小模型也可以「分割一切」,Meta改进SAM,参数仅为原版5%
对于2023年的计算机视觉领域来说,「分割一切」(Segment Anything Model)是备受关注的一项研究进展。

Meta四月份发布的「分割一切模型(SAM)」效果,它能很好地自动分割图像中的所有内容
Segment Anything 的关键特征是基于提示的视觉 Transformer(ViT)模型,该模型是在一个包含来自1100万张图像的超过10亿个掩码的视觉数据集 SA-1B 上训练的,可以分割给定图像上的任何目标。这种能力使得 SAM 成为视觉领域的基础模型,并在超出视觉之外的领域也能产生应用价值。
尽管有上述优点,但由于 SAM 中的 ViT-H 图像编码器有632M 个参数(基于提示的解码器只需要387M 个参数),因此实际使用 SAM 执行任何分割任务的计算和内存成本都很高,这对实时应用来说具有挑战性。后续,研究者们也提出了一些改进策略:将默认 ViT-H 图像编码器中的知识提炼到一个微小的 ViT 图像编码器中,或者使用基于 CNN 的实时架构降低用于 Segment Anything 任务的计算成本。
在最近的一项研究中,Meta 研究者提出了另外一种改进思路 —— 利用 SAM 的掩码图像预训练 (SAMI)。这是通过利用 MAE 预训练方法和 SAM 模型实现的,以获得高质量的预训练 ViT 编码器。

论文链接:https://arxiv.org/pdf/2312.00863.pdf
论文主页:https://yformer.github.io/efficient-sam/
这一方法降低了 SAM 的复杂性,同时能够保持良好的性能。具体来说,SAMI 利用 SAM 编码器 ViT-H 生成特征嵌入,并用轻量级编码器训练掩码图像模型,从而从 SAM 的 ViT-H 而不是图像补丁重建特征,产生的通用 ViT 骨干可用于下游任务,如图像分类、物体检测和分割等。然后,研究者利用 SAM 解码器对预训练的轻量级编码器进行微调,以完成任何分割任务。
