谷歌:LLM找不到推理错误,但能纠正它
LLM 找不到推理错误,但却能纠正错误!
今年,大型语言模型(LLM)成为 AI 领域关注的焦点。LLM 在各种自然语言处理(NLP)任务上取得了显著的进展,在推理方面的突破尤其令人惊艳。但在复杂的推理任务上,LLM 的表现仍然欠佳。
那么,LLM 能否判断出自己的推理存在错误?最近,剑桥大学和 Google Research 联合开展的一项研究发现:LLM 找不到推理错误,但却能使用该研究提出的回溯(backtracking)方法纠正错误。

论文地址:https://arxiv.org/pdf/2311.08516.pdf
数据集地址:https://github.com/WHGTyen/BIG-Bench-Mistake
这篇论文引起了一些争论,有人提出异议,比如在 Hacker News 上,有人评论这篇论文的标题言过其实,有些标题党。也有人批评说其中提出的校正逻辑错误的方法基于模式匹配,而非采用逻辑方法,这种方法其实容易失败。
Huang 等人在论文《Large language models cannot self-correct reasoning yet》中指出:自我校正或许是能有效地提升模型输出的风格和质量,但鲜有证据表明 LLM 有能力在没有外部反馈的情况下识别和纠正自身的推理和逻辑错误。比如 Reflexion 和 RCI 都使用了基本真值的纠正结果作为停止自我校正循环的信号。
剑桥大学和 Google Research 的研究团队提出了一种新思路:不再把自我校正看作一个单一过程,而是分成错误发现和输出校正两个过程:
错误发现是一种基础推理技能,已经在哲学、心理学和数学领域得到了广泛的研究和应用,并催生了批判性思维、逻辑和数学谬误等概念。我们可以合理地认为发现错误的能力也应该是 对 LLM 的一项重要要求。但是,本文结果表明:当前最佳的 LLM 目前还无法可靠地发现错误。
输出校正涉及部分或完全修改之前生成的输出。自我校正是指由生成输出的同一模型来完成校正。尽管 LLM 没有发现错误的能力,但本文表明:如果能提供有关错误的信息(如通过一个小型的监督式奖励模型),LLM 可以使用回溯方法校正输出。
本文的主要贡献包括:
使用思维链 prompt 设计方法,任何任务都可以变成错误发现任务。研究者为此收集并发布了一个 CoT 类型的轨迹信息数据集 BIG-Bench Mistake,该数据集由 PaLM 生成,并标注了第一个逻辑错误的位置。研究者表示,BIG-Bench Mistake 在它的同类数据集中,是首个不局限于数学问题的数据集。
