使用PyTorch加速生成式 AI模型
PyTorch 团队发布了一篇名为《Accelerating Generative AI with PyTorch II: GPT, Fast》的博文,重点介绍如何使用纯原生 PyTorch 加速生成式 AI 模型。
正如最近在PyTorch 开发者大会上宣布的那样,PyTorch 团队从头开始编写了一个 LLM,其速度几乎比基线快10倍,并且没有损失准确性,所有这些都使用本机 PyTorch 优化。团队利用了广泛的优化,包括:
Torch.compile:PyTorch 模型的编译器
GPU 量化:通过降低精度运算来加速模型
推测性解码:使用小型“草案”模型来预测大型“目标”模型的输出,加速大模型
张量并行:通过在多个设备上运行模型来加速模型。
而且,更令人惊讶的是,他们可以用不到1000行的本机 PyTorch 代码来完成此任务。
具体步骤如下:
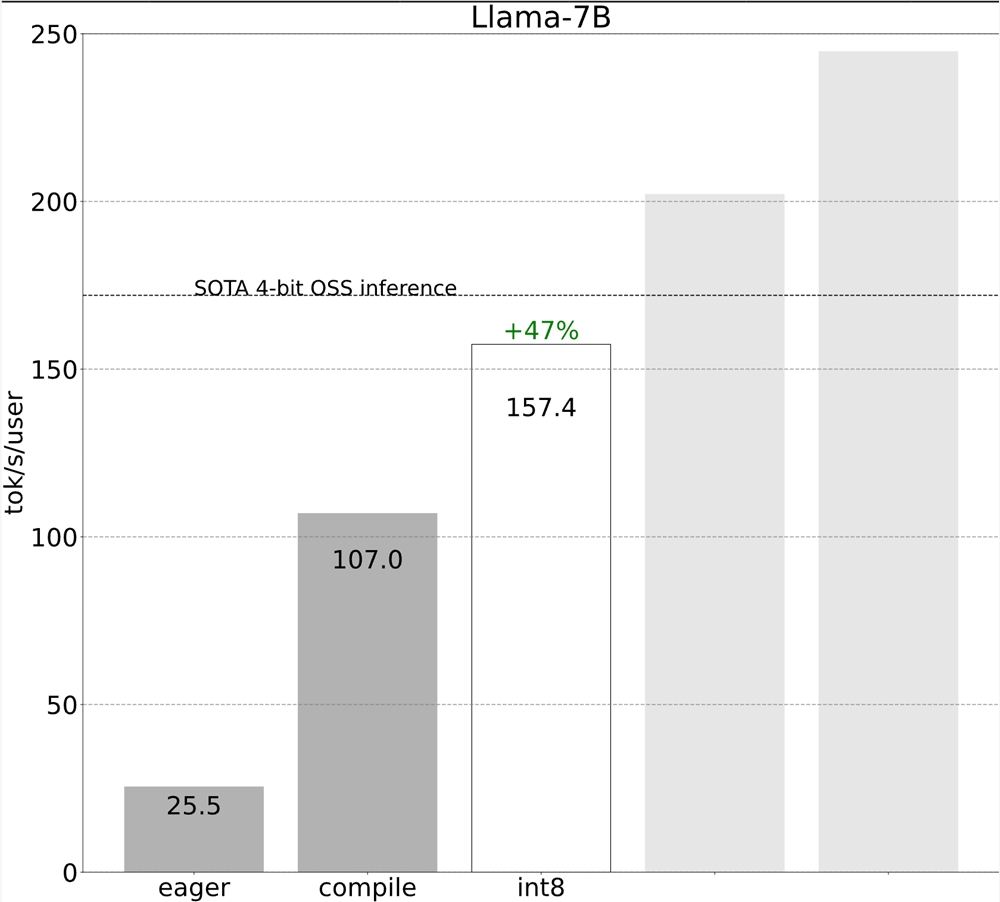
第1步:通过 TORCH.COMPILE 和静态 KV 缓存(107.0TOK/S)减少 CPU 开销
Torch.compile 允许我们将更大的区域捕获到单个编译区域中,特别是在使用 mode=”reduce-overhead” 运行时,对于减少 CPU 开销非常有效。在这里,我们还指定 fullgraph=True,它验证模型中没有“图形中断”(即 torch.compile 无法编译的部分)。换句话说,它确保 torch.compile 充分发挥其潜力。
要应用它,我们只需用它包装一个函数(或模块)即可。
torch.compile(decode_one_token,mode="reduce-overhead",fullgraph=True)
然而,这里有一些细微差别,使得人们通过将 torch.compile 应用于文本生成来获得显着的性能提升有些不简单。