为了评估该方法,研究者采用了掩码图像预训练的迁移学习设置,即首先在图像分辨率为224×224的 ImageNet 上使用重构损失对模型进行预训练,然后使用监督数据在目标任务上对模型进行微调。
通过 SAMI 预训练,可以在 ImageNet-1K 上训练 ViT-Tiny/-Small/-Base 等模型,并提高泛化性能。对于 ViT-Small 模型,研究者在 ImageNet-1K 上进行100次微调后,其 Top-1准确率达到82.7%,优于其他最先进的图像预训练基线。
研究者在目标检测、实例分割和语义分割上对预训练模型进行了微调。在所有这些任务中,本文方法都取得了比其他预训练基线更好的结果,更重要的是在小模型上获得了显著收益。
论文作者 Yunyang Xiong 表示:本文提出的 EfficientSAM 参数减少了20倍,但运行时间快了20倍,只与原始 SAM 模型的差距在2个百分点以内,大大优于 MobileSAM/FastSAM。

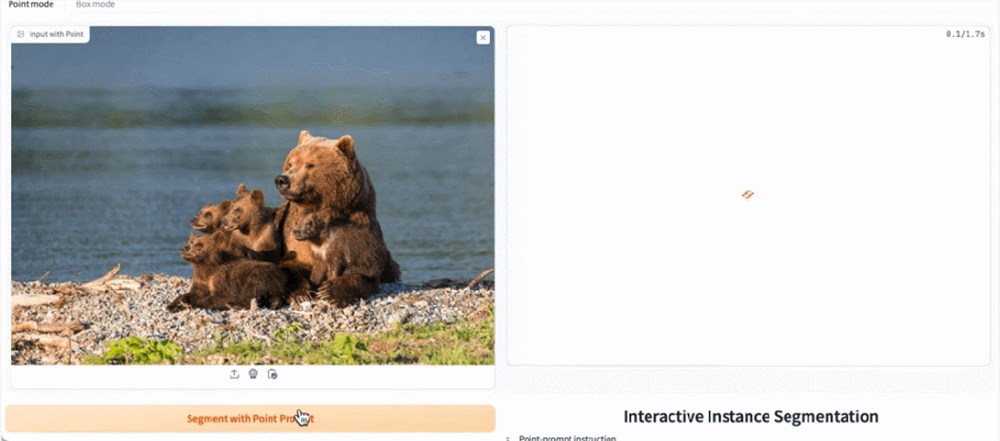
在 demo 演示中,点击图片中的动物,EfficientSAM 就能快速将物体进行分割:
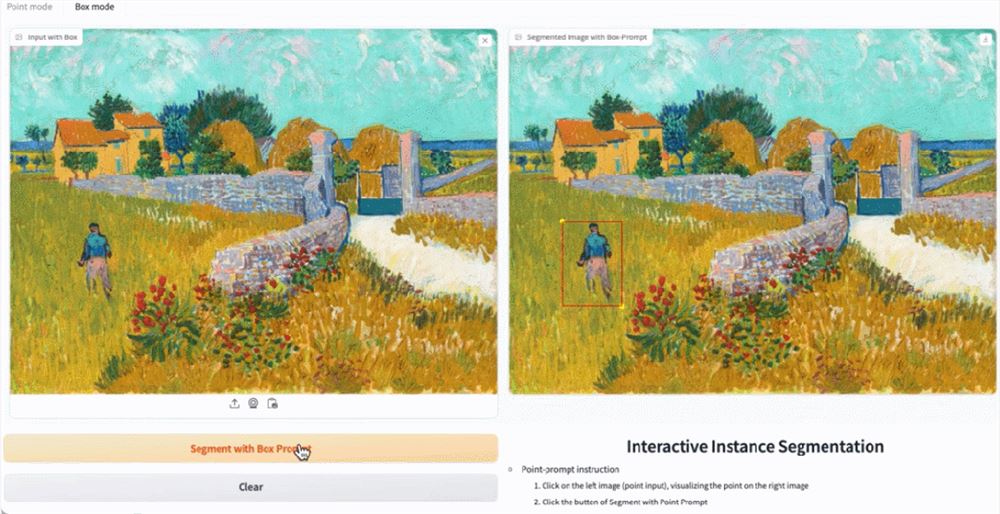
EfficientSAM 还能准确标定出图片中的人:
试玩地址:https://ab348ea7942fe2af48.gradio.live/
方法
EfficientSAM 包含两个阶段:1)在 ImageNet 上对 SAMI 进行预训练(上);2)在 SA-1B 上微调 SAM(下)。
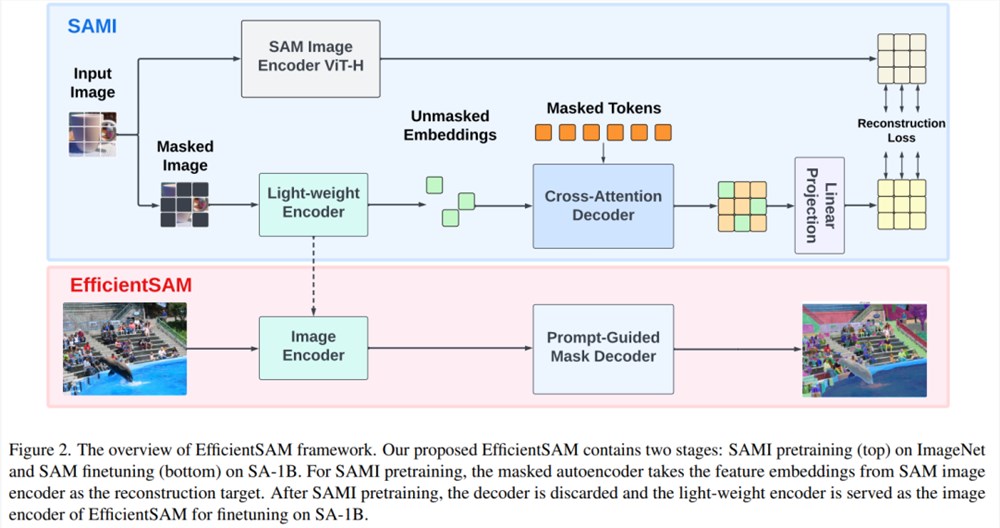