为了测试当前最佳 LLM 的推理能力,研究者基于新数据集对它们进行了基准评测。结果发现,当前 SOTA LLM 也难以发现错误,即便是客观的明确的错误。他们猜测:LLM 无法发现错误是 LLM 无法自我校正推理错误的主要原因,但这方面还有待进一步研究。
本文提出使用回溯方法来校正输出,利用错误的位置信息来提升在原始任务上的性能。研究表明这种方法可以校正原本错误的输出,同时对原本正确的输出影响极小。
本文将回溯方法解释成了「言语强化学习」的一种形式,从而可实现对 CoT 输出的迭代式提升,而无需任何权重更新。研究者提出,可以通过一个经过训练的分类器作为奖励模型来使用回溯,他们也通过实验证明了在不同奖励模型准确度下回溯的有效性。
BIG-Bench Mistake数据集
BIG-Bench 由2186个 CoT 风格的轨迹信息集合组成。每个轨迹由 PaLM2-L-Unicorn 生成,并标注了第一个逻辑错误的位置。表1展示了一个轨迹示例,其中错误位于第4步。

这些轨迹来自 BIG-Bench 数据集中的5个任务:词排序、跟踪经过混洗的对象、逻辑推演、多步算术和 Dyck 语言。
他们使用 CoT prompt 设计法来调用 PaLM2,使其解答每个任务的问题。为了将 CoT 轨迹分成明确的步骤,他们使用了论文《React: Synergizing reasoning and acting in language models》中提出的方法,分开生成每一步,并使用了换行符作为停止 token。
在该数据集中,生成所有轨迹时,temperature =0。答案的正确性由精确匹配决定。
基准测试结果
表4报告了 GPT-4-Turbo、GPT-4和 GPT-3.5-Turbo 在新的错误发现数据集上的准确度。
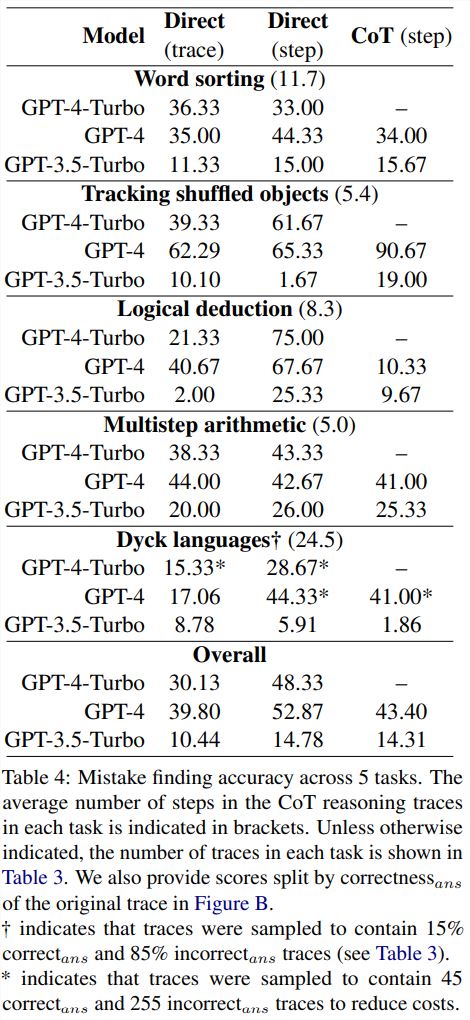
对于每个问题,可能的答案有两种情况:要么没有错误,要么就有错误。如有错误,则数值 N 则会指示第一个错误出现的步骤。
所有模型都被输入了同样的3个 prompt。他们使用了三种不同的 prompt 设计方法:
直接的轨迹层面的 prompt 设计
直接的步骤层面的 prompt 设计
CoT 步骤层面的 prompt 设计
相关讨论
研究结果表明,这三个模型都难以应对这个新的错误发现数据集。GPT 的表现最好,但其在直接的步骤层面的 prompt 设计上也只能达到52.87的总体准确度。