第一个障碍是 kv 缓存。kv-cache 是一种推理时间优化,可缓存为先前标记计算的激活(请参阅此处以获取更深入的解释)。然而,当我们生成更多令牌时,kv-cache 的“逻辑长度”就会增长。由于两个原因,这是有问题的。一是每次缓存增长时重新分配(和复制!)kv-cache 的成本非常高。另一个问题是,这种动态使得减少开销变得更加困难,因为我们不再能够利用 cudagraphs 等方法。
为了解决这个问题,我们使用“静态”kv-cache,这意味着我们静态分配 kv-cache 的最大大小,然后屏蔽掉计算的注意力部分中未使用的值。

第二个障碍是预填充阶段。Transformer 文本生成最好被视为一个两阶段过程:1. 处理整个提示的预填充,以及2. 自回归生成每个标记的解码。
尽管一旦 kv-cache 静态化,解码就可以完全静态化,但由于提示长度可变,预填充阶段仍然需要更多的动态性。因此,我们实际上需要使用单独的编译策略来编译这两个阶段。

虽然这些细节有点棘手,但实际实现起来一点也不困难(参见 gpt-fast)!而且性能的提升是巨大的。
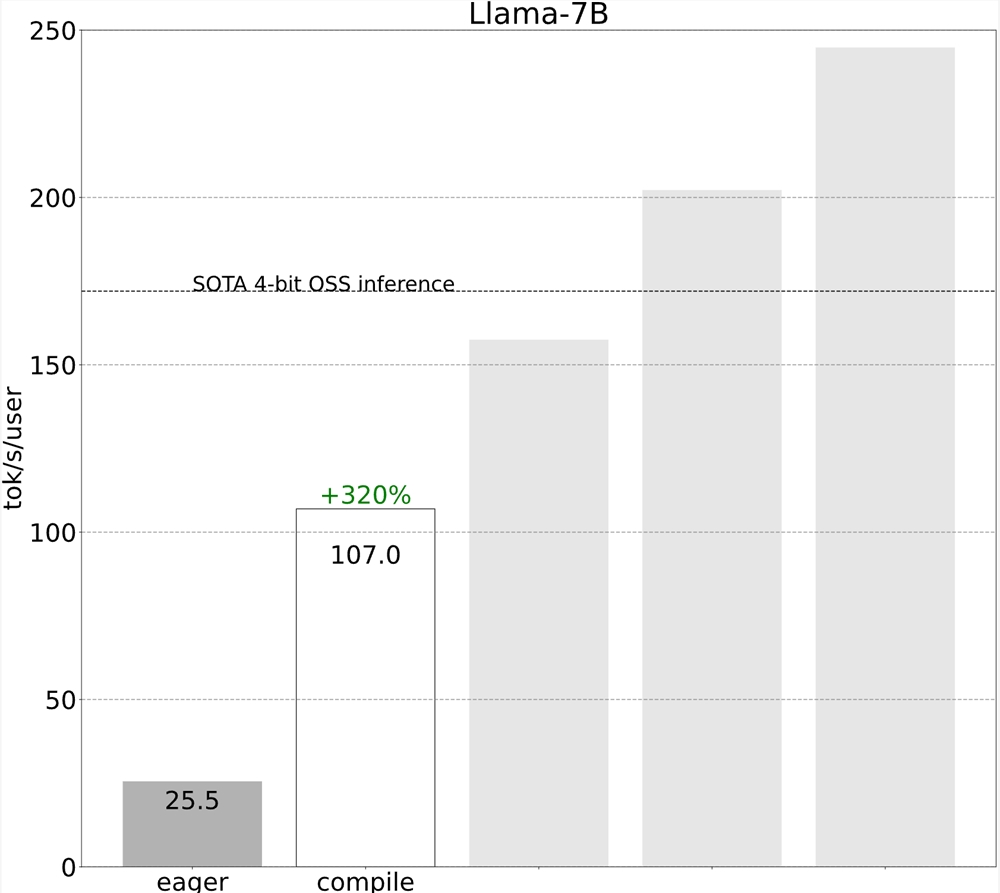
突然之间,我们的性能提高了4倍以上!当工作负载受到开销限制时,这种性能提升通常很常见。
步骤2:通过 INT8仅权重量化缓解内存带宽瓶颈(157.4TOK/S)
那么,鉴于我们已经看到应用 torch.compile 带来了巨大的加速,是否有可能做得更好?思考这个问题的一种方法是计算我们与理论峰值的接近程度。在这种情况下,最大的瓶颈是将权重从 GPU 全局内存加载到寄存器的成本。换句话说,每次前向传递都要求我们“接触”GPU 上的每个参数。那么,理论上我们能够以多快的速度“触及”模型中的每个参数?
