国产大模型黑马诞生,千亿级拿下双榜第一!知识正确性能力突出,大幅降低LLM幻觉问题
【新智元导读】夸克,也下场大模型了。甫一问世,夸克大模型就迅速登顶权威测评双榜第一,幻觉率大幅降低,可以预见,风靡年轻人的夸克APP,要掀起新的飓风了。
最近的各大手机厂商和互联网公司,都在卯足了劲儿地发布大模型。
而其中的一匹黑马,显得格外引人注目——
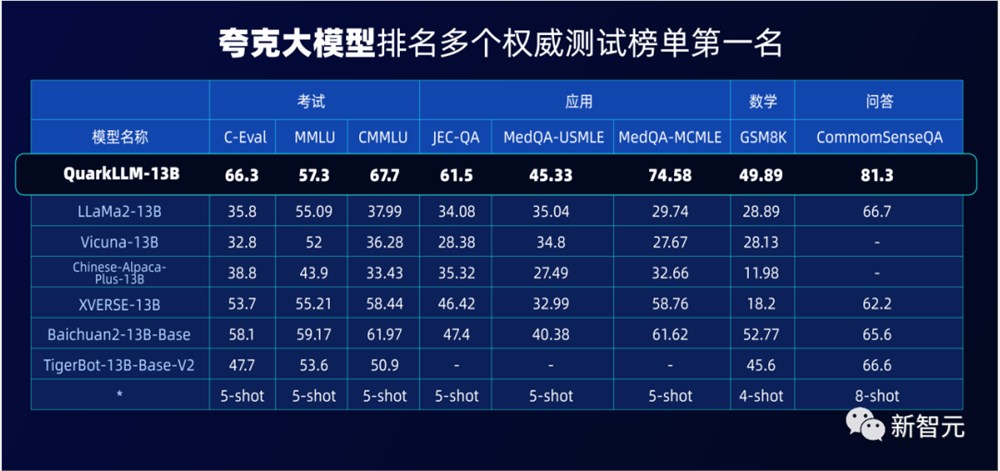
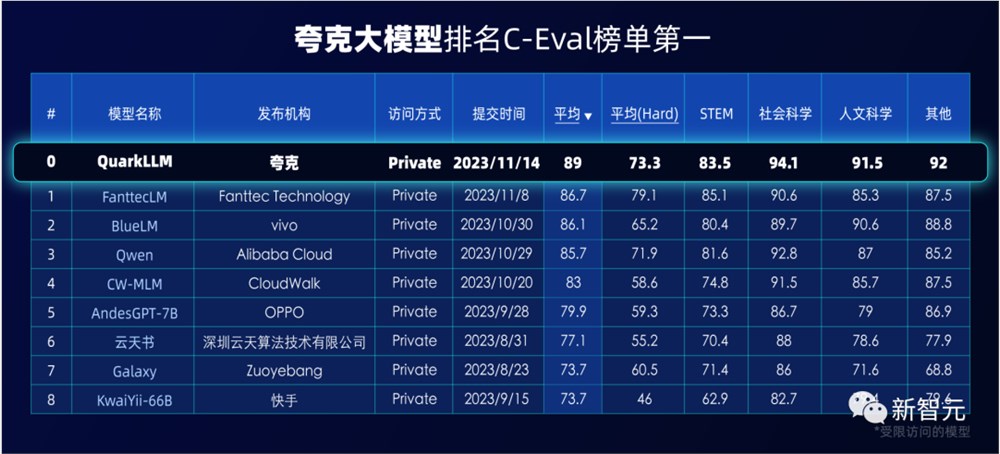
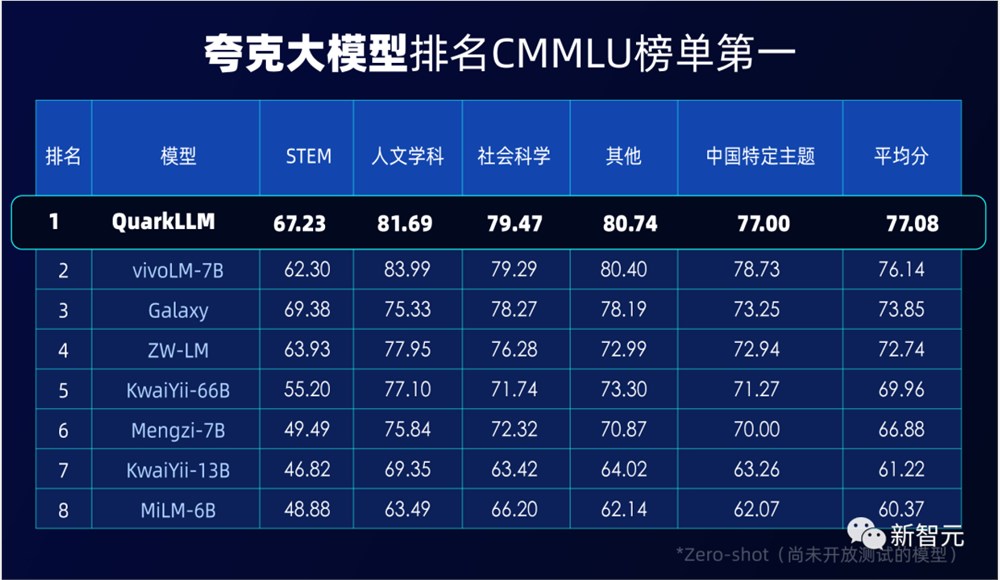
千亿级在C-Eval和CMMLU两大权威评测中拿下双榜第一,百亿级在法律、医疗、问答等领域的性能评测中名列榜首。
如此擅长人文社科,再结合夸克以往的业务,阿里巴巴智能信息事业群为夸克大模型安排的这条路线,逐渐明晰了起来。
没错,答案就是——做通识问答和专业搜索!
在年轻人中人气极高的夸克APP,是一个集合搜、用、存的智能信息产品。而有了夸克大模型后,这项过程,就都可以进行智能化升级。
效果有多好?请看——
搜索、健康、教育、办公,轻松hold住
夸克大模型,是一个面向搜索、生产力工具和资产管理助手的应用型大模型,应用场景有通用搜索、医疗健康、教育学习、职场办公等等。
