全网都在模仿的「科目三」,梅西、钢铁侠、二次元小姐姐马上拿下
来自阿里的研究团队提出了一种名为 Animate Anyone 的方法,只需一张人物照片,再配合骨骼动画引导,就能生成动画视频。
最近一段时间,你可能或多或少的听到过「科目三」,摇花手、半崴不崴的脚,配合着节奏鲜明的音乐,这一舞蹈动作遭全网模仿。
如果相似的舞蹈,让 AI 生成会怎样?就像下图所展示的,不管是现代人、还是纸片人,都做着整齐划一的动作。你可能猜不到的是,这是根据一张图片生成的舞蹈视频。

人物动作难度加大,生成的视频也非常丝滑(最右边):

让梅西、钢铁侠动起来,也不在话下。还有各种动漫小姐姐。
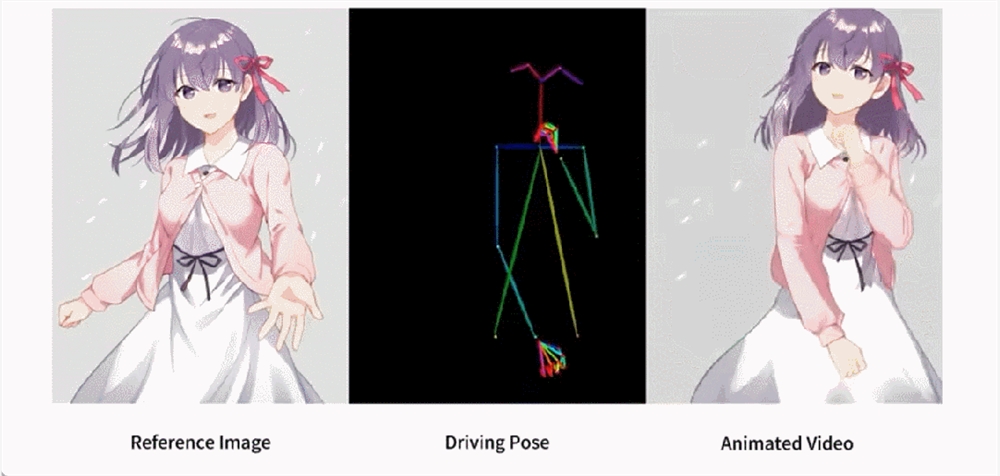
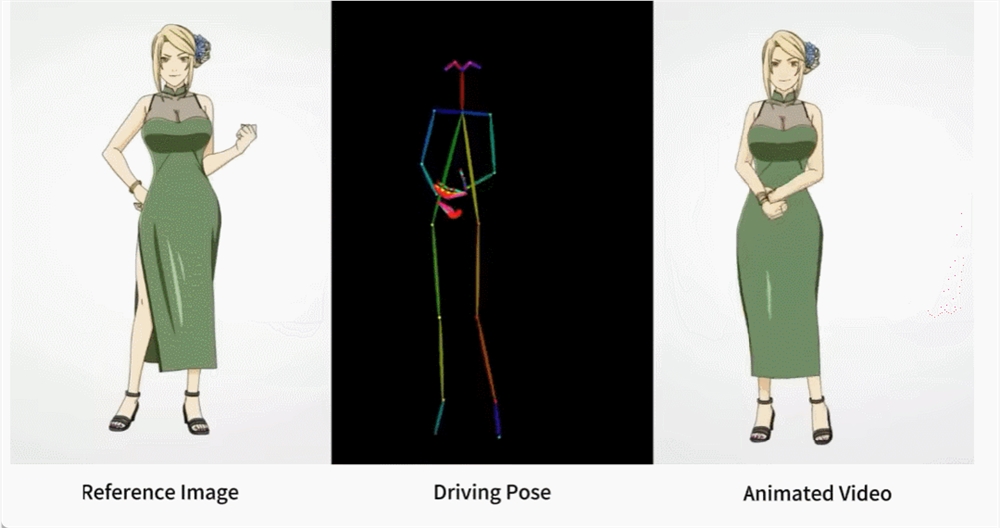
上述效果是如何做到的呢?我们接着往下看。
角色动画(Character Animation)是将源角色图像按照所需的姿态序列动画化为逼真视频的任务,具有许多潜在的应用,例如在线零售、娱乐视频、艺术创作和虚拟角色等。
从 GAN 开始,研究者一直在不断深入了解将图像进行动画化以及进行姿态迁移的探索,然而,生成的图像或视频仍然存在局部失真、细节模糊、语义不一致和时间不稳定等问题,从而阻碍了这些方法的应用。
本文,来自阿里的研究者提出了一种名为 Animate Anybody 的方法,该方法能够将角色图像转换为动画视频,而形成的视频遵循所要求的姿态序列。该研究继承了 Stable Diffusion 的网络设计和预训练权重,并修改了去噪 UNet 以适应多帧输入。