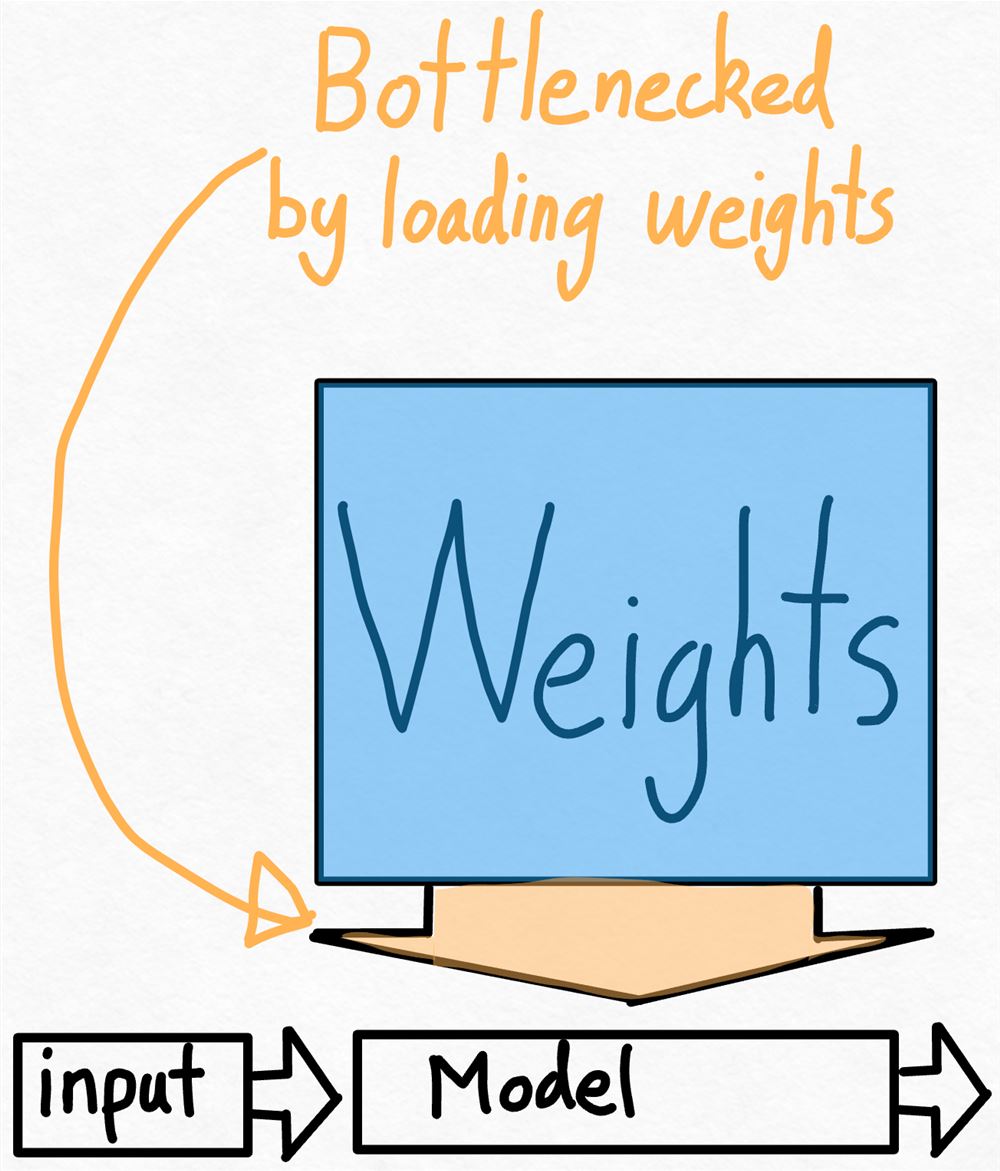
为了衡量这一点,我们可以使用模型带宽利用率(MBU)。这衡量了我们在推理过程中能够使用的内存带宽的百分比。
计算它非常简单。我们只需获取模型的总大小(# params * 每个参数的字节数)并将其乘以每秒可以进行的推理数量。然后,我们将其除以 GPU 的峰值带宽即可得到 MBU。

例如,对于我们上面的情况,我们有一个7B 参数模型。每个参数都存储在 fp16中(每个参数2个字节),我们实现了107个令牌/秒。最后,我们的 A100-80GB 理论内存带宽为2TB/s。
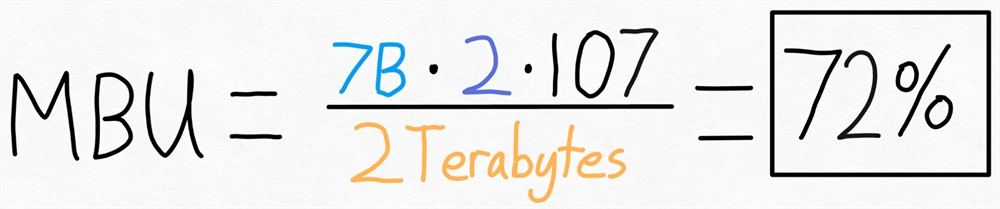
将所有这些放在一起,我们得到 **72% MBU!**这相当不错,考虑到即使只是复制内存也很难突破85%。
但是……这确实意味着我们非常接近理论极限,并且我们显然在从内存加载权重方面遇到了瓶颈。我们做什么并不重要——如果不以某种方式改变问题陈述,我们可能只能再争取10% 的性能。
让我们再看一下上面的等式。我们无法真正改变模型中参数的数量。我们无法真正改变 GPU 的内存带宽(好吧,无需支付更多的钱)。但是,我们可以更改每个参数存储的字节数!

因此,我们得出了下一个技术——int8量化。这里的想法很简单。如果从内存加载权重是我们的主要瓶颈,为什么我们不把权重做得更小呢?