搜索
现在的千亿参数模型,已经可以在部分夸克端的内测场景里提供服务。
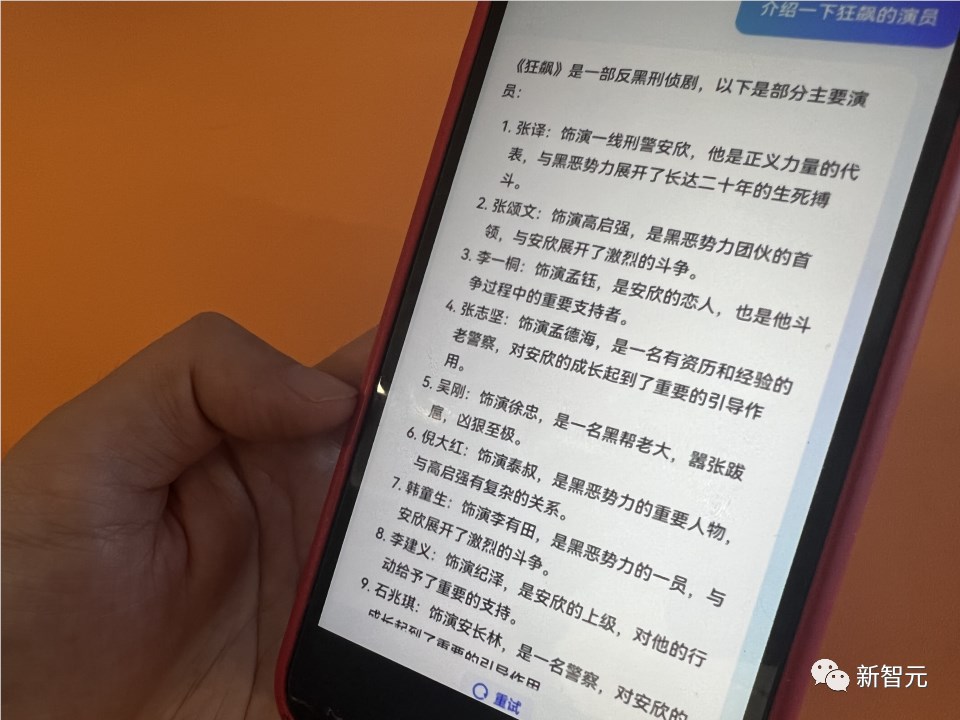
比如,让它介绍《狂飙》的演员,答案不仅有演员表,还能介绍谁在剧里演了什么。
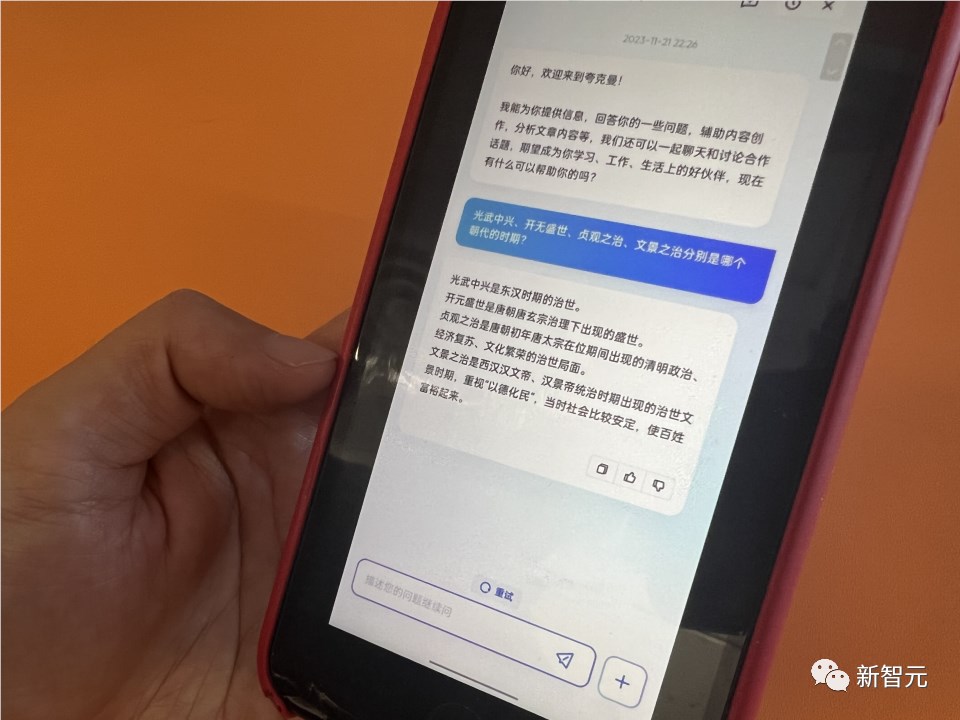
这道历史题「光武盛世、开元盛世、贞观之治、文景之治,是哪个朝代」,尤其体现了夸克大模型的能力。
如果问普通搜索引擎,这种一连串的问题,是搜不出来的。
而反事实的问题,就更有难度,因为不仅能测出模型学过的知识,还需要模型进行推理。
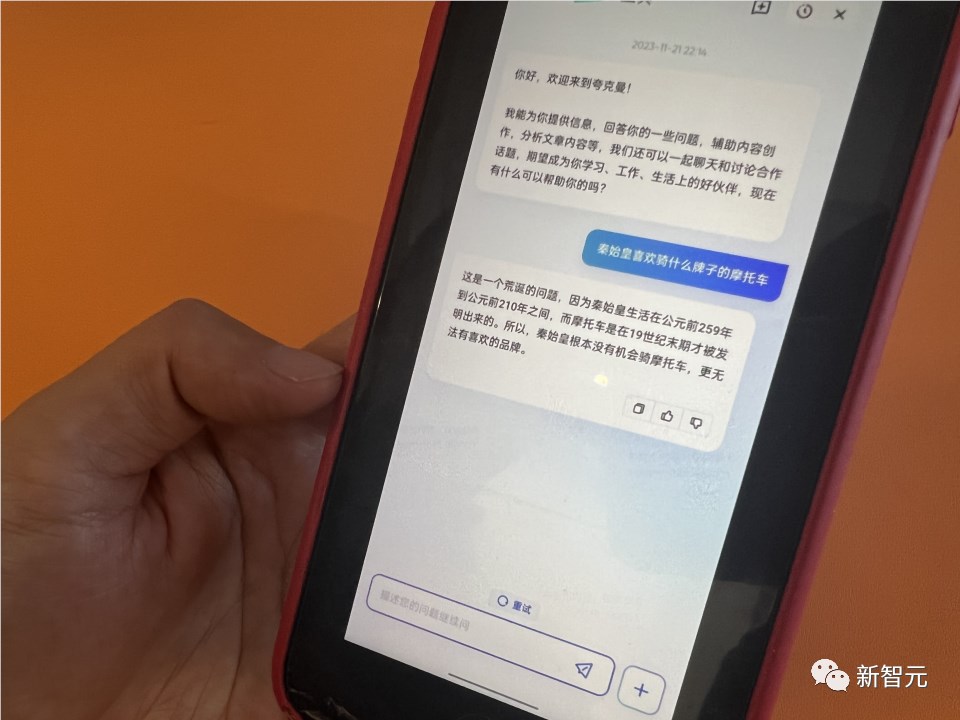
如果问它,秦始皇喜欢骑什么牌子的摩托车?
它就会推理出,秦始皇是秦朝的,摩托车是哪年发明的,所以秦始皇没有机会骑摩托车,更没有喜欢的品牌。
下面这个多轮对话下中英混合的case 「in和on有什么区别」,已经到了可以自学英语的程度。
在多轮对话中,我们可以不断对它提出需求。

可以看到,夸克大模型的回答,比一般的搜索结果在内容的全面性和专业性上,都要好得多。
健康
健康,是夸克团队要重点建设的方面。
