开源模型「幻觉」更严重,这是三元组粒度的幻觉检测套件
BSChecker:细粒度大模型幻觉检测工具与基准测试排行榜
大模型长期以来一直存在一个致命的问题,即生成幻觉。由于数据集的复杂性,难免会包含过时和错误的信息,这使得输出质量面临着极大的挑战。过多的重复信息还可能导致大型模型产生偏见,这也算是一种形式的幻觉。如何检测和有效缓解大模型的生成幻觉问题一直是学术界的热门课题。
近日,亚马逊上海人工智能研究院推出细粒度大模型幻觉检测工具 BSChecker,包含如下重要特性:
细粒度幻觉检测框架,对大模型输出文本进行三元组粒度的幻觉检测。
幻觉检测基准测试集,包含三种任务场景,满足用户的不同需求。
两个基准测试排行榜,目前涵盖15个主流大模型的幻觉检测结果。
另外,BSChecker的作者们在Gemini推出后也很快做了自动检测的幻觉测试。
幻觉检测框架示意图
项目地址:https://github.com/amazon-science/bschecker-for-fine-grained-hallucination-detection
排行榜地址:https://huggingface.co/spaces/xiangkun/BSChecker-Leaderboard
技术亮点
更细的粒度:与传统的段落或句子级别的分析方法不同,BSChecker 将大模型的输出文本分解成知识三元组。进行这样的细粒度检测不仅能验证单个知识的真实性,还为进一步的精确分析提供了可能。
通常我们将幻觉检测的最小单元称为一个声明(claim)。在前人的工作中,有使用输出文本中的句子作为声明的(SelfCheckGPT),也有使用模型从输出文本中抽取更短的子句作为声明的(FActScore,FACTOOL)。BSChecker 探索了使用知识三元组表示声明的方法,这个想法受到知识图谱的启发,在知识图谱中三元组被用来封装事实和知识单元。知识三元组采用(主语,谓词,宾语)的结构,捕捉输出文本中的细粒度信息。以下示例展示了一句句子和其对应的细粒度三元组表示:
吴京在电影《战狼》中饰演了主角冷锋。
三元标签模式:不同于传统幻觉检测方法将整个输出文本分类为是否存在幻觉这两种类别标签,BSChecker 对输出文本中的每一个声明都进行幻觉检测并分类。通过这种方式,输出文本和其相应的参考文本之间的关系可以可视化为下图:
图中输出文本和参考文本之间的交集是可以直接验证的部分,其中又分为蕴涵(Entailment,图中绿勾✅)和矛盾(Contradiction,图中红叉❌)两类,具体取决于声明是否得到参考文本的支撑。然而,在实际应用中,参考文本可能并不总是能提供足够的证据来验证所有声明。在这种情况下,这些声明的真实性需要额外的参考文本才能进行评估(橙色问号),我们将这样的声明称为中性(Neutral)。
这三个类别与事实核查(Fact Checking)领域中的支撑(Support)、反驳(Refute)和信息不足(Not Enough Information)这三个概念密切相关,并且它们在自然语言推理(NLI)中也有应用。BSChecker 使用这种三元标签模式取代传统的二分类标签,使得输出文本与参考文本之间的关系得到更精确的表达。
更广泛的覆盖范围:BSChecker 根据输入大模型的上下文的数量和质量,设定了三种不同的场景,分别是无上下文(如开放性问答任务),带噪声的上下文(如检索增强生成任务)和准确上下文(如文本摘要、信息抽取任务)。
三种场景对比示意图
基于这三种场景,作者构建了一个基准数据集,包括300个示例,每种场景对应100个示例。这些示例是从下表中列出的数据源中随机抽取的:
BSChecker 工作流程
BSChecker 具有模块化的工作流程,分为三个可配置的模块:声明抽取器 E,幻觉检测器 C,以及聚合规则 τ。这三个模块互相解耦合,可以通过增强其中的部分模块对整个框架进行扩展和改进。
BSChecker 工作流程图
其中两个主要模块是:
基于大模型的声明抽取器:作者发现大模型很擅长提取声明三元组,在当前版本中,他们使用 GPT-4和 Claude2作为声明抽取器。
基于人工或模型的幻觉检测器:对于给定的声明三元组和参考文本,标注者可以相应地进行标注,如下图所示。该标注工具也将很快发布。基于模型的幻觉检测器将在后续的自动评估排行榜章节中介绍。
