通过这些代码,PyTorch团队让Llama 7B提速10倍
要点:
PyTorch团队通过优化技术,在不到1000行的纯原生PyTorch代码中将Llama7B的推理速度提升了10倍,达到了244.7tok/s。
优化方法包括使用PyTorch2.0的torch.compile函数、GPU量化、Speculative Decoding(猜测解码)、张量并行等手段,以及使用不同精度的权重量化,如int8和int4。
通过组合以上技术,包括"compile int4quant speculative decoding"的组合,以及引入张量并行性,实现了在Llama-70B上达到近80tok/s的性能。
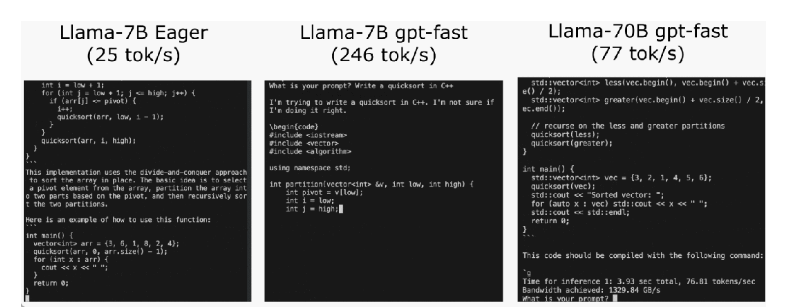
近期,PyTorch团队在其博客中分享了一篇关于如何加速大型生成式AI模型推理的文章。该团队以Llama7B为例,展示了如何通过一系列优化技术将推理速度提升10倍,达到了244.7tok/s。
推理性能的初始状态,大模型推理性能为25.5tok/s,效果不佳。然后,通过PyTorch2.0引入的torch.compile函数,以及静态KV缓存等手段,成功减少CPU开销,实现了107.0TOK/S的推理速度。
代码地址:https://github.com/pytorch-labs/gpt-fast
为了进一步提高性能,团队采用了GPU量化技术,通过减小运算精度来加速模型。特别是使用int8量化,性能提升了约50%,达到了157.4tok/s。
然而,仍然存在一个问题,即为了生成100个token,必须加载权重100次。为解决这个问题,团队引入了Speculative Decoding,通过生成一个“draft”模型预测大模型的输出,成功打破了串行依赖,进一步提升了性能。
使用int4量化和GPTQ方法进一步减小权重,以及将所有优化技术组合在一起,最终实现了244.7tok/s的推理速度。
为了进一步减少延迟,文章提到了张量并行性,通过在多个GPU上运行模型,进一步提高了性能,特别是在Llama-70B上达到了近80tok/s。
PyTorch团队通过一系列创新性的优化手段,不仅成功提升了大模型的推理速度,而且以不到1000行的纯原生PyTorch代码展示了这一技术的实现过程。
人工智能热潮加剧芯片竞争,英特尔竞相追赶三星、台积电等竞争对手
站长之家(ChinaZ.com)11月8日消息:美国芯片巨头英特尔公司(Intel)首席执行官PatGelsinger于周二在IntelInnovationDay上发表讲话,表示该公司最先进的芯片设计18A将于2024年第一季度进入测试生产阶段。站长网2023-11-08 16:22:080000iPhone17系列或迎来更薄机型 迈向全系“超薄时代”
站长之家(ChinaZ.com)6月17日消息:彭博社的知名科技记者MarkGurman在近期节目中指出,新款iPadPro标志着“新一代苹果设备的开始”,其目标是打造出“同类产品中最薄、最轻的产品”。他进一步透露,苹果目前正聚焦于为2025年的iPhone17系列研发一款前所未有的薄型手机。站长网2024-06-17 11:41:440000苹果发布 iOS 16.5 系统更新:修复一长串安全漏洞及增强功能
今天,苹果公司发布了iOS16.5,这是iOS16操作系统的第五个主要更新。虽然iOS16.5不像我们之前看到的某些更新那样引人注目,但其中有一些重要的错误修复和功能增加。以下是iOS16.5更新中所有新功能的详细介绍。AppleNews中的「Sports」选项卡站长网2023-05-19 10:16:460001阿里云发布通义千问2.5版 性能赶超GPT-4 Turbo
阿里云今日正式发布通义千问2.5版本,该版本在模型性能上全面赶超了GPT-4Turbo,展现了其强大的技术实力。与此同时,通义千问最新开源的1100亿参数模型Qwen1.5-110B在多个基准测评中取得了卓越成绩,超越了Meta的Llama-3-70B模型,成为开源领域的新星。站长网2024-05-09 19:41:540000小米SU7无忧服务包上线:包含免费喷漆、补胎等权益
站长之家(ChinaZ.com)7月5日消息:今日,小米汽车正式推出SU7尊享无忧服务包,该服务包已在小米汽车App商城全面上线并开放购买,年度订阅费用仅为1299元,却能让车主享受到价值接近5000元的全方位贴心服务。站长网2024-07-05 16:26:310000