这说明当前最佳的 LLM 难以发现错误,即使是在最简单和明确的案例中。相较之下,人类在没有特定专业知识时也能发现错误,并且具有很高的一致性。
研究者猜测:LLM 无法发现错误是 LLM 无法自我校正推理错误的主要原因。
prompt 设计方法的比较
研究者发现,从直接轨迹层面的方法到步骤层面的方法再到 CoT 方法,无错误的轨迹准确度显著下降。图1展示了这种权衡。
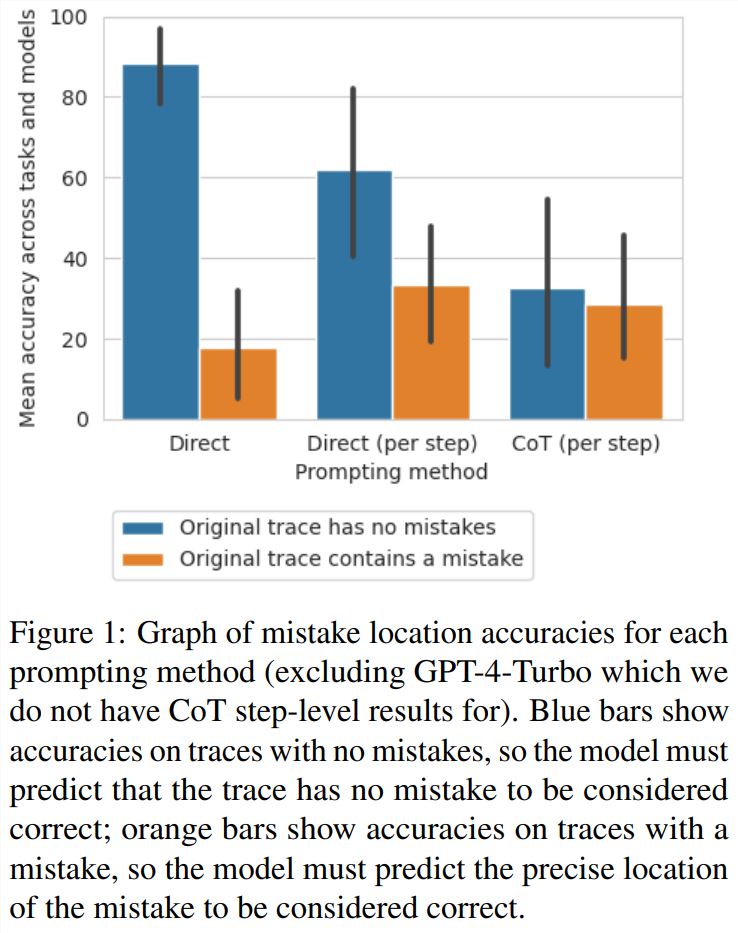
研究者猜测其原因是模型生成的输出的数量。这三种方法涉及到生成越来越复杂的输出:直接的轨迹层面的 prompt 设计方法需要单个 token,直接的步骤层面的 prompt 设计方法每步需要一个 token,CoT 步骤层面的 prompt 设计每步需要多个句子。如果每次生成调用都有一定的概率识别出错误,那么对每条轨迹的调用越多,模型识别出至少一个错误的可能性就越大。
将错误位置作为正确性代理的少样本 prompt 设计
研究者探究了这些 prompt 设计方法能否可靠地决定一个轨迹的正确性,而不是错误位置。
他们计算了平均 F1分数,依据为模型能否预测轨迹中是否存在错误。如果存在错误,则假设模型预测的是该轨迹是 incorrect_ans。否则就假设模型预测的是该轨迹是 correct_ans。
使用 correct_ans 和 incorrect_ans 作为正例标签,并根据每个标签的出现次数进行加权,研究者计算了平均 F1分数,结果见表5。
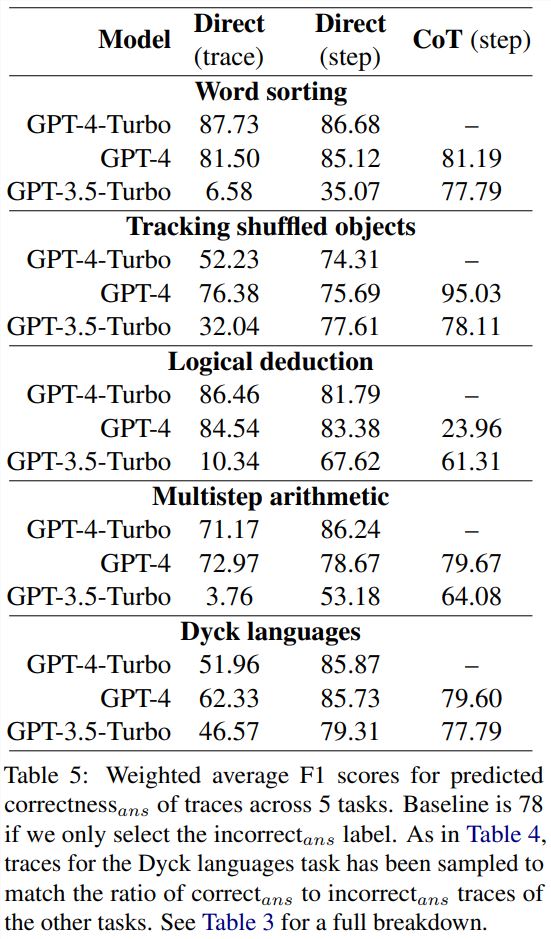
这个加权 F1分数表明,对于确定最终答案的正确性而言,通过 prompt 寻找错误是一个很糟糕的策略。
回溯
Huang 等人指出 LLM 无法在没有外部反馈的情况下自我校正逻辑错误。但是,在许多真实世界应用中,通常没有可用的外部反馈。
研究者在这项研究中采用了一种替代方案:用一个在少量数据上训练的轻量级分类器替代外部反馈。与传统强化学习中的奖励模型类似,这个分类器可以检测 CoT 轨迹中的任何逻辑错误,然后再将其反馈给生成器模型以提升输出。如果想要最大化提升,可以进行多次迭代。
研究者提出了一种简单的回溯方法,可以根据逻辑错误的位置来提升模型的输出:
模型首先生成一个初始的 CoT 轨迹。在实验中,设置 temperature =0。
然后使用奖励模型确定轨迹中错误的位置。
如果没有错误,就转向下一个轨迹。如果有错误,则再次向模型输入 prompt 以执行相同的步骤,但这一次 temperature =1,生成8个输出。这里会使用同样的 prompt 以及包含错误步骤之前所有步骤的部分轨迹。