无上下文场景下的评估过程
人工评估结果
BSChecker 目前收录了2100个经过细粒度人工标注的大模型输出文本,涵盖了7个主流大模型,如 GPT-4、Claude2、LLaMA2等。基于这个结果,作者构建了一个交互式的排行榜,见下图。人工评估排行榜包含两个可交互的选项:1)上文中提到的三种任务场景,以及三种场景上平均的结果(顶部选项);2)评估指标(左侧 “排名依据” 选项)。下图显示了依据蕴涵排名得到的排行榜。
根据人工评估结果,作者得出了以下发现:
上下文信息对于输出符合事实的文本至关重要
平均而言,从无上下文到带噪声的上下文,再到准确上下文,评估结果为矛盾的比例从21% 降至11%,再到5%。
在真实性方面,最新的商业闭源大模型比大多数开源大模型更强
最新的商业大模型,如 Claude2、GPT-4和 GPT-3.5-Turbo,相较于大多数开源大模型,产生了更少的幻觉。具体而言,商业大模型在准确上下文场景中表现良好。例如,GPT-4在这个场景中几乎没有幻觉(0.9% 矛盾和1.2% 中性)。LLaMA270B 在排行榜上与商业大模型结果接近,特别是在提供上下文的情况下。
GPT 系列大模型的真实性稳步提高
GPT-4比 GPT-3.5更好,而 GPT-3.5又远远优于 InstructGPT。作者从相关文献中寻找并总结了一些可能的解释,详见代码仓库中的 README。其中一个实验是:他们将相同的文本输入 GPT-4,并要求它解释,这是一种修改过的检索增强生成(RAG)场景。有趣的是,GPT-4犯了一个明显的错误,它宣称在真实性方面 InstructGPT 比 GPT-3.5更好。
即使对于最新的商业大模型,无上下文场景仍然具有挑战性
虽然 GPT-4和 Claude2在很大程度上领先于开源大模型,但 GPT4仍然有超过10% 的错误,这是一个不可忽视的错误比例。Claude2相对保守,犯的错误(即矛盾)较少,但往往提供更多无法验证的输出文本。
自动评估排行榜
人工标注有助于深入了解大模型的幻觉,但对于评估更多的大模型而言,它们不具备可扩展性。BSChecker 框架允许插入基于模型的幻觉检测器,作者发现大模型和自然语言推理(NLI)模型都是不错的选择。它可以在命令行轻松配置,从而形成一个完全自动化的端到端幻觉检测框架。
以下动图显示了由 GPT-4作为声明抽取器和幻觉检测器得到的排行榜。作者现在在排行榜上评估了15个大模型。用户可以方便地使用他们的工具将自己检测的结果放在排行榜上。
自动幻觉检测框架的性能如何?
作者使用 Kendall's tau 来衡量自动排行榜与人工评估排行榜之间的一致性。具体地,他们使用了 scipy.stats.kendalltau,它可以返回两个排名之间的 p 值(表示置信度)和 tau 值(表示相关性)。下面的热度图显示了声明抽取器(列)、幻觉检测器(行)和任务场景(水平条)的各种组合结果,他们展示了其中高置信度(p 值 <0.05)的组合。有趣的是,这些高置信度的条目也都显示出了很高的相关性(tau>0.3)。例如,想要在无上下文场景中依据矛盾比例排名,用户可以使用 GPT-4声明抽取器和 GPT-4或 NLI 幻觉检测器;想要排名准确上下文场景中的蕴涵比例,可以使用 Claude2声明抽取器和 GPT4幻觉检测器。
他们使用 BSChecker 的自动检测框架对 Gemini 进行了幻觉检测,将 GPT-4作为声明抽取器和幻觉检测器,在无上下文场景下按照矛盾比例进行排名(和上述推荐设置一致),得到的结果与 Gemini 报告中的实验结果一致。他们还进一步对其中的10个输出文本进行了人工标注,其中共包含118个声明三元组,标注结果显示自动检测和人工标注的一致性达到了90.7%。
BSChecker 使用方式
用户现在可以在 GitHub 代码仓库中访问 BSChecker,也可以通过 pip 进行安装。使用方式可参阅 README 中的 Quick Start 部分。其中包含如何使用 BSChecker 提取知识三元组、在三元组级别检测幻觉以及评估自定义大模型的详细说明。此外,用户可以将自定义的评估结果添加到自动评估排行榜中,与其他结果进行比较。
