上海AI实验室、Meta联合开发开源模型 可为人体生成3D空间音频
要点:
上海AI实验室和Meta联合开发的开源模型能够为人体生成3D空间音频,实现身临其境的3D音场效果。
该模型利用头戴式麦克风的音频信号和人体姿态作为输入,通过多模态融合模式解决音源位置未知、麦克风距离音源较远等技术难题。
尽管取得了在3D空间音频生成方面的技术突破,但目前仅适用于渲染人体音,难以处理非自由音场传播环境,计算量较大难以部署到资源受限的设备上。
近期上海AI实验室与Meta合作推出的开源模型标志着在3D空间音频领域迈出的一大步。该模型通过处理头戴式麦克风的输入音频信号和分析人体姿态关键点,成功地实现了为人体生成3D空间音频的目标。这一技术突破为虚拟环境的沉浸感和临场感提供了关键支持,弥补了目前学术界和企业在听觉方面的疏漏。
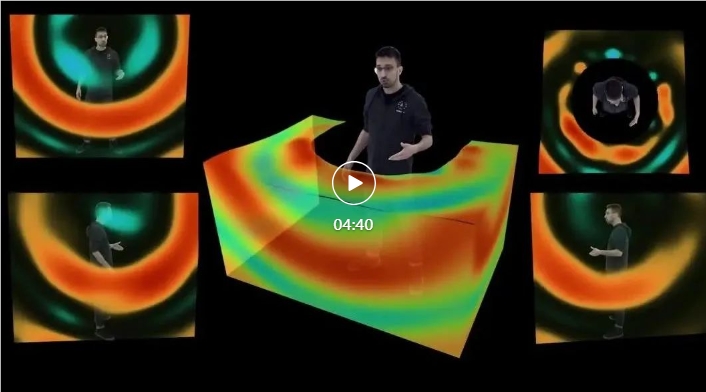
然而,从技术层面看,开发这样的3D空间音频模型并非易事。文章指出,面临着三大技术难题,其中包括音源位置未知、麦克风距离音源较远等挑战。为了解决这些问题,研究人员创新性地构建了多模态融合模式,并引入了身体姿态信息,从而成功消除了声源位置的歧义,实现了正确的空间音频生成。
具体而言,模型包括音频编码器、人体姿态编码器和音频解码器等模块。音频编码器处理头戴式麦克风的输入音频信号,通过时间平移对齐不同身体部位的音源位置,最终得到包含各个可能音源位置信息的音频特征表达。人体姿态编码器则分析人体姿态关键点,生成姿态特征表达,为正确生成三维空间音频提供了重要的提示。
项目地址:https://github.com/facebookresearch/SoundingBodies
尽管该模型在技术上取得了显著进展,成功实现了身临其境的3D音场效果,但研究人员也指出了其局限性。目前,该模型仅适用于渲染人体音,难以处理非自由音场传播环境,且计算量较大,难以在资源受限的消费类设备上部署。这一点对于模型的实际应用和推广提出了一定挑战。
综合而言,上海AI实验室和Meta联合开发的这一开源模型为人体生成3D空间音频开辟了新的可能性,为虚拟现实领域的发展贡献了有力的技术支持。然而,未来仍需进一步优化和拓展,以满足更广泛的应用场景和设备要求。
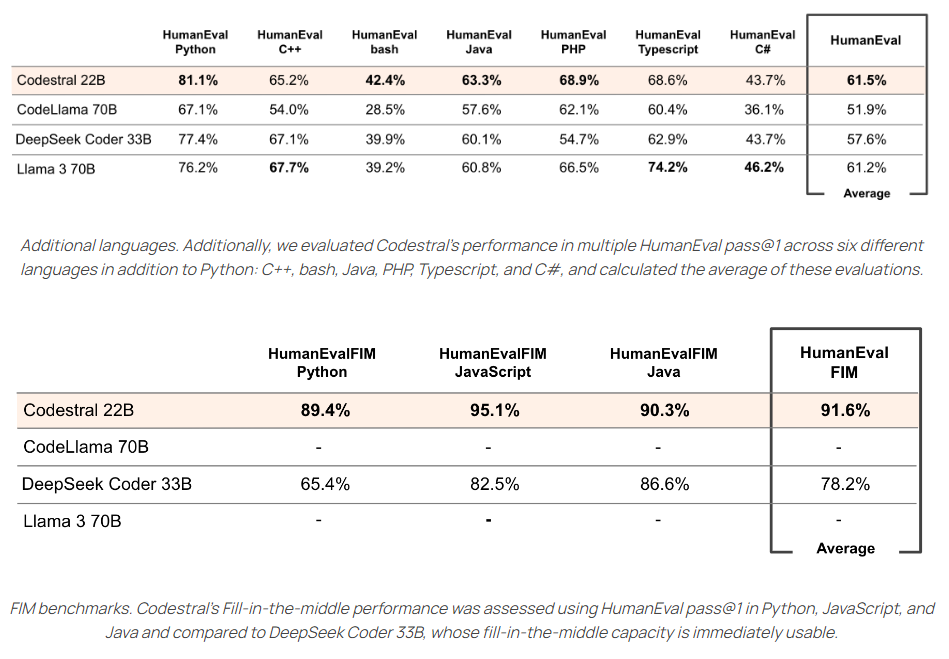
Mistral AI推首个代码生成模型Codestral 支持多种编程语言
