字节跳动与中科大联手提出多模态文档大模型DocPedia
要点:
字节跳动与中国科学技术大学联合研究的多模态文档大模型DocPedia成功突破分辨率极限,达到2560×2560,相较于现有先进模型有显著提升。
DocPedia不仅能准确识别图像信息,还能结合用户需求调用知识库回答问题,展现了高分辨率多模态文档理解的强大能力。
训练DocPedia的关键在于采用感知-理解联合训练策略,通过频域处理解决分辨率问题,以及在微调阶段进行整体优化,显著提高了性能。
字节跳动与中国科学技术大学合作研发的多模态文档大模型DocPedia已成功突破了分辨率的极限,达到了2560×2560的高分辨率。这一成果是通过研究团队采用了一种新的方法,解决了现有模型在解析高分辨文档图像方面的不足。
在此研究中,提出了DocPedia,一个高分辨率多模态文档大模型,与业内先进模型相比,其分辨率明显提高,达到2560×2560,而其他模型的上限仅为336×336,无法解析高分辨率文档图像。
论文地址:https://arxiv.org/pdf/2311.11810.pdf
DocPedia的性能得到了显著提升,尤其在关键信息抽取和视觉问答方面的能力上。通过论文中的示例展示,DocPedia能够理解高分辨率文档图像和自然场景图像中的指令内容,并准确提取相关的图文信息。这包括了从图像中挖掘车牌号、电脑配置等文本信息,甚至对手写文字的准确判断。
结合图像中的文本信息,DocPedia还可以利用其大模型推理能力,根据上下文分析问题,并回答图像中没有展示的扩展内容。
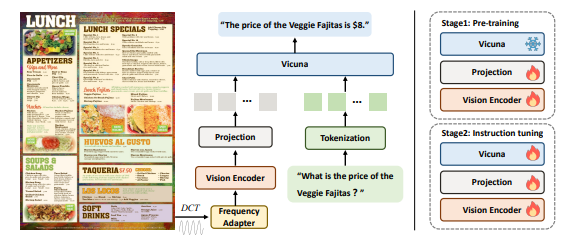
在DocPedia的训练过程中,研究团队采用了两个阶段的方法:预训练和微调。在预训练阶段,大语言模型的视觉编码器部分被优化,以使其输出与大语言模型对齐。这一阶段主要注重对感知能力的训练,包括文字和自然场景的感知。微调阶段涉及整个模型的端到端优化,并采用感知-理解联合训练策略,进一步提高了DocPedia的性能。
特别值得注意的是,DocPedia从频域的角度出发解决分辨率问题。通过提取高分辨率文档图像的DCT系数矩阵,并在不损失图文信息的前提下进行空间分辨率下采样,通过级联的频域适配器进一步进行分辨率压缩和特征提取。这种方法在将图像输入到视觉编码器之前,大大减少了token数量,提高了效率。
总体而言,DocPedia在多模态文档大模型领域取得了显著的突破,其高分辨率和优化训练策略使其在各项测试基准上均表现出色。该研究为推动多模态文档理解领域的发展提供了有力的支持。
先进的人工智能工具正在崛起,但「安全」并不是监管人工智能的最佳标准
微软于上周发布了其BingImageCreator的新版本,这是一个由OpenAI的新模型DALL-E3提供支持的AI图像生成工具。它旨在提供比之前的图像生成AI模型(如Midjourney、StableDiffusion或OpenAI自己的DALL-E2)更强大的功能,包括比以前更丰富地理解复杂用户请求的能力。站长网2023-10-16 09:51:210001腾讯云云服务器免费绑定多个ip方法
一台腾讯云云服务器绑定多个ip,并且免费使用!首先,腾讯云账户类型需要是传统账户类型(带宽非上移),请到弹性公网IP处看看是不是该账户类型。看下图,有该提示即符合要求。站长网2021-08-20 08:20:190006马斯克19天建成世界最强AI集群!10万块H100「液冷怪兽」即将觉醒
凌晨4:20,大洋彼岸的最大超算训练集群开始轰鸣。「420」也是马斯克最喜欢玩的梗,象征着自由、不受约束和反传统。马斯克频繁把「420」用在他的产品定价,公司开会时间和星舰一发射时间上等等。网友也在评论区打趣马斯克超绝仪式感,不到4:20不开工。在最新采访中,马斯克透露了更多关于新建超算和xAI模型进展:-Grok2上个月完成了训练,大约用了15KH100站长网2024-07-23 14:32:340000乐道L60将于9月上市交付 蔚来手机将适用于乐道车型
乐道汽车的CEO艾铁成近日在NIORadio直播间向公众透露了公司最新的战略规划和产品动态。他兴奋地宣布,乐道汽车的首款车型L60SUV将在今年9月正式上市并交付给期待已久的消费者。艾铁成不仅分享了L60的上市时间,还透露了接下来的几个月里,乐道将陆续公布这款车型在能耗等性能方面的详细数据,以满足消费者对于车辆性能的关注和期待。站长网2024-05-28 19:16:070000AI编程创业公司为何接连获得大额融资?
AI编程是生成式AI崛起以来最热门的赛道之一,不仅海内外大厂均有布局,而且已经诞生了数家融资额过亿,估值过10亿美元的头部创业公司。无论对于程序员还是企业客户,AI编程的本质价值是降本增效,而且它带来的效果是直接的,目前已有44%的程序员使用过AI编程软件。站长网2024-05-09 23:07:180000