论文地址:https://arxiv.org/pdf/2311.17117.pdf
项目地址:https://humanaigc.github.io/animate-anyone/
为了保持外观一致性,该研究还引入了 ReferenceNet,它被设计为对称的 UNet 结构,用于捕获参考图像的空间细节。在 UNet 块的每个相应层,该研究使用空间 - 注意力将 ReferenceNet 的特征集成到去噪 UNet 中,这种架构使模型能够在一致的特征空间中全面学习与参考图像的关系。
为了确保姿态可控性,该研究设计了一种轻量级姿态引导器,以有效地将姿态控制信号集成到去噪过程中。为了实现时间稳定性,本文引入了时间层( temporal layer)来对多个帧之间的关系进行建模,从而在模拟连续且平滑的时间运动过程的同时保留视觉质量的高分辨率细节。
Animate Anybody 是在5K 角色视频剪辑的内部数据集上训练而成,图1显示了各种角色的动画结果。与以前的方法相比,本文的方法具有几个显着的优点:
首先,它有效地保持了视频中人物外观的空间和时间一致性。
其次,它生成的高清视频不会出现时间抖动或闪烁等问题。
第三,它能够将任何角色图像动画化为视频,不受特定领域的限制。
本文在两个特定的人类视频合成基准(UBC 时尚视频数据集和 TikTok 数据集)上进行了评估。结果显示,Animate Anybody 取得了 SOTA 结果。此外,该研究还将 Animate Anybody 方法与在大规模数据上训练的一般图像到视频方法进行了比较,结果显示 Animate Anybody 在角色动画方面展示了卓越的能力。

Animate Anybody 与其他方法的比较:

方法介绍
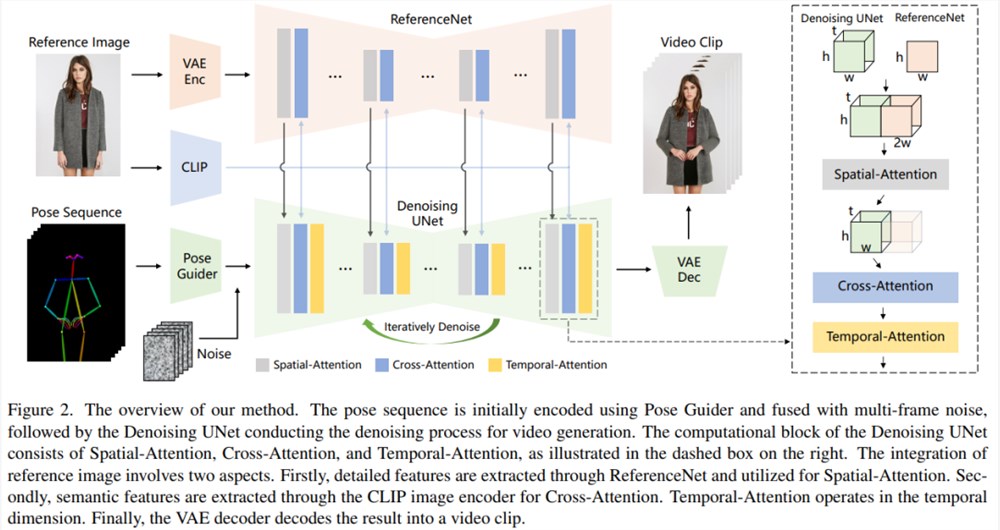
本文方法如下图2所示,网络的初始输入由多帧噪声组成。研究者基于 SD 设计来配置去噪 UNet,采用了相同的框架和块单元,并继承了来自 SD 的训练权重。具体来讲,该方法包含了三个关键组成部分,分别如下:
ReferenceNet,编码参考图像角色的外观特征;
Pose Guider(姿态引导器),编码动作控制信号以实现可控角色运动;
Temporal layer(时间层),编码时间关系以确保角色动作的连续性。
ReferenceNet
ReferenceNet 是一个参考图像特征提取网络,它的框架与去噪 UNet 大致相同,仅有时间层不同。因此,ReferenceNet 继承了与去噪 UNet 类似的原始 SD 权重,并且每个权重更新都是独立进行的。研究者解释了将 ReferenceNet 的特征集成到去噪 UNet 的方法。
ReferenceNet 的设计有两个优势。第一,ReferenceNet 可以利用原始 SD 的预训练图像特征建模能力,产生初始化良好的特征。第二,由于 ReferenceNet 与去噪 UNet 本质上具有相同的网络结构和共享初始化权重,因而去噪 UNet 可以选择性地从 ReferenceNet 中学习在同一特征空间关联的特征。
姿态引导器
轻量级的姿态引导器使用四个卷积层(4×4内核、2×2步幅、使用16、32、64、128个通道,类似于 [56] 中的条件编码器)来对齐分辨率与潜在噪声相同的姿态图像,接着处理后的姿态图像在被输入到去噪 UNet 之前添加到潜在噪声中。姿态引导器使用高斯权重进行初始化,并在最终的映射层用到了零卷积。
时间层
时间层的设计灵感来自 AnimateDiff。对于一个特征图 x∈R^b×t×h×w×c,研究者首先将它变形为 x∈R^(b×h×w)×t×c,然后执行时间注意力,即沿着维度 t 的自注意力。时间层的特征通过残差连接合并到了原始特征中,这种设计与下文的双阶段训练方法相一致。时间层专门在去噪 UNet 的 Res-Trans 块内使用。
训练策略
训练过程分为两个阶段。
第一阶段,使用单个视频帧进行训练。在去噪 UNet 中,研究者暂时排除了时间层,模型将单帧噪声作为输入。参考网络和姿态引导器也在这一阶段进行训练。参考图像是从整个视频片段中随机选取的。他们根据 SD 的预训练权重初始化去噪 UNet 和 ReferenceNet 的模型。姿态引导器使用高斯权重进行初始化,但最后的投影层除外,该层使用零卷积。VAE 的编码器和解码器以及 CLIP 图像编码器的权重都保持不变。这一阶段的优化目标是使模型在给定参考图像和目标姿态的条件下生成高质量的动画图像。
在第二阶段,研究者将时间层引入先前训练好的模型,并使用 AnimateDiff 中预先训练好的权重对其进行初始化。模型的输入包括一个24帧的视频片段。在这一阶段,只训练时间层,同时固定网络其他部分的权重。
实验与结果
定性结果:如图3显示,本文方法可以制作任意角色的动画,包括全身人像、半身人像、卡通人物和仿人角色。该方法能够生成高清晰度和逼真的人物细节。即使在大幅度运动的情况下,它也能与参考图像保持时间上的一致性,并在帧与帧之间表现出时间上的连续性。