搜索引擎的核心群体,就是健康群体,因为这个群体并没有其他软件或APP提供很好的信息服务。
在健康上,夸克团队做了许多行业数据建设和知识建设,建成了完整的健康知识图谱。
另外,他们还建设了大量的医典百科、医典问答这类面向C端的数据,并且整理了大量指南、标准、书籍。
在「如何预防流感」这个问题中,夸克大模型回答了不同的方法,包括个人卫生、疫苗等等。同时会体现学到的知识点援引出处。
可见,团队在行业里建立的知识权威性,大模型确实学到了。
而且,最理想的情况,模型不会只是回答健康的科普问题,还要具备比较好的推理能力。
「咳嗽三天,是怎么回事?」
如果在搜索引擎里问这个问题,是无法获得丰富、完备的信息的,因为咳嗽对应的疾病非常多。
而在夸克大模型在给出一个回答之后,还会有推理和反问。

界面中会出现一张卡,询问用户是否有其他情况。提交后,大模型会根据当前症状给出一个更精准的疾病范围。
这个过程的核心,就是医学相关的知识推理,和医学知识的具体信息。
并且,团队还在准备多模大模型,上传生化检验单后,就可以给用户提供更准确的信息。
教育
在教育类产品上,不止要看能不能答,更要看为什么能答。
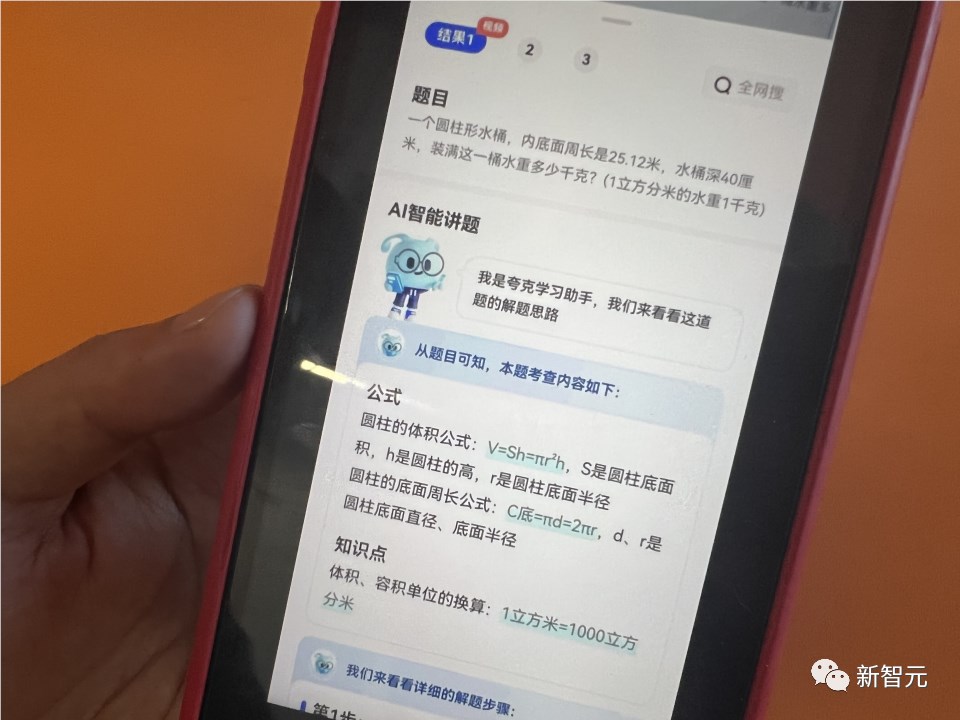
比如这个应用题,一个圆桶周长25米,深40厘米,这桶水有多少千克呢?