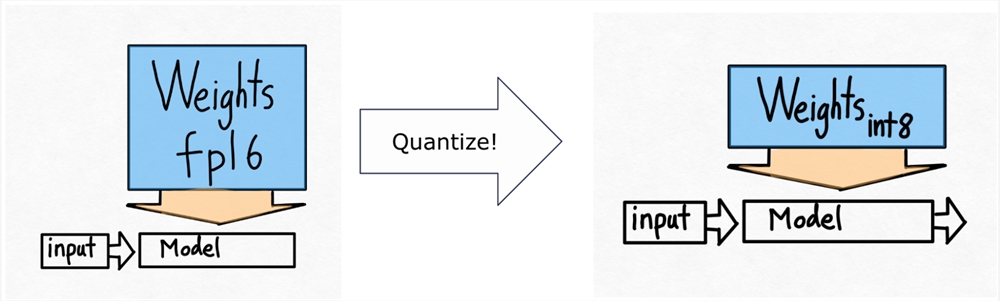
请注意,这仅量化权重 - 计算本身仍然在 bf16中完成。这使得这种形式的量化易于应用,并且精度几乎没有降低。
此外,torch.compile还可以轻松生成int8量化的高效代码。让我们再次看看上面的基准测试,这次包含了仅 int8权重量化。

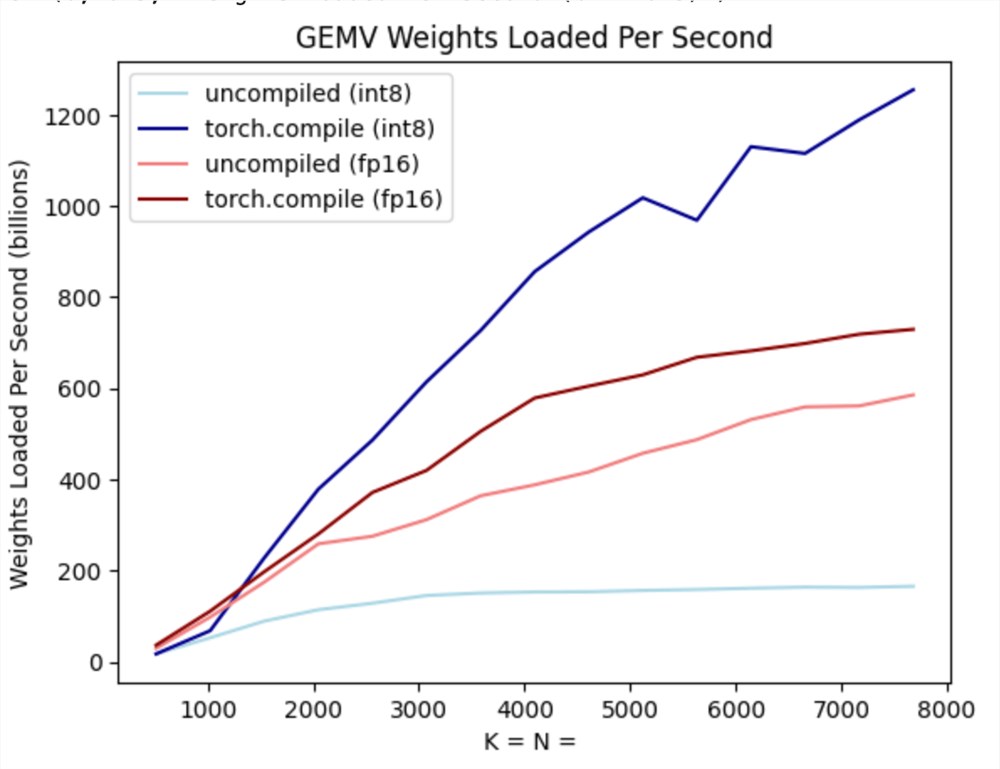
从深蓝色线(torch.compile int8)可以看出,使用torch.compile int8仅权重量化时,性能有显着提升!而且,浅蓝色线(没有torch.compile int8)实际上甚至比fp16性能还差很多!这是因为为了利用 int8量化的性能优势,我们需要融合内核。这显示了 torch.compile 的好处之一 - 可以为用户自动生成这些内核!
将 int8量化应用于我们的模型,我们看到性能提高了50%,达到157.4个令牌/秒!
第3步:使用推测解码重新构建问题
即使使用了量化等技术,我们仍然面临另一个问题。为了生成100个代币,我们必须加载权重100次。
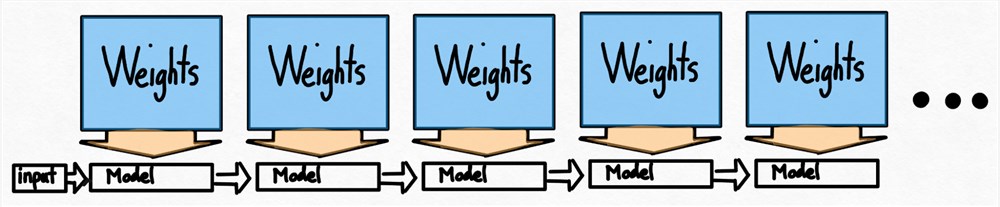
即使权重被量化,我们仍然必须一遍又一遍地加载我们的权重,对于我们生成的每个令牌一次!有没有办法解决?
乍一看,答案似乎是否定的——我们的自回归一代存在严格的序列依赖性。然而,事实证明,通过利用推测解码,我们能够打破这种严格的串行依赖性并获得加速!