EfficientSAM 主要包含以下组件:
交叉注意力解码器:在 SAM 特征的监督下,本文观察到只有掩码 token 需要通过解码器重建,而编码器的输出可以在重建过程中充当锚点(anchors)。在交叉注意力解码器中,查询来自于掩码 token,键和值源自编码器的未掩码特征和掩码特征。本文将来自交叉注意力解码器掩码 token 的输出特征和来自编码器的未掩码 token 的输出特征进行合并,以进行 MAE 输出嵌入。然后,这些组合特征将被重新排序到最终 MAE 输出的输入图像 token 的原始位置。
线性投影头。研究者通过编码器和交叉注意力解码器获得的图像输出,接下来将这些特征输入到一个小型项目头(project head)中,以对齐 SAM 图像编码器中的特征。为简单起见,本文仅使用线性投影头来解决 SAM 图像编码器和 MAE 输出之间的特征维度不匹配问题。
重建损失。在每次训练迭代中,SAMI 包括来自 SAM 图像编码器的前向特征提取以及 MAE 的前向和反向传播过程。来自 SAM 图像编码器和 MAE 线性投影头的输出会进行比较,从而计算重建损失。
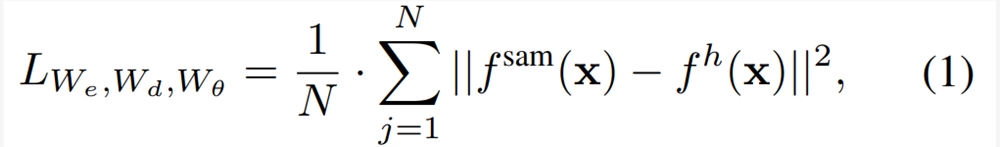
经过预训练,编码器可以对各种视觉任务的特征表示进行提取,而且解码器也会被废弃。特别是,为了构建用于分割任何任务的高效 SAM 模型,本文采用 SAMI 预训练的轻量级编码器(例如 ViT-Tiny 和 ViT-Small)作为 EfficientSAM 的图像编码器和 SAM 的默认掩码解码器,如图所示2(底部)。本文在 SA-1B 数据集上对 EfficientSAM 模型进行微调,以实现分割任何任务。
实验
图像分类。为了评估本文方法在图像分类任务上的有效性,研究者将 SAMI 思想应用于 ViT 模型,并比较它们在 ImageNet-1K 上的性能。
