田渊栋团队最新论文解决大模型部署难题 推理系统吞吐量提高近30倍!
田渊栋团队最新发表的论文解决了大型语言模型在实际部署中遇到的内存和输入长度限制的问题,将推理系统的吞吐量提高了近30倍。论文提出了一种实现KV缓存的新方法,通过识别和保留重要的tokens,显著减少了内存占用,并在长输入序列的任务中表现良好。
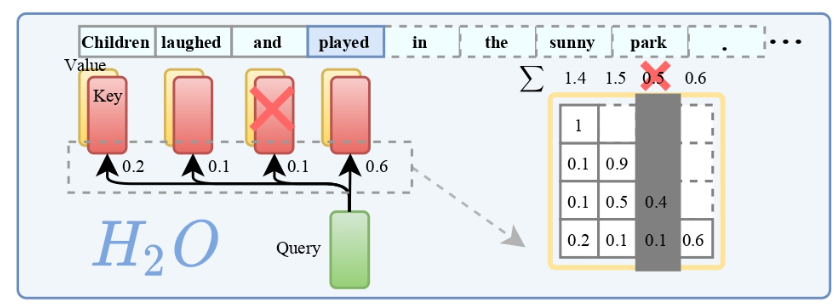
这篇论文的研究对象是大型语言模型(LLM),该模型在实际部署中面临着KV缓存成本昂贵和对长序列的泛化能力差的问题。为了解决这些问题,田渊栋团队提出了一种基于重要tokens的KV缓存逐出策略,通过识别并保留对生成结果有重要贡献的tokens,显著减少了内存占用,并提高了模型在处理长输入序列时的表现。
论文地址:https://arxiv.org/pdf/2306.14048.pdf
代码地址:https://github.com/FMInference/H2O
在实验中,作者使用了OPT、LLaMA和GPT-NeoX等模型验证了他们提出的方法的准确性和有效性。实验结果显示,通过使用该方法,DeepSpeed Zero-Inference、Hugging Face Accelerate和FlexGen这三个推理系统的吞吐量分别提高了29倍、29倍和3倍,且在相同的批量大小下,延迟最多可以减少1.9倍。
通过研究发现,大部分注意力键和值嵌入在生成过程中贡献较少的价值,只有一小部分tokens贡献了大部分的价值。基于这个发现,作者提出了一种基于重要tokens的KV缓存逐出策略,动态保持最近的tokens和重要tokens的平衡。通过使用这种策略,可以显著减少KV缓存的大小,从而降低了内存占用,并提高了模型的推理效率。
综上所述,田渊栋团队的最新论文成功解决了大型语言模型在实际部署中的难题,通过优化KV缓存的实现方法,将推理系统的吞吐量提高了近30倍。这一成果在NeurIPS'23上将进行展示,对于大型语言模型的部署和应用具有重要的意义。
何小鹏建议加速飞行汽车应用落地 推动飞行汽车产业发展
2024年全国两会盛大召开,小鹏汽车董事长兼CEO何小鹏作为全国人大代表,带来了关于无人驾驶、车网融合及飞行汽车应用等前沿科技领域的建议。何小鹏建议,针对充电市场的结构性矛盾,可以探索限定场景的夜间低速无人驾驶。他提出,在具备条件的地方和城市,选取主干道附近的公共充电站,试点开放夜间低速无人驾驶,并允许具备技术条件的车企开展相关试点活动。这一举措旨在激活夜间充电场景,提升充电基础设施的利用率。站长网2024-03-04 17:23:420000汤姆猫:计划申请接入OpenAI的Sora模型
汤姆猫今日在互动平台上宣布,公司正在积极推进接入OpenAI的Sora模型的申请工作,并计划进行相关素材制作的测试。目前,汤姆猫尚未正式接入Sora模型。站长网2024-03-04 15:36:000001你用过没!微信将终结“摇一摇”功能:已上线11年了 早期搭讪神器
快科技2月13日消息,微信中存在了11年的功能要下线了,你注意到没?微信在2012年9月份推出的4.3版本中首次加入了摇一摇”功能,至2024年已经有11年以上历史。有不少用户发现,在微信最新的8.0.47版本中,摇一摇”功能不见踪影,取而代之的是近期上线的听一听”功能。摇一摇”这个功能允许用户通过摇动手机,随机找到附近或者全国的其他用户,进行社交互动。它也可以用来传输图片或参与一些活动。站长网2024-02-13 19:49:340000联合国警告:不受监管的AI芯片植入神经技术威胁“思想自由”
联合国建议不要使用不受监管的人工智能芯片植入神经技术,称这对人们的心理隐私构成严重风险。联合国表示,不受监管的神经技术可能会带来有害的长期风险,例如影响年轻人的思维方式或获取私人思想和情感。联合国明确指出其关注重点在于“未受监管的神经技术”,未提及在五月份获得FDA批准进行人类试验的Neuralink。站长网2023-07-18 16:35:040000给母校捐13亿!雷军回应武汉大学设“雷军班”:我深感荣幸 也无比珍惜
4月27日消息,之前武汉大学宣布,该校2024年起在计算机学院新设雷军班,计划招收30人。据了解,雷军班学生将采用更灵活的培养模式,本硕博自主定制,可100%具备保研资格,本博贯通年限6-8年。雷军对于武汉大学设置雷军班”回应称,这是一份非常珍贵的荣誉,我深感荣幸、也无比珍惜。武大教给我知识,让我学会了学习的方法,指导我走上了科技探索的毕生道路,给了我一生最重要的财富。”0000