夸克大模型回答时,不仅会列出解题的过程,还会输出解题会用到哪些公式,涉及哪些关键知识点,比如各单位的换算关系。
然后先求圆的面积,然后算出体积,再得到最后的结果。
办公
此外,夸克大模型还可以化身为职场打工神器。
举例来说,一个关于销售演讲技巧的PPT有8页,逐页看的话,很花时间。但只要把文档上传上去,夸克大模型就可以列举出关键点,让效率大大提升。
而在大家常用的文案写作上,夸克也做了几个小工具。比如,打卡网红露营地的时候想发个朋友圈,这时就可以让AI写得有诗意一点。
国产大模型,学霸喜 1
可以说,全栈自研的千亿级参数的夸克大模型,是国内LLM班级里妥妥的学霸了。
C-Eval是由清华大学、上海交通大学和爱丁堡大学合作构建的综合性考试评测集,覆盖52个学科,是目前权威的中文AI大模型评测榜单之一。
CMMLU是由MBZUAI、上海交通大学、微软亚洲研究院共同推出,包含67个主题,专门用于评估语言模型在中文语境下的知识和推理能力。
两个榜单的权威性毋庸置疑。
评测过程中,夸克大模型经过了上万道专业考题的检验,覆盖几十个学科和不同学段。无论是常识问题还是社会科学知识,夸克大模型都展现出了处理复杂、多层次问题的能力。
基于精调后的训练数据,夸克大模型能够更好地理解问题的上下文、逻辑结构和语义关系,从而更全面、深入地分析和解决问题。