如表1将 SAMI 与 MAE、iBOT、CAE 和 BEiT 等预训练方法以及 DeiT 和 SSTA 等蒸馏方法进行了比较。
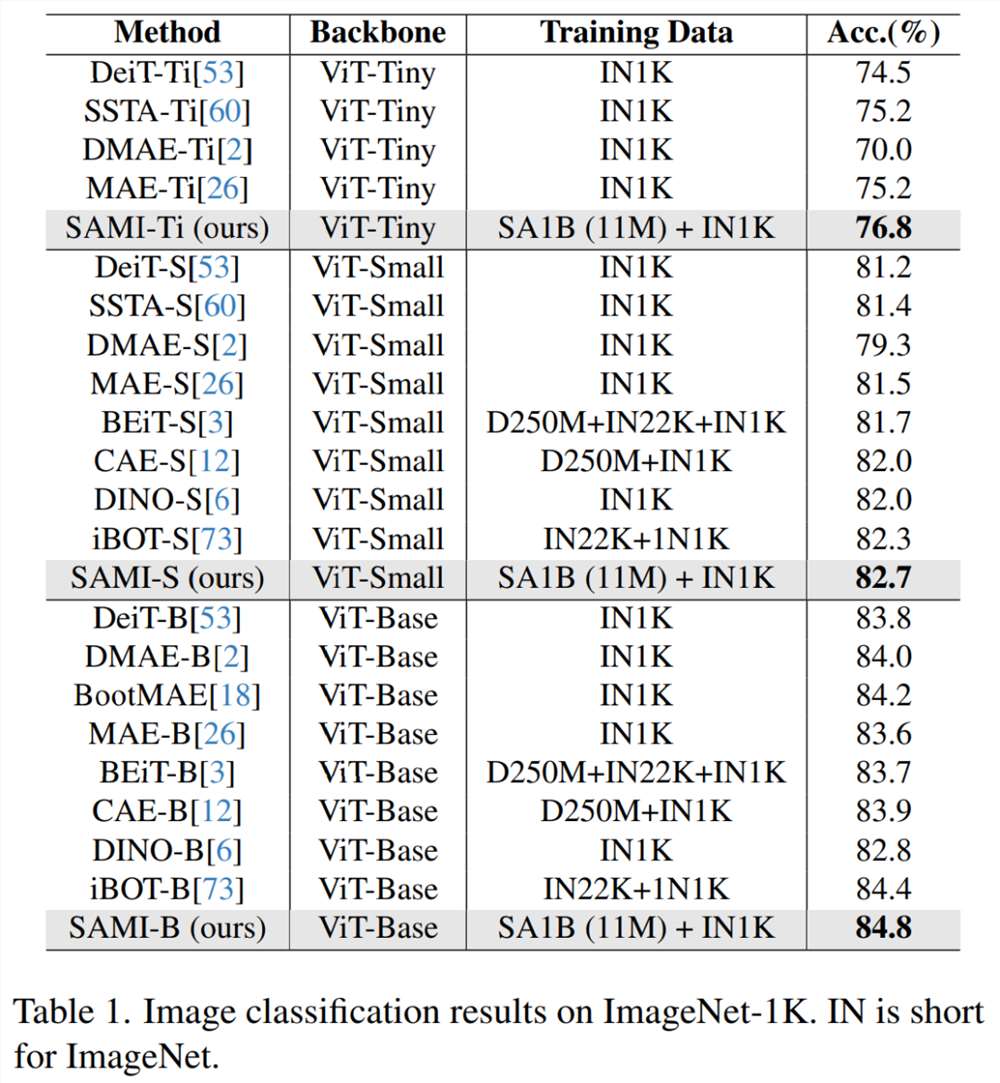
SAMI-B 的 top1准确率达到84.8%,比预训练基线、MAE、DMAE、iBOT、CAE 和 BEiT 都高。与 DeiT 和 SSTA 等蒸馏方法相比,SAMI 也显示出较大的改进。对于 ViT-Tiny 和 ViT-Small 等轻量级模型,SAMI 结果与 DeiT、SSTA、DMAE 和 MAE 相比有显著的增益。
目标检测和实例分割。本文还将经过 SAMI 预训练的 ViT 主干扩展到下游目标检测和实例分割任务上,并将其与在 COCO 数据集上经过预训练的基线进行比较。如表2所示, SAMI 始终优于其他基线的性能。
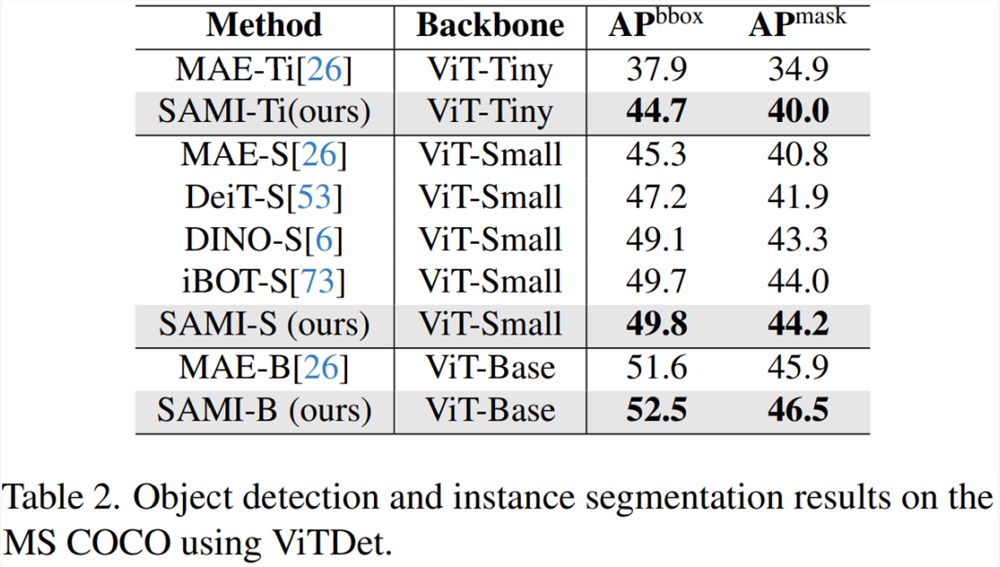
这些实验结果表明,SAMI 在目标检测和实例分割任务中所提供的预训练检测器主干非常有效。
语义分割。本文进一步将预训练主干扩展到语义分割任务,以评估其有效性。结果如表3所示,使用 SAMI 预训练主干网的 Mask2former 在 ImageNet-1K 上比使用 MAE 预训练的主干网实现了更好的 mIoU。这些实验结果验证了本文提出的技术可以很好地泛化到各种下游任务。
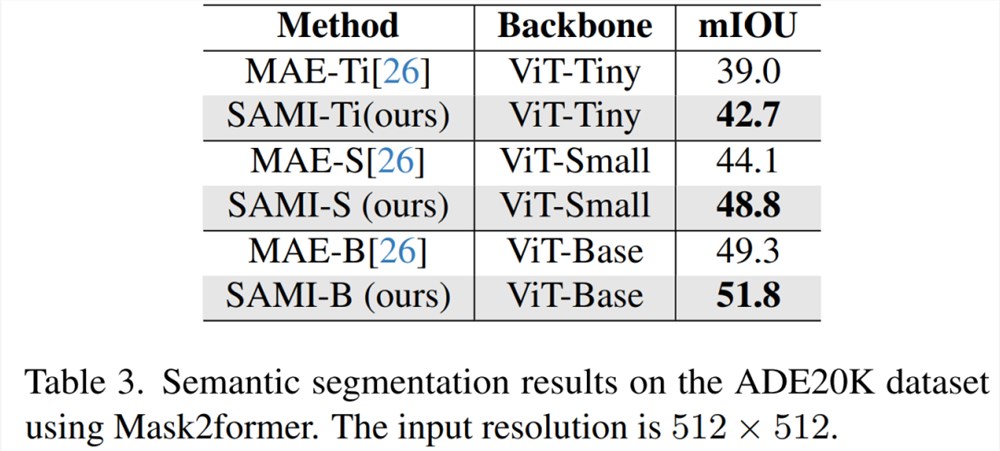
表4将 EfficientSAMs 与 SAM、MobileSAM 和 SAM-MAE-Ti 进行比较。在 COCO 上,EfficientSAM-Ti 的性能优于 MobileSAM。EfficientSAM-Ti 具有 SAMI 预训练权重,也比 MAE 预训练权重表现更好。