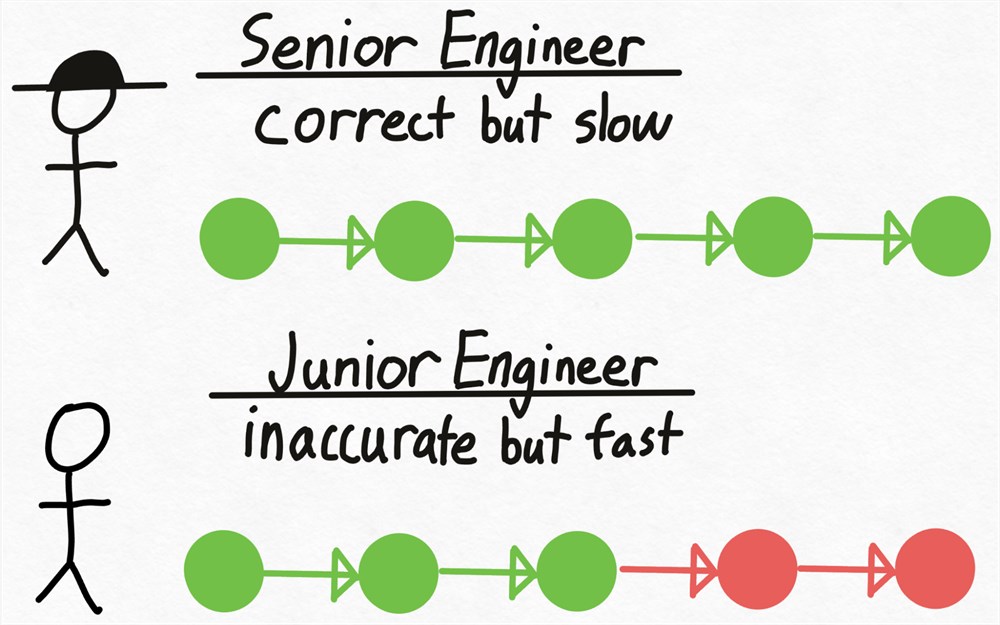
想象一下,您有一位高级工程师(称为 Verity),他做出了正确的技术决策,但编写代码的速度相当慢。然而,您还有一名初级工程师(称为 Drake),他并不总是做出正确的技术决策,但可以比 Verity 更快(而且更便宜!) 编写代码。我们如何利用 Drake(初级工程师)更快地编写代码,同时确保我们仍然做出正确的技术决策?
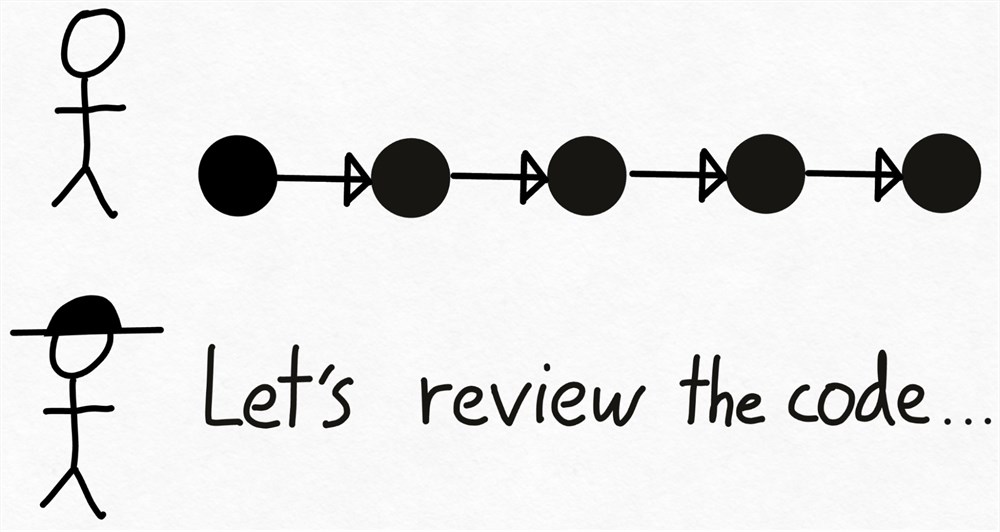
首先,Drake 经历了编写代码的劳动密集型过程,并在此过程中做出技术决策。接下来,我们将代码交给 Verity 进行审查。
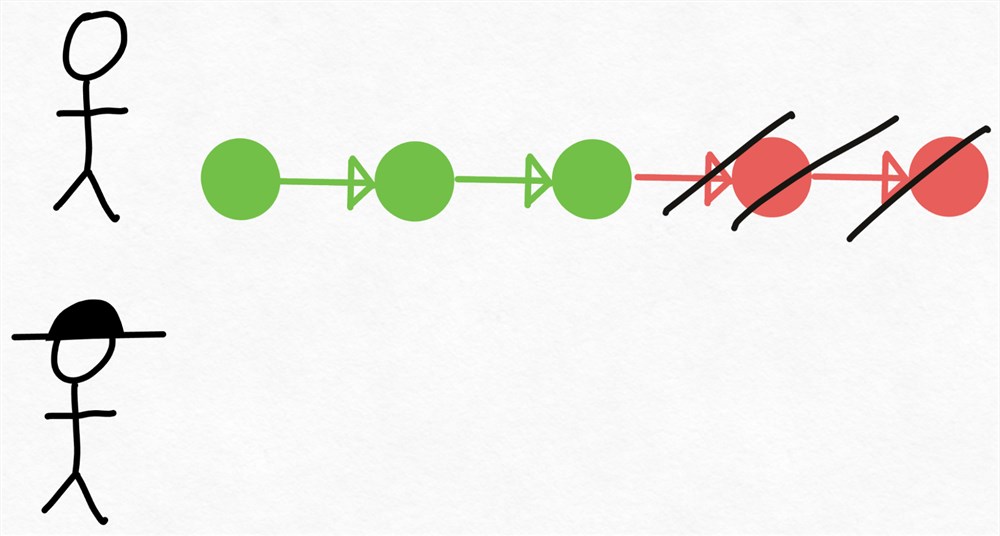
在审查代码后,Verity 可能会认为 Drake 做出的前3个技术决策是正确的,但后2个需要重做。因此,Drake 回去,放弃了他最后的2个决定,并从那里重新开始编码。
值得注意的是,虽然 Verity(高级工程师)只看过一次代码,但我们能够生成3段与她编写的代码相同的经过验证的代码!因此,假设 Verity 能够比她自己编写这3段代码更快地审查代码,那么这种方法就会领先。
在变压器推理的背景下,Verity 将由更大的模型发挥作用,我们希望其输出用于我们的任务,称为验证器模型。同样,Drake 将由一个较小的模型来扮演,该模型能够比较大的模型(称为草稿模型)更快地生成文本。因此,我们将使用草稿模型生成8个令牌,然后使用验证者模型并行处理所有8个令牌,并丢弃不匹配的令牌。
如上所述,推测解码的一个关键特性是它不会改变输出的质量。只要使用草稿模型生成令牌 验证令牌所需的时间少于生成这些令牌所需的时间,我们就会领先。
在原生 PyTorch 中完成这一切的一大好处是,这项技术实际上非常容易实现!这是完整的实现,大约50行原生 PyTorch。

尽管推测性解码保证我们在数学上与常规生成相比具有相同的结果,但它确实具有运行时性能根据生成的文本以及草稿和验证器模型的对齐程度而变化的属性。例如,当运行 CodeLlama-34B CodeLlama-7B 时,我们能够在生成代码时获得2倍的令牌/秒提升。另一方面,当使用 Llama-7B TinyLlama-1B 时,我们只能获得大约1.3倍的令牌/秒提升。
步骤4:使用 INT4量化和 GPTQ (202.1TOK/S) 进一步减小权重的大小
当然,如果将权重从16位减少到8位可以通过减少我们需要加载的字节数来实现加速,那么将权重减少到4位将导致更大的加速!