在5471道真题考试中,夸克大模型不仅成功超越了GPT-3.5,甚至部分成绩还优于GPT-4——

45个科目中,11科优秀(准确率≥80%),25科及格(准确率≥60%)
总结来说,夸克大模型整体的水平与GPT-3.5相当,但能更好地理解中文知识体系并进行文本写作。
在多语言翻译、写代码、安全合规、内容创作等领域,处在国内行业头部水平。
多模态方面,夸克大模型支持相册搜索、AI相机场景下的文搜图、图生图、图生文等。
从上面的演示可以看出,这些知识和创作对应的能力,和夸克的产品之间,恰恰就有着极强的对应关系。
破除大模型幻觉,夸克是专业的
大模型要做产品,幻觉就是一道必然要解决的难题。
在蒋冠军看来,要解决大模型应用的问题,就要先解决知识正确性的问题。
凭借着搜索技术能力的积累,团队在解决幻觉这个困扰绝大多数模型的老大难问题时,有着相当大的优势。
能解决幻觉难题,首先就是因为夸克在搜索知识体系的整体积累。
在健康场景下,错误率甚至能降到5%以下。能达到如此高的可用性,也是因为很多搜索结果都是医生三审三校的结果。
在模型的预训练中,因为数据规模越大,引入的错误知识也会越多。这是个悖论。因此,团队花费了大量时间和精力,做了数据准确性校验和对齐。
为什么能成学霸?