此外, EfficientSAM-S 在 COCO box 仅比 SAM 低1.5mIoU,在 LVIS box 上比 SAM 低3.5mIoU,参数减少了20倍。本文还发现,与 MobileSAM 和 SAM-MAE-Ti 相比,EfficientSAM 在多次点击(multiple click)方面也表现出了良好的性能。
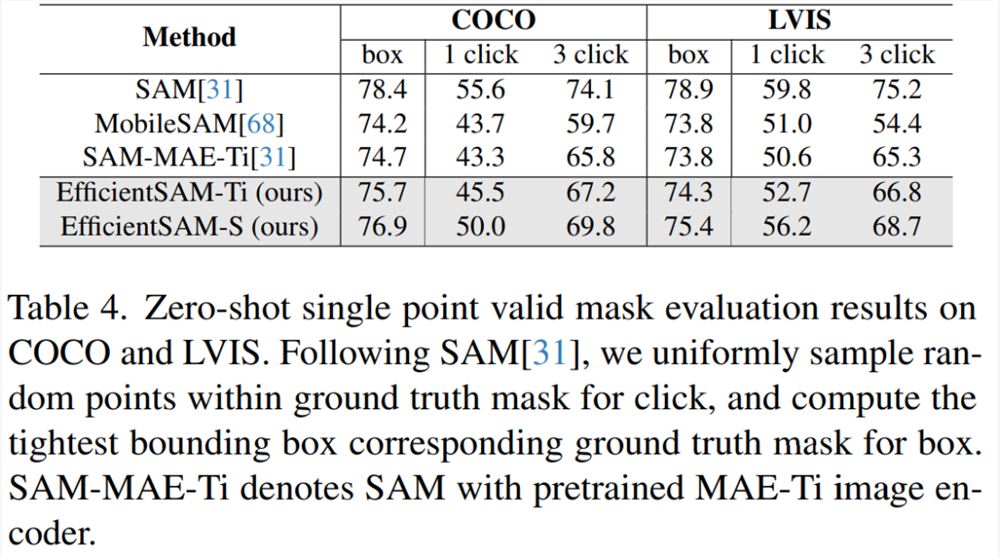
表5展示了零样本实例分割的 AP、APS、APM 和 APL。研究者将 EfficientSAM 与 MobileSAM 和 FastSAM 进行了比较,可以看到,与 FastSAM 相比,EfficientSAM-S 在 COCO 上获得了超过6.5个 AP,在 LVIS 上获得了7.8个 AP。就 EffidientSAM-Ti 而言,仍然远远优于 FastSAM,在 COCO 上为4.1个 AP,在 LVIS 上为5.3个 AP,而 MobileSAM 在 COCO 上为3.6个 AP,在 LVIS 上为5.5个 AP。
而且,EfficientSAM 比 FastSAM 轻得多,efficientSAM-Ti 的参数为9.8M,而 FastSAM 的参数为68M。
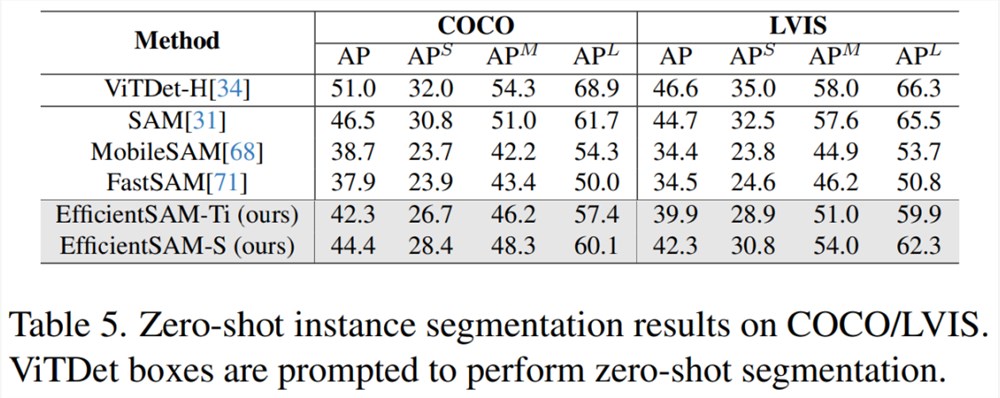
图3、4、5提供了一些定性结果,以便读者对 EfficientSAMs 的实例分割能力有一个补充性了解。



iPhone 15即将量产 富士康重金招人:每人3500元奖金
快科技5月29日消息,2023年上半年还剩下1个月了,通常9月份就要发布新一代iPhone了,代工厂马上就要准备量产新机,为此富士康全球最大的iPhone产区郑州工厂也在加快招人,享受最高3500元的奖金。据郑州富士康iDPBG事业群称,5月29日起员工招聘奖金加码,奖金最高为每人3500元,其中制造部门关键岗位求职者返费奖金为2500元至3000元,介绍人奖金为500元。站长网2023-05-29 08:48:440000百度:文心大模型4.0 API已在千帆大模型平台开放申请