不幸的是,当权重减少到4位时,模型的准确性开始成为一个更大的问题。从我们的初步评估中,我们看到虽然使用仅 int8权重量化没有明显的精度下降,但使用仅 int4权重量化却有。
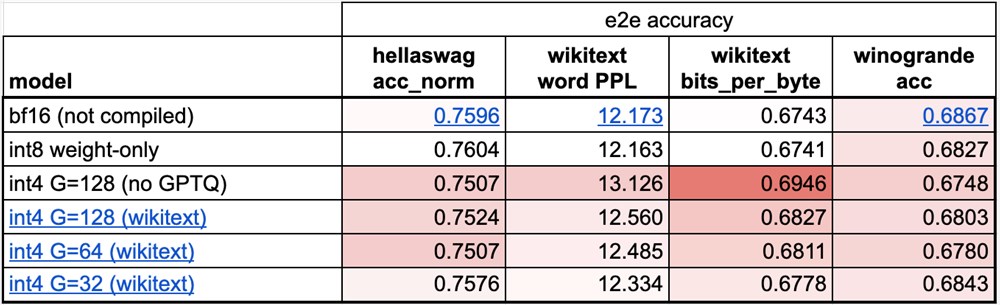
我们可以使用两个主要技巧来限制 int4量化的精度下降。
第一个是拥有更细粒度的缩放因子。考虑缩放因子的一种方法是,当我们有量化张量表示时,它处于浮点张量(每个值都有缩放因子)和整数张量(没有值有缩放因子)之间的滑动比例。例如,对于 int8量化,我们每行都有一个缩放因子。然而,如果我们想要更高的精度,我们可以将其更改为“每32个元素一个缩放因子”。我们选择组大小为32来最小化准确性下降,这也是社区中的常见选择。
另一种是使用比简单地对权重进行舍入更先进的量化策略。例如,GPTQ等方法利用示例数据来更准确地校准权重。在本例中,我们基于 PyTorch 最近发布的torch.export在存储库中原型化了 GPTQ 的实现。
此外,我们需要将 int4反量化与矩阵向量乘法融合的内核。在这种情况下,torch.compile 不幸地无法从头开始生成这些内核,因此我们在 PyTorch 中利用一些手写的 CUDA 内核。
这些技术需要一些额外的工作,但将它们组合在一起会产生更好的性能!
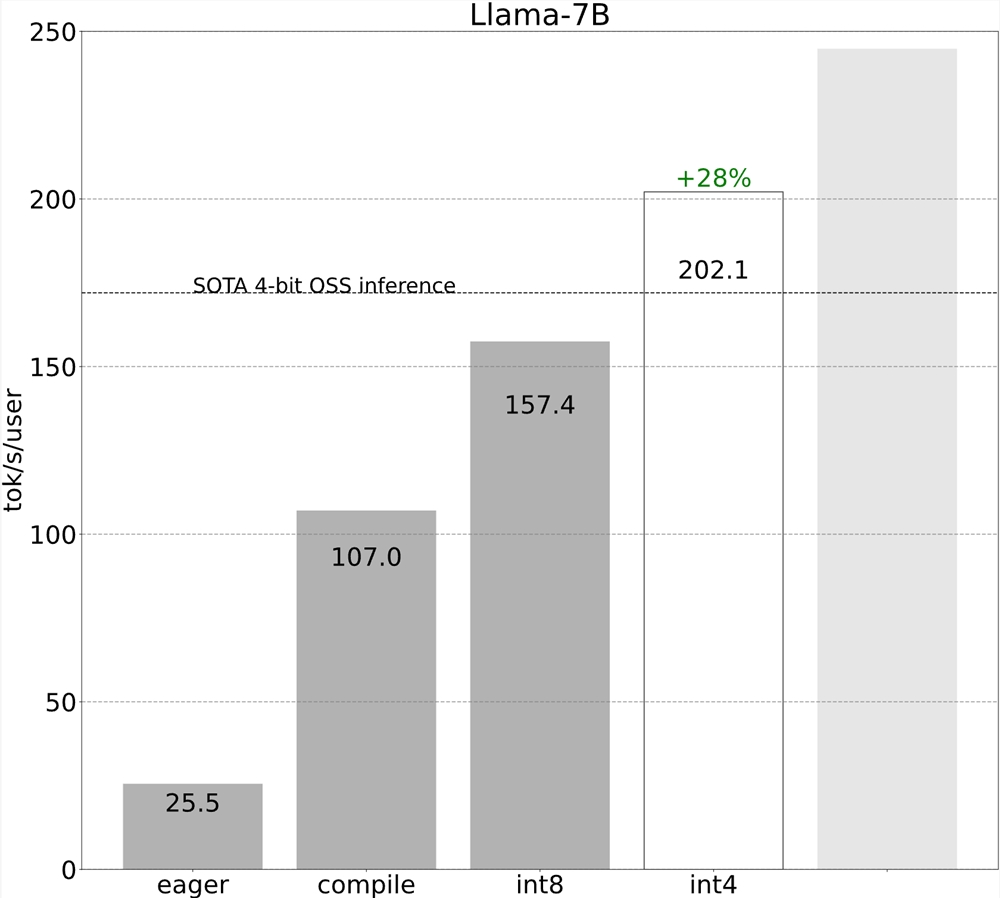
第5步:将所有内容组合在一起(244.7TOK/S)
最后,我们可以将所有技术组合在一起以获得更好的性能!