时尚视频合成。时尚视频合成的目的是利用驱动姿态序列将时尚照片转化为逼真的动画视频。实验在 UBC 时尚视频数据集上进行,该数据集由500个训练视频和100个测试视频组成,每个视频包含约350个帧。定量比较见表1。在结果中可以发现,本文方法优于其他方法,尤其是在视频度量指标方面表现出明显的领先优势。
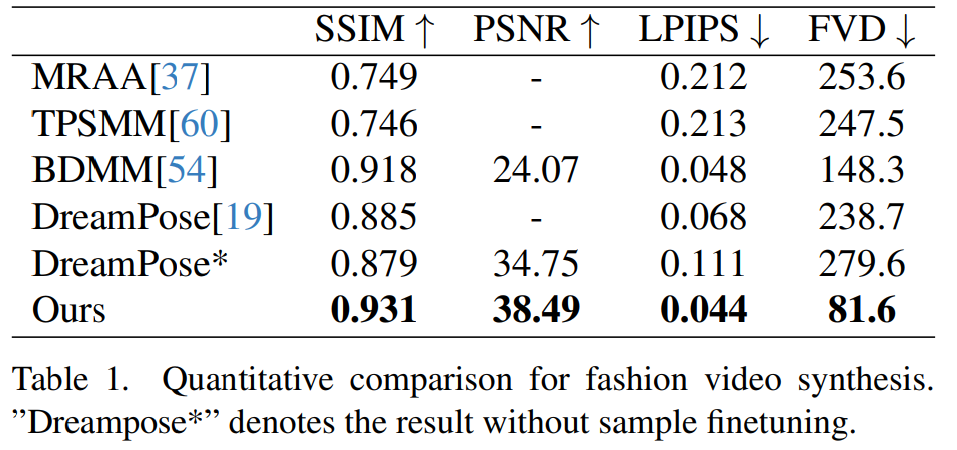
定性比较如图4所示。为了进行公平比较,研究者使用 DreamPose 的开源代码获得了未进行样本微调的结果。在时尚视频领域,对服装细节的要求非常严格。然而,DreamPose 和 BDMM 生成的视频无法保持服装细节的一致性,并在颜色和精细结构元素方面表现出明显的误差。相比之下,本文方法生成的结果能更有效保持服装细节的一致性。

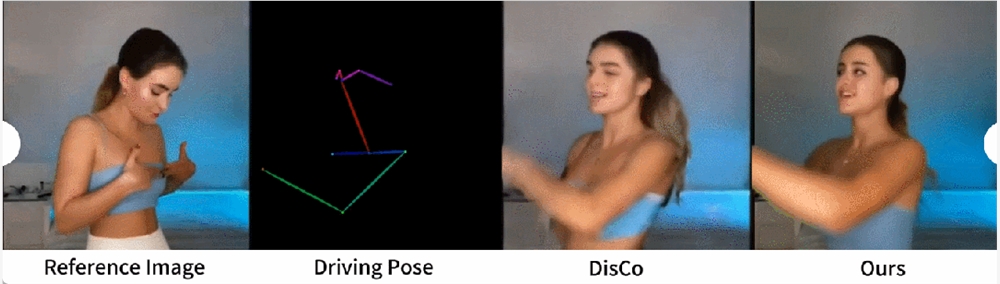
人类舞蹈生成。人类舞蹈生成聚焦于将现实舞蹈场景图像进行动画处理。研究者们使用了 TikTok 数据集,其中包括340个训练视频和100个测试视频。按照 DisCo 的数据集划分方法,使用利用相同的测试集,其中包含10个 TikTok 风格的视频,研究者进行了定量比较,见表2。本文方法取得了最佳结果。为了增强泛化能力,DisCo 结合了人类属性预训练,利用大量图像对进行模型预训练。相比之下,研究者训练只在 TikTok 数据集上进行,结果优于 DisCo。
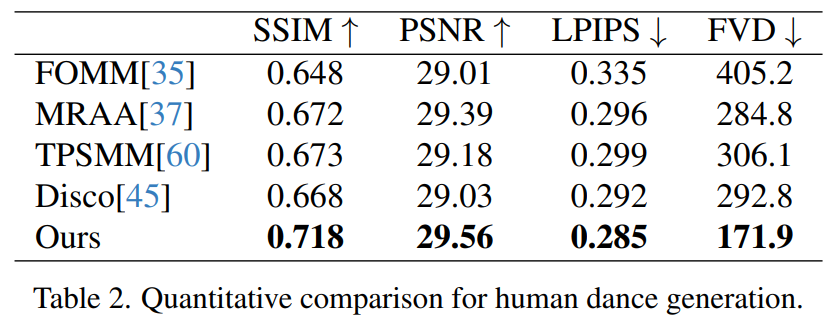
图5中展示了与 DisCo 的定性比较。考虑到场景的复杂性,DisCo 的方法需要额外使用 SAM 来生成人类前景掩码。相反,本文方法表明,即使没有明确的人体掩码学习,模型也能从被摄体的运动中掌握前景与背景的关系,而无需事先进行人体分割。此外,在复杂的舞蹈序列中,该模型在保持整个动作的视觉连续性方面表现突出,并在处理不同的角色外观方面表现出更强的稳健性。