在这8个输出中,过滤掉与之前的错误一样的选项。再从剩下的输出中选择对数概率最高的一个。
最后,用新的重新生成的步骤替换之前步骤,再重新设置 temperature =0,继续生成该轨迹的剩余步骤。
相比于之前的自我校正方法,这种回溯方法有诸多优势:
新的回溯方法不需要对答案有预先的知识。相反,它依赖于有关逻辑错误的信息(比如来自训练奖励模型的信息),这可以使用奖励模型一步步地确定。逻辑错误可能出现在 correct_ans 轨迹中,也可能不出现在 incorrect_ans 轨迹中。
回溯方法不依赖于任何特定的 prompt 文本或措辞,从而可减少相关的偏好。
相比于需要重新生成整个轨迹的方法,回溯方法可以通过复用已知逻辑正确的步骤来降低计算成本。
回溯方法可直接提升中间步骤的质量,这可能对需要正确步骤的场景来说很有用(比如生成数学问题的解),同时还能提升可解释性。
研究者基于 BIG-Bench Mistake 数据集实验了回溯方法能否帮助 LLM 校正逻辑错误。结果见表6。
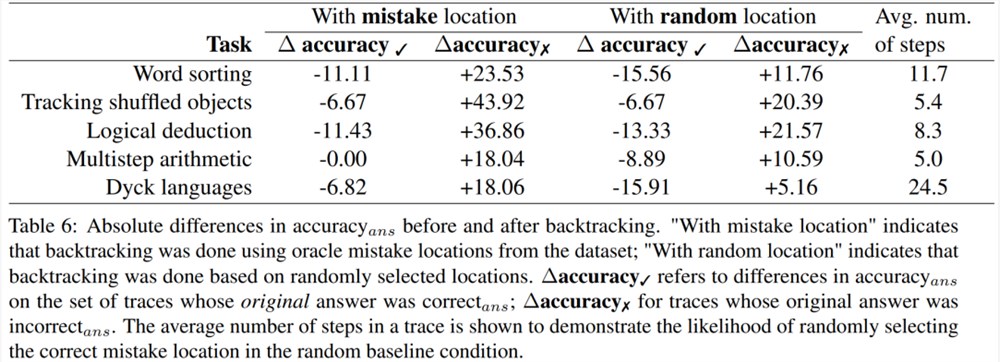
∆accuracy✓ 是指在原始答案是 correct_ans 时,在轨迹集合上的 accuracy_ans 之差。
∆accuracy✗ 则是对于 incorrect_ans 轨迹的结果。
这些分数结果表明:校正 incorrect_ans 轨迹的收益大于改变原本正确的答案所造成的损失。此外,尽管随机基准也获得了提升,但它们的提升显著小于使用真正错误位置时的提升。注意,在随机基准中,涉及步骤更少的任务更可能获得性能提升,因为这样更可能找到真正错误的位置。
为了探索在没有好的标签时,需要哪种准确度等级的奖励模型,他们实验了通过模拟的奖励模型使用回溯;这种模拟的奖励模型的设计目标是产生不同准确度等级的标签。他们使用 accuracy_RM 表示模拟奖励模型在指定错误位置的准确度。
当给定奖励模型的 accuracy_RM 为 X% 时,便在 X% 的时间使用来自 BIG-Bench Mistake 的错误位置。对于剩余的 (100− X)%,就随机采样一个错误位置。为了模拟典型分类器的行为,会按照与数据集分布相匹配的方式来采样错误位置。研究者也想办法确保了采样的错误位置与正确位置不匹配。结果见图2。
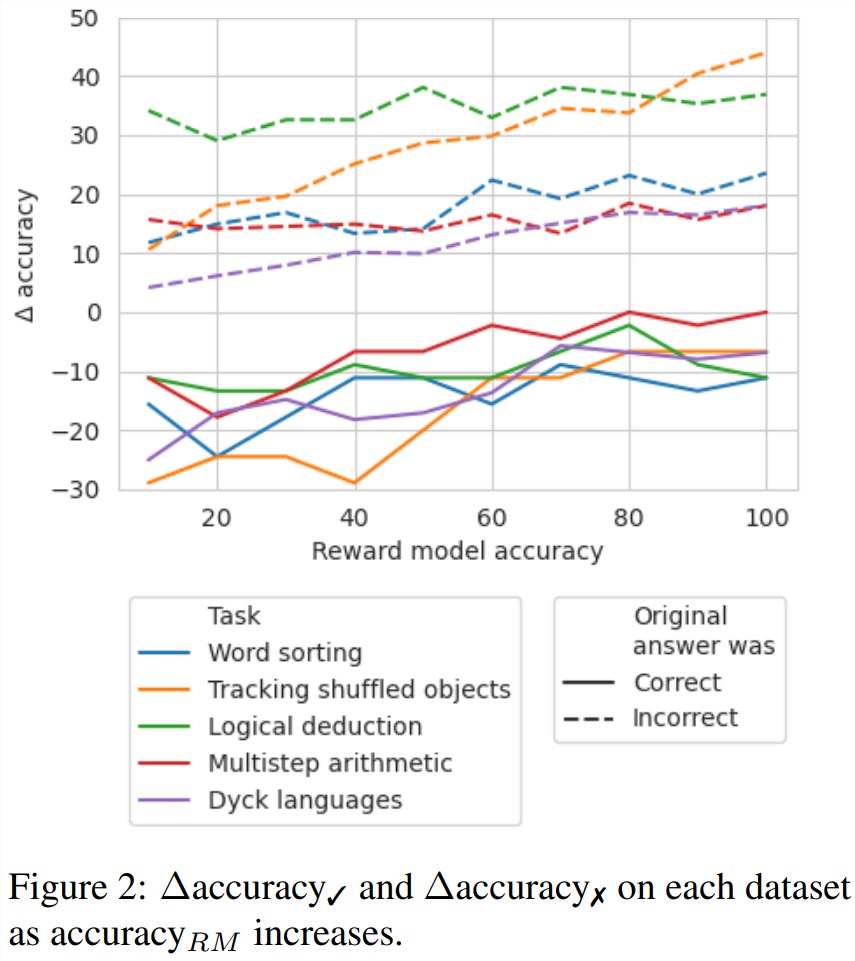