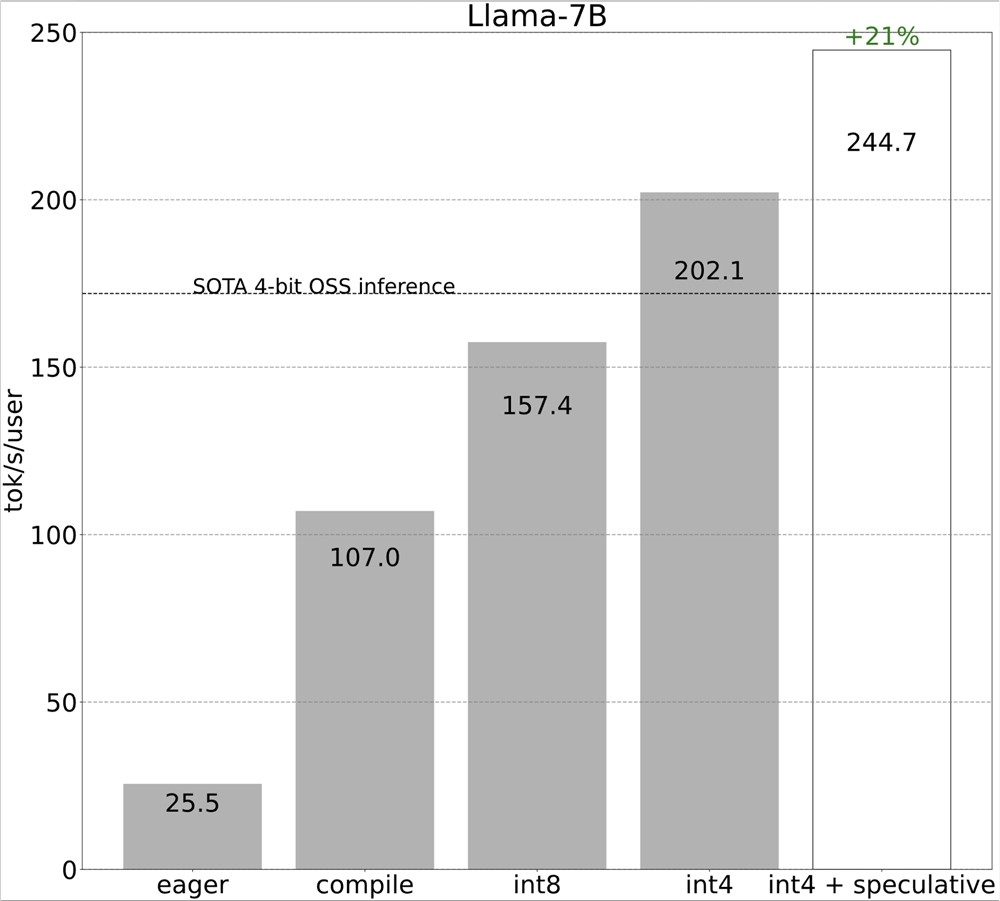
第6步:使用张量并行性
到目前为止,我们一直限制自己在单个 GPU 上最大限度地减少延迟。然而,在许多设置中,我们可以使用多个 GPU。这使我们能够进一步改善延迟!
为了直观地了解为什么这可以让我们改善延迟,让我们看一下 MBU 的先验方程,特别是分母。在多个 GPU 上运行使我们能够获得更多的内存带宽,从而获得更高的潜在性能。
至于选择哪种并行策略,请注意,为了减少一个示例的延迟,我们需要能够同时在更多设备上利用内存带宽。这意味着我们需要将一个令牌的处理拆分到多个设备上。换句话说,我们需要使用张量并行性。
幸运的是,PyTorch 还提供了与 torch.compile 组合的张量并行的低级工具。我们还在开发用于表达张量并行性的更高级别的 API,请继续关注!
然而,即使没有更高级别的 API,添加张量并行性实际上仍然很容易。我们的实现只有150行代码,并且不需要任何模型更改。

我们仍然能够利用前面提到的所有优化,所有这些优化都可以继续与张量并行性组合。将这些组合在一起,我们能够以55个令牌/秒的速度为 Llama-70B 提供 int8量化服务!
