&VR与佛罗里达中央大学发布名为“VALID”的虚拟人物库,包含210个全套虚拟人物,代表七个不同种族。
👥 研究结果显示亚洲、黑人和白人虚拟人物在各种族参与者中有一致认知,但其他种族存在认知歧义,同族偏见影响虚拟人物辨识。
📚 开源的“VALID”库支持Unity和Unreal等游戏引擎,挑战刻板印象,为虚拟人物研究提供多样性视角。
苹果研究人员提出MAD-Bench基准,克服多模态大语言模型中幻觉和误导性提示
**划重点:**1.🧠MLLMs在处理误导性信息时存在脆弱性,苹果提出MAD-Bench基准解决问题。2.📊MAD-Bench包含850个图像提示对,评估MLLMs在文本提示和图像之间处理一致性的能力。3.🚀研究表明GPT-4V在场景理解和视觉混淆方面表现更好,为提高AI模型鲁棒性提供了战略性提示设计方案。站长网2024-03-01 16:14:580000华为“纯血鸿蒙”明年亮相!鸿蒙先锋应用专区上线华为商店
快科技12月17日消息,自9月华为宣布鸿蒙原生应用全面启动以来,已有社交、影音、游戏、金融、食品等领域的企业加入鸿蒙生态建设,开发鸿蒙原生应用。日前,华为应用市场众测版新增鸿蒙先锋应用专区”,与之前的鸿蒙应用专区不太一样。这些应用放在鸿蒙先锋应用专区是代表已经官宣进行鸿蒙原生应用开发,也可以说是为鸿蒙原生应用提前宣传引流。0000借势《封神》,支付宝、书亦、知乎谁的玩法更“毒”?
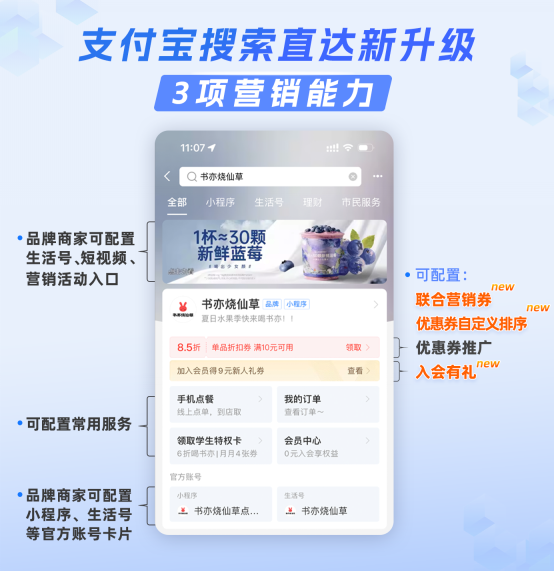
迄今为止,堪称国产电影中投资最大的《封神》,视觉效果炸裂,加上故事本身就拥有一定的受众、明星云集与中国神话史诗title的加持,让新编电影在各大社交媒体火出了圈。蹭着这波热度,不少品牌选择与《封神》电影联名或者和电影中的演员合作,想要将电影的热度延续到品牌身上来,实现热度、口碑数值的直线上升,在内卷的市场中为品牌多博一些关注。01借势《封神》,支付宝、书亦、知乎有奇招站长网2023-09-09 11:31:150000支付宝搜索直达新升级3项营销能力 可实现“搜索后快速入会”
7月13日,据支付宝开放平台消息,支付宝搜索直达升级并新增了3项营销能力——会员有礼、联合营销券以及优惠券自定义排序,可以让商家缩短会员拉新路径,提升券营销的方式和效率。站长网2023-07-14 00:35:470000亚马逊实时AI编程助手CodeWhisperer正式免费开放
近日,亚马逊云科技宣布,实时AI编程助手AmazonCodeWhisperer正式可用,同时推出的还有供所有开发人员免费使用的个人版(CodeWhispererIndividual)。站长网2023-04-18 14:51:370000