除了专门针对大模型的技术创新之外,夸克经过多年发展所积累的4个优势,也是培养出这位「新学霸」的原动力。
1. 数据全面
首先,夸克积累了40多个行业,几乎涵盖了整个中文领域的知识。
2. 多语言知识
其次,在英语等其他语种上,夸克也凭借着在通用搜索领域的深耕,积累了丰富的知识和数据。
对于大模型来说,知识的理解、对齐和校验,是至关重要的。而夸克凭借着通用搜索的经验,已经在内容的理解方面,建立起了一个非常完整的体系。
3. 数据丰富
第三,夸克拥有很高的数据丰富程度。
搜索引擎本身就是海量的网页数据,在夸克的数据库里,这个数字是千亿级。
这也意味着,需要有一个强大的工程系统来处理如此大规模的网页数据,从而完成去重、分析等工作。这种能力和大模型的需求非常匹配——大模型要大算力,传统搜索引擎本身就具备大算力。
此外,对于搜索引擎来说,如何去判断搜索结果的好坏,以及如何在大量的站点中进行筛选,都需要团队有一个高质量的评估和评价体系。而这个体系,对于大模型来说也同样适用。
类似的,在大模型和人类对齐方面,传统搜索积累的经验,也能够更好地帮助团队。
4. 人才储备
其实,通用搜索涵盖的范围非常广,包括网页搜索、图片搜索、视频搜索、文档搜索等等。而支持这些搜索功能的技术体系和人员,就是大模型所需的多模技术能力和人才体系。
在这方面,夸克有着深厚积淀。
夸克技术负责人蒋冠军
此外,夸克的产运团队在智能技术的产品创新上,也有着丰富的经验。这是因为,夸克的目标是成为一个工作和学习的个人助手,因此所有的智能化产品,都是以技术为核心驱动的。
至于业务层面,夸克在健康、教育等关键的行业里,不仅有着较好的数据积累,同时团队成员里还有医生和老师的从业经验。这些人才带来的一手经验,对于构建大模型所需的高质量SFT样本和专业知识来说,至关重要。
5. 知识增强
最后,夸克还利用了搜索和知识图谱文档的积累,对自家的大模型进行了知识增强,从而极大地缓解了常见的幻觉问题。
搜索,大模型应用的最佳平台
ChatGPT掀起大模型热以来,业内一直在不断探索,大模型的落地场景究竟在哪里?
