谷歌发布Cloud TPU v5p和AI超级计算机:人工智能处理能力飞跃
**划重点:**
1. 💡 **Cloud TPU v5p亮点:** Google 推出的最强大的张量处理单元,性能设计突出,每个 pod搭载8,960个芯片,芯片之间的互联速度达到4,800Gbps,相较于前代 v4,性能翻倍,高带宽内存(HBM)更是增加三倍。
2. 💡 **AI Hypercomputer革新:** AI 超级计算机采用优化的性能硬件、开源软件、主要机器学习框架以及可调整的消耗模型,通过协同系统设计提高在培训、微调和服务领域的人工智能效率和生产力。
3. 💡 **灵活消耗模型:** AI Hypercomputer引入创新的Dynamic Workload Scheduler和传统的消耗模型,支持Cloud TPU和Nvidia GPU,优化用户支出。
谷歌在推出其张量处理单元Cloud TPU v5p和具有突破性的超级计算机架构AI Hypercomputer时掀起了轩然大波。这些创新的发布,再加上资源管理工具Dynamic Workload Scheduler,标志着在处理组织的人工智能任务方面迈出了重要的一步。

Cloud TPU v5p,继去年11月发布的v5e之后,成为谷歌最强大的TPU。与其前身不同,v5p以性能为驱动设计,承诺在处理能力方面取得显著的改进。每个pod配备8,960个芯片,芯片之间的互联速度达到4,800Gbps,这一版本在浮点运算每秒(FLOPS)方面提供了两倍的性能,并在高带宽内存(HBM)方面比前代TPU v4增加了三倍。

在性能方面的聚焦取得了显著的成果,Cloud TPU v5p在训练大型LLM模型时的速度比TPU v4提高了惊人的2.8倍。此外,利用第二代SparseCores,v5p展示了在嵌入式密集模型方面的训练速度,比其前身快了1.9倍。
与此同时,AI Hypercomputer**作为超级计算机架构的一场革命性变革。它融合了优化的性能硬件、开源软件、主要机器学习框架和可调整的消耗模型。AI Hypercomputer放弃了强化离散组件的传统方法,而是利用协同系统设计,提高了在培训、微调和服务领域的人工智能效率和生产力。
这一先进的架构基于超大规模数据中心基础设施的精心优化的计算、存储和网络设计。此外,它通过开源软件为开发人员提供了对相关硬件的访问,支持诸如JAX、TensorFlow和PyTorch等机器学习框架。这种集成扩展到Multislice Training和Multihost Inferencing等软件,同时深度集成了Google Kubernetes Engine(GKE)和Google Compute Engine。
AI Hypercomputer的真正独特之处在于其灵活的消耗模型,专门满足人工智能任务的需求。它引入了创新的Dynamic Workload Scheduler和像承诺使用折扣(CUD)、按需和Spot等传统消耗模型的平台。这个资源管理和任务调度平台支持Cloud TPU和Nvidia GPU,简化了调度所有所需加速器以优化用户支出。