在今日的百度世界大会上,百度创始人、董事长兼首席执行官李彦宏表示,自10月17日起,企业用户可登录百度智能云官网,在千帆大模型平台上申请测试文心大模型4.0的API。数据显示,千帆大模型平台已经成为中国最大、最开放的大模型开发平台,有包括文心一言在内的42个主流大模型入驻,覆盖各行各业近500个场景。站长网2023-10-18 21:14:560001在三线小城,看到本地生意的流量焦虑
六人涌进10平的办公室。阿龙和他们递烟,握手,招呼员工加椅子,再坐回茶桌前,端起壶发现茶盅不够。一个男人摆摆手,提了提银色大扣的腰带坐下。他懒得寒暄,歪头观察起阿龙和这间办公室。和他并排坐在茶桌前的还有黄经理。24小时前,他们曾打来电话,说自家酒楼想了解抖音推广:“哎呀,困扰好久啦。”站长网2023-10-19 11:34:030000科技界春晚!雷军第五次年度演讲来了:完整呈现小米造车心路历程
快科技7月16日消息,2024年雷军年度演讲将于7月19日(周五)19:00举行。除演讲外,当晚还将发布小米MIXFold4、小米MIXFlip两款折叠屏旗舰,以及RedmiK70至尊版等多款新品,堪称科技界春晚。据了解,这是雷军举办的第5次年度演讲,这次他将以《勇气》为主题和大家分享小米造车这三年的经历。0000FF第三季度首次创收 已向新用户交付7辆FF91
法拉第未来(FF)近日在官网发布了一篇名为《致股东信》的文章,公布了2023年第三季度的业绩。据财报显示,FF净亏损7800万美元,汽车销售收入仅为55.1万美元。然而,令人瞩目的是,FF在第三季度首次实现了创收,成为公司重要的里程碑。站长网2023-11-14 10:41:030000