研究人员发布Starling-7B:基于AI反馈的大语言模型 媲美GPT-3.5
**划重点:**
1. 🚀 **RLAIF技术介绍:** Starling-7B采用了基于AI反馈的强化学习(RLAIF),通过优化Openchat3.5和Mistral-7B而成。
2. 📊 **性能卓越:** 在MT-Bench和AlpacaEval两项基准测试中,Starling-7B表现出色,对比其他模型的性能提升引人瞩目。
3. 🔄 **迈向人性化:** RLAIF主要改善了模型的实用性和安全性,未来计划通过引入高质量的人工反馈数据,更好地满足人类需求。
UC伯克利的研究人员最近发布了Starling-7B,这是一款基于AI反馈强化学习(RLAIF)的开放式大语言模型(LLM)。该模型基于精调的Openchat3.5,并继承了Mistral-7B的特性。
在RLAIF中,研究人员借助其他AI模型的反馈来训练Starling-7B,以提升其聊天机器人响应的实用性和安全性。与以往ChatGPT中通过人类反馈进行的强化学习(RLHF)相比,RLAIF更具成本效益,速度更快,透明度更高,且可扩展性更强。
为了使用RLAIF训练模型,研究人员创建了Nectar数据集,其中包含183,000个聊天提示,每个提示有七个响应,总计3.8百万个成对比较。响应来自不同的模型,包括GPT-4、GPT-3.5-instruct、GPT-3.5-turbo、Mistral-7B-instruct和Llama2-7B。研究人员通过GPT-4对合成响应进行评分,并采用独特方法规避了GPT-4的偏见,将第一和第二响应评分最高。
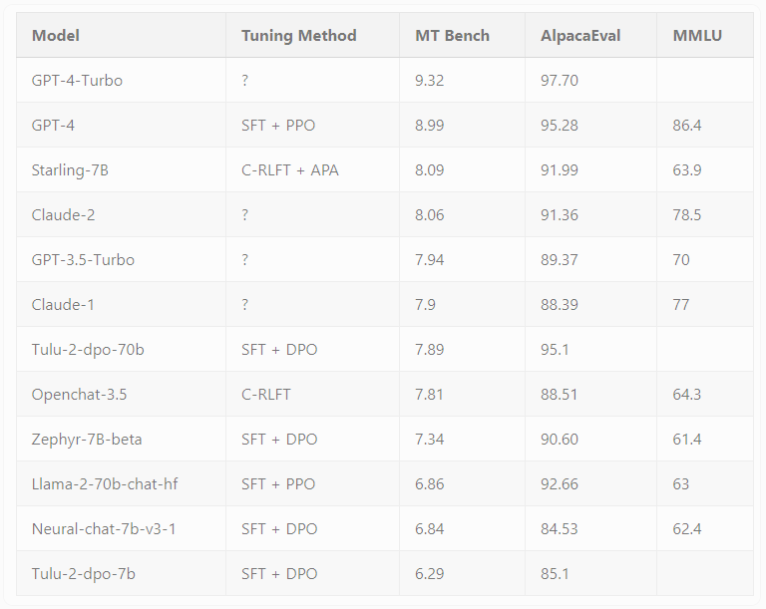
Starling-7B在两个基准测试,MT-Bench和AlpacaEval中表现卓越。Starling-7B 在 MT-Bench 中的表现优于除 OpenAI 的 GPT-4和GPT-4Turbo之外的大多数模型,并且在 AlpacaEval 中取得了与 Claude2或 GPT-3.5等商业聊天机器人相当的结果。与普通 Openchat3.5相比,在 MT-Bench 中,分数从7.81增加到8.09,在 AlpacaEval 中,分数从88.51% 增加到91.99%。研究人员指出,RLAIF主要改善了模型的实用性和安全性,但并未影响其回答基于知识、数学或编码的问题的基本能力。
虽然基准测试结果在实际应用中有一定限制,但对于RLAIF的应用来说,结果仍然令人鼓舞。研究人员指出,下一步可能是通过引入高质量的人工反馈数据扩充Nectar数据集,以更好地调整模型以满足人类需求。
Starling-7B展示了AI反馈在强化学习中的潜力,为构建更符合人类喜好的模型打开了新的可能性。研究人员强调,尽管Starling-7B在一些需要推理或数学任务上仍存在困难,并有幻觉倾向,但其性能仍然可圈可点。
研究人员已经发布了Nectar数据集、与之相关的Starling-RM-7B-alpha奖励模型以及基于该数据集训练的Starling-LM-7B-alpha语言模型,这些可以在Hugging Face上获得。他们计划在不久的将来发布代码和论文,供研究使用。对于对模型进行测试,读者可以参与聊天机器人竞技场。
项目网址:https://huggingface.co/berkeley-nest/Starling-LM-7B-alpha
李想:理想汽车四季度月交付突破4万大关
近日,理想汽车在官方微博上分享了一段央视记者探访其常州智能制造基地的报道片段。视频中,理想汽车制造负责人李斌表示,该厂的产能升级已经完成。随后,理想汽车CEO李想在社交媒体上表示,公司的目标是在第四季度将交付量提升至每月4万辆。站长网2023-10-09 16:34:570000专家表示,人工智能助推仇恨内容上升
划重点:1.📈人工智能技术使得仇恨内容和误导信息在网上迅速增加。2.🌐AI生成的仇恨内容越来越多,对社会产生了担忧。3.💡专家呼吁政府采取行动,制定相关法规和监管措施。根据加拿大广播公司(CBC)的报道,专家们表示,人工智能技术使得仇恨内容和误导信息在网上迅速增加。站长网2024-05-27 16:34:310000西部数据网络安全事件后服务已恢复,公司发布攻击事件新进展
今年三月,数据存储领域的巨头西部数据(WesternDigital)遭受黑客攻击,今天该公司发表的公告称,受到影响的各项服务目前已恢复正常运转,并且正在积极与受影响的客户联系,开展相关后续事宜。西部数据称,未经授权方已获得对公司多个系统的访问权限,公司已断开系统与公共互联网的连接来保护业务。未授权方获取了用于在线商店的数据库副本,包括客户个人信息、加密散列和加盐密码以及部分信用卡号。站长网2023-05-06 14:33:510000OpenAI:ChatGPT安卓版APP已可在所有支持国家和地区使用
OpenAI宣布,安卓版ChatGPT现在可以在所有支持ChatGPT的国家和地区使用。安卓版ChatGPT于7月26日推出,率先在美国、巴西、孟加拉国等地区上架,并在两天后扩展到英国、法国等16个国家和地区。在此之前,该应用程序已经在5月份登陆iOS平台。站长网2023-08-01 08:26:300000在小红书,为什么品牌知行合一有难度?
小红书种草,全网成交。这是长期以来,品牌默认的一个生意增长结果。只不过,这句话更像是一种感官或者印象描述,不是公式或数据验证。所以与认知并存的是,长期以来品牌和小红书都在各自做着关于商业化的同一道数据证明题。0000