在这个模型下,Flex Start选项非常适合模型微调、实验、较短的培训会话、离线推理和批处理任务。它提供了一种经济有效的方式,在执行前请求GPU和TPU容量。相反,Calendar模式允许预订特定的启动时间,满足对培训和实验任务需要精确启动时间和持续时间的要求,可提前8周购买,持续7或14天。
谷歌发布Cloud TPU v5p、AI Hypercomputer和Dynamic Workload Scheduler代表了人工智能处理能力的一大飞跃,引领着性能增强、优化架构和灵活的消耗模型的新时代。这些创新有望重新定义人工智能计算的格局,并为各行各业的突破性进展铺平道路。
官方博客网址:https://cloud.google.com/blog/products/ai-machine-learning/introducing-cloud-tpu-v5p-and-ai-hypercomputer
DeepSeek带飞寒武纪
靠着DeepSeek红利,这家公司扭亏转盈,成为了首次盈利的“寒王”,那就是被称为“中国版英伟达”的寒武纪。寒武纪近期以一份“逆转式”财报震动资本市场。这家曾连续8年累计亏损54亿元的AI芯片企业,在2024年中实现了上市以来的首次盈利。并且在2025年第一季度,实现营业收入11.11亿元,相较去年同期猛增4230.22%,归母净利润达到了3.55亿元。00005999元起!vivo发布上下折叠屏手机X Flip:魔幻3寸外屏、妹纸最爱
快科技4月20日消息,今晚vivo在线上举行了新品发布会,其中一款就是XFlip,从发布后的反馈情况看,还是很受妹子们的喜欢。站长网2023-04-20 22:03:580000全球 75% 的组织将禁止在工作设备上使用 ChatGPT 和生成式 AI 应用程序
BlackBerry发布的一项最新研究显示,全球75%的组织目前正在考虑或已经开始禁止在工作场所使用ChatGPT和其他生成式AI应用程序。在考虑或已经实施禁令的企业中,61%表示这些措施将长期或永久存在,这是因为数据安全、隐私和企业声誉面临的风险迫使他们采取行动。83%的受访者还表示,他们担心不安全的应用程序对企业的IT环境构成网络安全威胁。站长网2023-08-09 10:15:230001马斯克将出席英国首相 Rishi Sunak 主持的人工智能安全峰会
站长之家(ChinaZ.com)10月31日消息:据《卫报》消息确认,马斯克将出席本周在布莱切利公园举行的RishiSunak主持的AI安全峰会,两人将于周四在这位亿万富翁的社交媒体网站X上进行现场对话。这位科技亿万富翁将成为由英国首相主持、为期两天的峰会上最引人注目的与会者之一,目的是讨论先进人工智能的潜在危险。站长网2023-10-31 09:10:480000速卖通增长60%,成阿里财报最大亮点
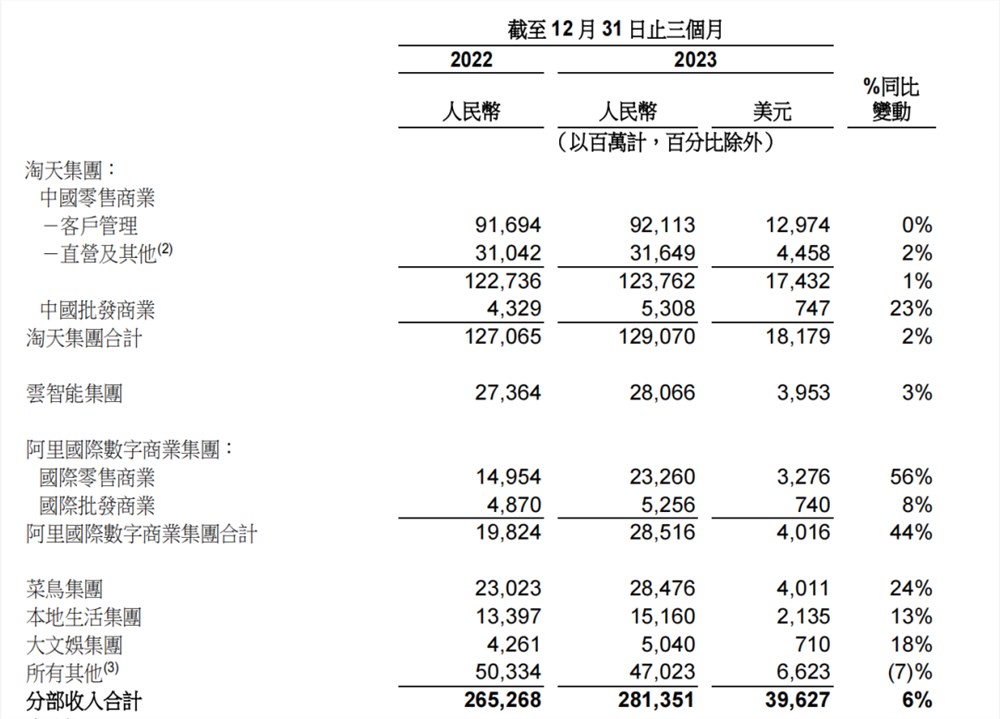
今日晚间,阿里发布了新一季财报。其中,阿里国际表现亮眼,营收同比增长44%至285.16亿元,速卖通AliExpress订单增长60%,连续6个季度超出市场预期。财报指出,增长的重要原因是零售商业整体订单强健增长,速卖通Choice的收入贡献。不难看出,“Choice”模式正成为拉动速卖通,乃至阿里国际订单和收入高增长的引擎,而其背后的供应链模式,正是跨境电商领域被广泛应用的全托管和半托管。站长网2024-02-08 16:47:400000