合作邀请:共同推动 BSChecker 的发展
作者相信,细粒度的检测和准确定位幻觉是有效缓解幻觉的第一步。BSChecker 仍有很大的改进空间,他们热情地邀请大家参与开源贡献。以下是一些可能的方向:
开源声明抽取器和幻觉检测器:目前,性能最好的配置使用了闭源的商业大模型,作者在当前版本中也包含了一个基于自然语言推理的幻觉检测器,尽管速度更快,但在处理长文档时仍存在较大的性能差距。
错误记忆追溯:对于无上下文场景,使用搜索引擎查找最新的参考文献是一种非常简略的解决方案。但理想情况下,我们应该回到大模型的训练数据,去追溯有问题的记忆。
三元组抽取的优化:三元组是简洁的,但在处理更复杂的语义时存在困难。它们也是对文本的一个采样,因此不能涵盖文本中的全部语义,也不善于处理上下文中的细微差别。
幻觉检测证据的定位:将三元组映射回文本可能并不容易,例如在处理多步推理时存在挑战。
对齐人工评估结果:在复杂环境中,特别是在复杂上下文中缩小检测器和人工评估者之间的差距。
扩展任务覆盖:大模型在许多不同的任务和场景中被使用。由于资源限制,本研究在某些领域的覆盖范围较小。例如,在当前的基准测试集中,仅有6个示例涵盖了摘要任务。
平衡真实性与有益性:BSChecker 目前仅评估幻觉的数量,这可以通过生成真实但无益的文本来操纵评估结果,正如作者观察到的一些大模型的表现那样。因此,对于 BSChecker 来说,引入一个关于有益性的评估标准可能很重要。
中国电信天翼云将发布预训练大模型 已进入内部测试阶段
据第一财经报道,天翼云科技有限公司在2023云生态大会上表示,天翼云正在自主研发预训练大模型,目前已经进入内部测试阶段,将在近期适当的时候发布。据了解,天翼云科技有限公司,是中国电信子公司。2021年7月1日,天翼云科技有限公司成立,注册资本9亿元人民币,该公司由中国电信100%控股。而天翼云是中国电信旗下云计算品牌,2016年,天翼云发布天翼云3.0。站长网2023-04-26 15:25:080000拿货靠抢!义乌“年画大王”卖全球
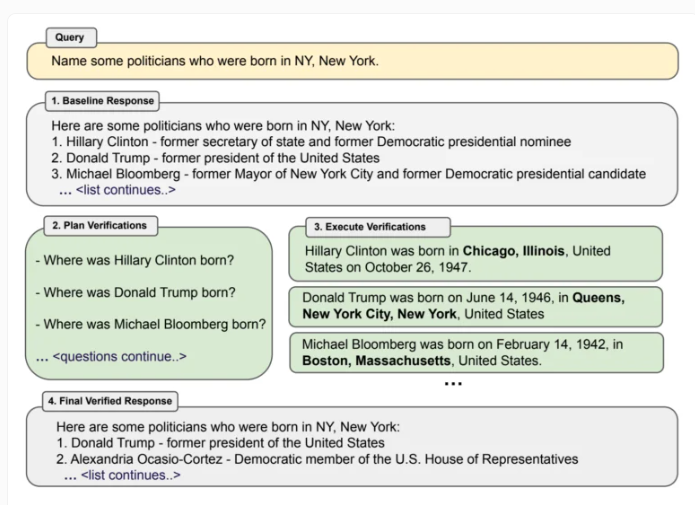
新春佳节,家里必须带点红。对中国人来说,贴年画是迎接春节的一项重要仪式,腊月里,大家会在房屋正大门贴上“倒福”和春联,年味也就呼之欲出了。卖年画、对联的老板会被喊作“送福气的人”。中国各地被喊作“年画大王”的人不少,他们往往在年画绘制上拥有精湛的手艺,但在义乌,“年画大王”更是这门生意的操盘者:以义乌市文化礼品行业协会会长、义乌市年画挂历商会会长楼宝娟为代表的从业者达六七百家,占全球八成市场。站长网2024-02-16 10:38:030000Meta提出CoVe提示工程方法 减少ChatGPT等聊天机器人幻觉问题
划重点:💡Meta提出了链式验证(Chain-of-Verification,简写CoVe)方法,让聊天机器人根据初步回复自我生成验证问题,从而减少错误信息。📊CoVe可将列表式问题的准确度提高一倍以上,即使长文本的事实准确性也可提高28%。🔮未来可结合外部知识提升CoVe效果,如让聊天机器人访问外部数据库回答验证问题。站长网2023-10-13 10:44:490000解散核心团队?董明珠口中那个“不比苹果差”的格力手机终究凉了
“格力”这个品牌想必绝大多数人都熟知,毕竟它的宣传语“好空调格力造”,在一定程度上确实很深入人心。不过,随着互联网发展,董明珠似乎已经不满足于现状,开始跨领域发展,选择了“造手机”这个领域。在早前,董明珠在接受采访时就表示,格力有做手机的打算,并且使用个三年都不会坏。随后,格力手机于2015年3月18日正式发布,并以董明珠头像作为开机画面,市场价格不到2000块。站长网2023-05-24 21:43:080000NVIDIA市值步步紧逼苹果:能否夺走第二之位
快科技6月2日消息,在人工智能技术的推动下,半导体巨头NVIDIA的股价一路狂飙,市值紧逼科技巨头苹果,引发了市场对其能否夺走全球市值第二把交椅的猜测。几乎所有的AI应用,包括近期爆红的ChatGPT,都依赖于NVIDIA的高端芯片,这一趋势使得NVIDIA的市值在过去一年里几乎翻倍,达到2.7万亿美元,与苹果的差距仅为2500亿美元。0000