图像 - 视频的通用方法。目前,许多研究都提出了基于大规模训练数据、具有强大生成能力的视频扩散模型。研究者选择了两种最著名、最有效的图像 - 视频方法进行比较:AnimateDiff 和 Gen2。由于这两种方法不进行姿态控制,因此研究者只比较了它们保持参考图像外观保真度的能力。如图6所示,当前的图像 - 视频方法在生成大量角色动作方面面临挑战,并且难以在视频中保持长期的外观一致性,从而阻碍了对一致角色动画的有效支持。

了解更多内容,请参考原论文。
OpenAI首席执行官表示监管可能会出错但不必担心
文章概要:1.许多国家计划进行人工智能监管,英国将主办全球AI安全峰会,关注前沿技术的风险和国际框架支持。2.OpenAI首席执行官SamAltman在担忧人工智能快速发展的背景下表示,监管可能出现错误,但不应过于担心。3.Altman还强调了对强大系统的有针对性监管的必要性,同时警告不应低估监管的必要性。站长网2023-09-25 18:10:5800005月新规来了!互联网广告新限制:关闭弹出广告不得经两次以上点击
快科技4月29日消息,今天五一假期已经开启,假期中就要正式进入5月份了,同事也有一大批新规即将开始执行。其中最受关注之一就是互联网广告新规,将于5月1日开始实施。市场监管总局发布的《互联网广告管理办法》(以下简称《办法》),进一步明确了广告主、互联网广告经营者和发布者、互联网信息服务提供者的责任;积极回应社会关切,对人民群众反映集中的弹出广告、开屏广告、利用智能设备发布广告等行为作出规范。0002从一场赛事看语音直播的火热:主播拼才艺,机构求破圈
在抖音年度赛事嘉年华开启之前,一场面向语音独立赛道的年度赛事率先点燃了战火。近日,抖音直播面向语音赛道举办的“声动时刻最强音”落下帷幕。这场赛事活动为期半个月,最终有20个语音厅、10个语音歌手突围。尽管不露脸,但这场比赛的精彩程度完全不逊色于视频主播的比赛。不同风格的语音歌手们轮番上阵,或节奏十足,或深情动人,俨然是“抖音版好声音”。0000AI视野:ChatGPT和API发生重大中断;GPTs分阶段推出计划延迟;中国第二批11个大模型备案获批;阿里将开源720亿参数大模型
📰🤖📢AI新鲜事ChatGPT和API发生重大中断!11月9日凌晨,OpenAI在官网发布,ChatGPT和API发生重大中断,导致全球所有用户无法正常使用,宕机时间超过2小时。OpenAI已经找到问题所在并进行了修复,但仍然不稳定,会继续进行安全监控。【AiBase提要】⚠️宕机持续时间超过2小时🔍OpenAI已找到并修复问题🔄系统仍然不稳定,继续进行安全监控站长网2023-11-09 15:43:000000AI视野:大模型最快推理芯片Groq登场;真人视频冒充Sora;Stable Diffusion WebUI Forge推出;字节辟谣推出中文版Sora
欢迎来到【AI视野】栏目!这里是你每天探索人工智能世界的指南,每天我们为你呈现AI领域的热点内容,聚焦开发者,助你洞悉技术趋势、了解创新AI产品应用。新鲜AI产品点击了解:https://top.aibase.com/📰🤖📢AI新鲜事大模型最快推理芯片一夜易主Groq每秒可达500tokens【AiBase提要:】⭐️Groq推出的大模型推理芯片性能突出站长网2024-02-20 15:55:290000