MistralAI推出了其首个代码生成模型Codestral,这是一个功能强大的工具,旨在帮助开发者提高编码效率和质量。以下是Codestral的一些关键特性和优势:支持多种编程语言:Codestral能够支持超过80种编程语言,包括当前流行的语言如Python、Java、C、C、JavaScript和Bash,以及一些较少使用的如Swift和Fortran。站长网2024-05-30 10:37:500000自研AI芯片,拉拢AMD英伟达,定制化的Copilot和100多项AI更新……微软从没如此可怕过
沸沸扬扬传了许久的微软首款自研AI芯片,今天终于向外界露出了庐山真面目。美西时间11月15日上午,2023MicrosoftIgnite大会在西雅图会议中心举行。这是微软针对IT专业人员、企业决策者和开发者召开的年度技术会议,主要介绍Azure云服务、企业级解决方案、以及Windows、微软365、Copilot等全套产品的最新动态,还包含了技术培训、产品演示和趋势讨论。站长网2023-11-16 15:59:100000大模型都会标注图像了,简单对话即可!来自清华&NUS
多模态大模型集成了检测分割模块后,抠图变得更简单了!只需用自然语言描述需求,模型就能分分钟标注出要寻找的物体,并做出文字解释。在其背后提供支持的,是新加坡国立大学NExT实验室与清华刘知远团队一同打造的全新多模态大模型。随着GPT-4v的登场,多模态领域涌现出一大批新模型,如LLaVA、BLIP-2等等。0000三星旗舰Soc回归!Galaxy S24系列有骁龙和Exynos两种版本
快科技1月18日消息,三星GalaxyS24系列正式发布。对比上代,这次GalaxyS24系列再次启用三星自家的Exynos芯片Exynos2400(上一代GalaxyS23系列全系搭载骁龙8Gen2移动平台)。(图源:三星官网)站长网2024-01-19 08:47:390000中文在线推出“逍遥”万字创作大模型 可一键生成万字小说
今日,中文在线推出了一款名为“逍遥”的万字创作大模型。该模型具有一键生成万字小说的功能,并可为作者提供全生命周期的AI辅助创作工具。中文在线集团董事长兼总裁童之磊表示,与以往依赖人类作家进行创作不同,逍遥大模型将使内容产品的生产从人力模式转变为人力算力的模式。这将为作家提供更多的创作工具和资源,帮助他们提高创作效率和质量。站长网2023-10-13 15:37:280002