可以看到 ∆accuracy✓ 的损失在65% 时开始趋于稳定。事实上,对于大多数任务,在 accuracy_RM 大约为60-70% 时,∆accuracy✓ 就已经大于 ∆accuracy✗ 了。这表明尽管更高的准确度能得到更好的结果,但即便没有黄金标准的错误位置标签,回溯也依然有效。
今日AI:Midjourney角色一致性功能上线、Grok即将开源、OpenAI永远提供免费版ChatGPT
欢迎来到【今日AI】栏目!这里是你每天探索人工智能世界的指南,每天我们为你呈现AI领域的热点内容,聚焦开发者,助你洞悉技术趋势、了解创新AI产品应用。新鲜AI产品点击了解:https://top.aibase.com/📢一分钟速看版•Midjourney角色人物一致性功能正式上线•OpenAI将永远提供免费的ChatGPT版本站长网2024-03-12 15:27:070000老机型重生!华为手机内存升级限时8.8折:仅需342元起
快科技9月9日消息,如果手机存储空间不足,会导致应用、系统的正常运行受到影响,流畅度也会下降,这时就需要优化空间或升级存储空间。据华为终端官方公众号介绍,华为老机型内存(官方解释为存储内存,实际就是存储空间)升级服务正在进行限时8.8折活动,方便老机型用户升级。站长网2024-09-10 13:43:300001谷歌希望开发者承诺不会滥用新的 Chrome 广告 API
据国外媒体报道,谷歌计划推出适用于Chrome的新API,旨在为网络浏览器提供根据用户偏好定制的广告。然而,由于指纹识别攻击可能导致个人身份被识别的问题曝光后,谷歌已要求开发人员不要滥用该方法。站长网2023-06-30 19:36:060000大模型的“最后一公里”,京东走通了
大模型落地,又进了一步。2023年7月13日,在2023京东全球科技探索者大会暨京东云峰会上,京东云推出了京东言犀大模型,直击知识密集型、任务型产业场景。现场,京东集团CEO许冉表示:“从产业端切入大模型,如同从北坡攀登技术珠峰,道路虽然更加艰难,却有更波澜壮阔的风景。”这意味着,京东坚持做难而正确的事情。站长网2023-07-18 12:38:540004火狐浏览器推出AI工具Fakespot Chat 可检测电商平台虚假评论
火狐浏览器开发公司Mozilla推出了AI工具FakespotChat,旨在帮助在线购物者检测虚假评论。据悉,Fakespot是一家利用AI和机器学习来识别伪造和欺骗性产品评论的初创公司,今年早些时候被Mozilla收购。站长网2023-11-13 17:14:300000