细粒度文字转动画技术MoMask 文本驱动的3D人体运动生成模型
要点:
MoMask是一个文本驱动的3D人体动作生成模型,采用层级量化方案表示动作,包括基础层的运动标记和逐层存储的残差标记。
模型包括Masked Transformer和Residual Transformer,用于在训练阶段通过文本输入预测基础层的随机掩码动作标记,并在生成阶段填充缺失标记,并逐渐预测更高层次的标记。
MoMask在文本到运动生成任务中表现优越,例如在HumanML3D数据集上,其FID为0.045,明显优于T2M-GPT的0.141。此外,MoMask还能无缝应用于相关任务,如文本引导的时间修复。
MoMask是一个创新的3D人体运动生成模型,其核心思想是通过层级量化方案表示人体动作,包括基础层和逐层的残差标记。在模型结构上,引入了Masked Transformer和Residual Transformer,分别用于预测基础层的掩码动作标记和逐渐预测更高层次的标记。这一框架使得MoMask在文本到运动生成任务中表现卓越。
MoMask的应用不仅局限于文本到运动生成,还展示了在文本引导的时间修复任务中的出色表现。通过展示中,模型成功地完成了对动作片段中特定区域的修复,根据文本描述 inpaint 了中间、后缀和前缀区域,呈现出令人满意的合成效果。

项目地址:https://github.com/EricGuo5513/momask-codes
在实验结果分析中,MoMask通过对残差量化层的变化进行研究,展示了其对运动标记的高保真重建能力。生成方面的比较进一步证明了残差标记的重要性,MoMask在不同组合的标记下能够更准确地执行微妙的动作,相较于其他基线模型表现更为出色。
论文通过对比MoMask与其他三种强基线方法,包括扩散模型和自回归模型,证明了MoMask在捕捉语言概念和生成更真实动作方面的优越性。这使得MoMask成为文本驱动的3D人体运动生成领域的先进模型。
MoMask通过引入层级量化和Transformer结构,在文本驱动的3D人体运动生成任务中取得了显著的性能提升,同时在相关任务上也展现了出色的通用性。其在重建、生成和比较方面的实验证明了其在3D人体动作建模领域的卓越性能。
去哪儿与华为合作 涉及 AI 与智慧全场景等业务
去哪儿与华为在旅游领域的合作再次进一步。双方将通过华为终端云服务应用生态业务、浏览器与云空间业务以及AI与智慧全场景业务等方面的合作,为消费者创造更多的价值。合作内容涉及到了去哪儿的旅行预定、旅游攻略、景点门票等功能接入华为意图框架,以及优化终端服务页面布局、提升灵活切换城市功能等。站长网2023-08-07 16:01:190000AI日报:百度“橙篇”APP上线;知网状告秘塔AI搜索;Midjourney推全新图像编辑器;清华大学推万字AI系统LongWriter
欢迎来到【AI日报】栏目!这里是你每天探索人工智能世界的指南,每天我们为你呈现AI领域的热点内容,聚焦开发者,助你洞悉技术趋势、了解创新AI产品应用。新鲜AI产品点击了解:https://top.aibase.com/1、百度AI原生应用“橙篇”APP上线集成智能搜索、AI热点推荐等功能站长网2024-08-16 15:59:350000美国国会正测试使用ChatGPT创建和总结内容
美国国会工作人员已获准访问OpenAI的高级订阅服务ChatGPTplus版本,以进行内部试验,据称主要用途是创建和总结内容。据称,国会大概购买了购买了大约40个ChatGPTplus账号,费用为每月20美元,可无限期购买,并按先到先得的原则使用。站长网2023-05-12 20:33:390000发售在即!苹果Vision Pro通过中国3C认证
站长之家(ChinaZ.com)5月14日消息:近日,苹果头显VisionPro,已正式通过中国国家3C质量认证,预示着这款备受瞩目的产品有望在全球开发者大会(WWDC24)后正式发售。与VisionPro一同通过3C认证的还有一款移动电源新品,型号为A2781,由歌尔股份代工,预计将作为VisionPro的配套电池一同上市。站长网2024-05-14 12:04:140000解清帅20天狂涨300万粉丝,直播带货被吐槽,风评反转?
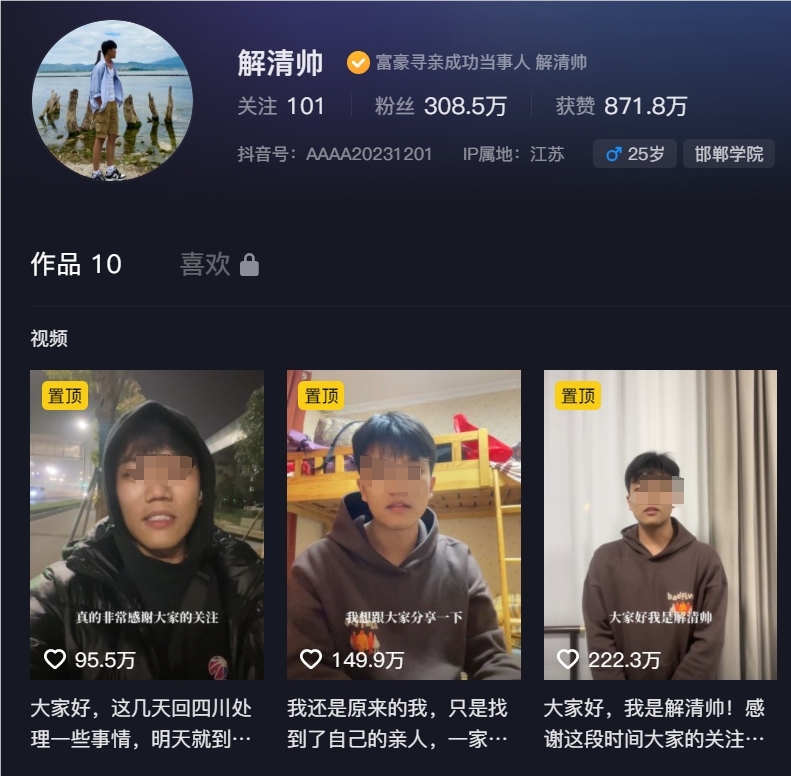
本文由运营公举小磊磊(公众号ID:gongjulei)原创关于我:全网近30W粉丝,只写干货,教你自媒体怎么做,快速起号赚钱。今年12月初,河北“千万富翁”解克锋的寻亲经历轰动全网。在25年的寻子漫漫征途后,他终于与失散的儿子解清帅在江西成功相见,一家人团聚的感人故事感动了千万网友。该事件在抖音等平台广泛传播,许多人祝福他及家人。短短20天,解清帅的抖音账号狂涨300万粉丝!站长网2023-12-25 17:31:480000