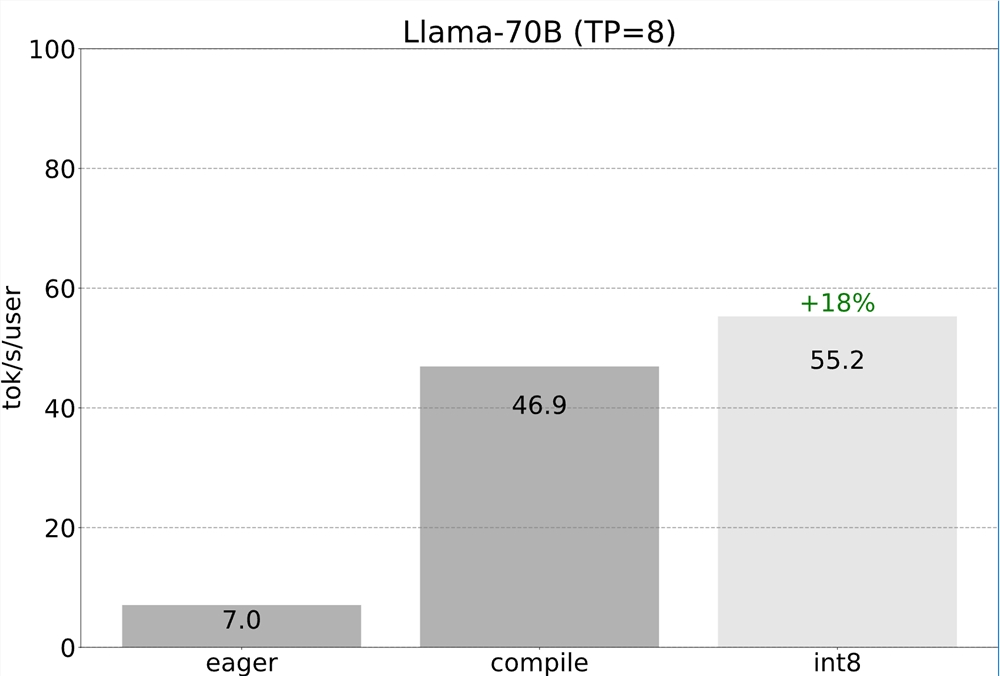
结论
让我们看看我们能够实现什么目标。
简单性:忽略量化,model.py(244LOC) generate.py(371LOC) tp.py(151LOC)得出766LOC,实现快速推理 推测解码 张量并行。性能:使用 Llama-7B,我们能够使用编译 int4Quant 推测解码来达到241tok/s。借助 llama-70B,我们还能够引入张量并行性以达到80tok/s。这些都接近或超过 SOTA 性能数据!
PyTorch 始终保持简单性、易用性和灵活性。然而,使用 torch.compile,我们也可以提高性能。
代码地址: https://github.com/pytorch-labs/gpt-fast
Meta承诺在Facebook和Instagram上标注AI生成的图像
**划重点:**1.🔍Facebook和Instagram用户将在其社交媒体上看到AI生成图像的标签,这是科技行业为区分真实与虚假而发起的广泛倡议的一部分。2.🔍Meta表示正在与行业合作伙伴共同制定技术标准,以便更容易识别由人工智能工具生成的图像,最终将包括视频和音频。3.🔍在AI生成的内容愈发容易制作和传播的当下,Meta的举措被认为是对在线虚假内容问题的认真回应。站长网2024-02-07 10:38:480000李诞小卖部开张,谁在瓜分李佳琦的流量遗产?
李诞最近很火,不是因为脱口秀综艺回温,是他在小红书开了一间小卖部。近三个月来,李诞以小卖部老板的名义在小红书直播了25场,每场直播必登小红书买手榜TOP1。小卖部既卖跟他一贯酒鬼人设相符的果酒、啤酒、葡萄酒,也卖过跟他八竿子打不着关系的女性内衣、美甲,但无论如何,这些货都让李诞给卖出去了。站长网2024-08-19 09:18:440000调协大模型时代存算矛盾的HBM,如何入局其中寻找机会?
近日,HBM的热度不可谓不高,无论是相关半导体大厂“激进”扩产的计划,还是产品供不应求的消息,都将这个内存领域的“新”技术,推到了资本市场与相关投资者的眼前。在相关大厂的扩产方面,两大存储芯片巨头持续加码:三星、SK海力士拟将HBM产量提高至2.5倍的消息曝出,使得HBM概念股倍受市场关注。站长网2023-12-20 12:06:270001Gorq推出iOS应用 支持Llama3、Gemma等
Gorq的iOS应用已经推出,旨在为用户提供快速高效的输出服务,该应用支持的模型有Llama38B、70B、Llama270B、Mixtral8X7B、Gemma7B。安装地址:https://testflight.apple.com/join/Y9X0wGsi站长网2024-04-22 10:59:440000巨人网络称游戏 + AI布局将在三季度公布成果
巨人网络在近日的对外交流活动中表示,公司“游戏AI”布局将在今年三季度首见成果,目前AI工具已在公司内部广泛应用,已能明显看到降本增效的作用,但“降本”不是公司首要目的,不会为此裁员。巨人网络还表示,公司使用AI工具的最大效果是提升了人效,以征途团队为例,随着AI模型的应用,美术人效提升了5至10倍。站长网2023-05-10 08:45:270000