业内有观点认为,以搜索为代表的信息服务场景,是大模型开发及应用的最佳平台。
在今年5月的I/O大会上,谷歌将生成式AI和自己传统搜索服务结合起来,发布了全新Search Generative Experience(SGE)。
简单来说,谷歌会利用AI为搜索的内容提供说明,回答用户提出的问题,帮用户做旅行规划等等。
期间,用户不再需要货比三家般的在多个链接之间来回跳转,也不用花心力去判断哪个链接背后的信息是真的,因为所有可用的内容都被集中到了AI收集到的回复之中。
在最近的更新中,谷歌又添加了让SGE在AI生成的回复内容中附加图片和视频的功能,帮助用户更加直观的了解自己搜索的知识和信息。
不仅如此,SGE的AI响应中还会标注发布时间的链接,来支持由AI生成的回复内容。如果用户对于相关的信息感兴趣,点击链接就能更加全面地了解具体的内容。
而夸克大模型在夸克APP的落地,则是以扎实的技术,跑通了中国的「大模型 搜索」之路。
夸克的自研之路
之所以夸克能够自研大模型,其核心是发挥了在搜索引擎和数据上的优势。
蒋冠军表示,要从千亿级的网页里,筛选出数亿的高质量网页,这个过程非常复杂。不是做搜索引擎的厂商,要完成这项任务,成本和代价非常高。
首先,获取海量的中文数据和知识本身,难度就非常大。
其次,网页里的垃圾数据非常多。这时候,就需要把行业数据和知识图谱的积累,输入进大模型作为补充。
第三个核心挑战,就是人类知识对齐和SFT精标数据对齐。真正有用的SFT样本数据很稀缺,这需要各行各业有经验的人去做。
对此,夸克分了两个阶段进行尝试。第一版不行,就马上重组了新的专业团队,其中不只有资深的从业人员,还有来自各行各业的外包人员。然后才一步一步地走到了今天。
以后,夸克大模型会优先落地通识问答、专业搜索等场景,充分满足年轻人自我提升和充电的需求。
在可见的未来,会有更智能的下一代产品,让AI助理无处不在。
「AI时代已经来临,大模型应用的全新体验临界点近在咫尺。」
随着自研大模型的全面升级,全新的夸克,必然会给我们带来全新的惊喜。
报告:2023年我国网络文学用户规模超5亿人
今日,《2023中国网络文学蓝皮书》正式发布。据报告显示,我国网络文学用户规模已突破5亿大关,作品总量更是高达3000万部以上,每年新增作品数量约200万部。在题材方面,现实、科幻、历史等多元领域均取得了丰硕的成果,主流化、精品化的进程也在持续加快。站长网2024-04-28 16:57:250001贵州茅台:i茅台累计注册用户超4000万
据贵州茅台公布数据显示,截至5月18日,i茅台的注册用户已超过4000万,并且累计销售额已经超过了230亿元。据了解,2022年5月19日,i茅台APP宣布正式上线。“i茅台”是贵州茅台官方推出的数字营销APP,支持消费者在线注册、实名认证、线上线下支付、取消退款、门店提货等。站长网2023-05-19 16:07:410001人工智能芯片热潮持续,英伟达的收入增长了两倍
芯片制造商英伟达(Nvidia)当地时间周二公布的第三财季业绩超出华尔街预测,股价在盘后交易中下跌1%。但该公司称,由于出口限制影响了对其他国家的销售,下一季度将受到负面影响。Nvidia财务总监ColetteKress在致股东的信中说:「我们预计,2024财年第四季度,我们对这些目的地的销售额将大幅下降,不过我们相信,其他地区的强劲增长将足以抵消这一下降。」站长网2023-11-22 08:58:040000郭明錤:苹果不太可能在明年推出生成式人工智能
根据分析师郭明錤的说法,苹果公司明年不太可能推出生成式人工智能。郭明錤称,苹果在生成式人工智能方面“明显落后于竞争对手”,并且“没有迹象表明苹果将在2024年将人工智能边缘计算和硬件产品整合在一起。”这并不令人惊讶,因为苹果首席执行官蒂姆·库克曾多次表示,人工智能存在“一些需要解决的问题”。尽管如此,他也承认人工智能很重要,并且苹果会继续将人工智能整合到其产品中,但是“要非常慎重”。站长网2023-08-03 10:36:390000盒马换帅300天:狂飙拓店、加速下沉、开放加盟
主要面向一二线城市中产阶层用户的盒马鲜生,正在将门店开进更多城市、更下沉的市场。在徐州的盒马鲜生门店,相比于水产、生鲜产品,烘焙区和各类果汁饮料等“新奇特”产品反倒更吸引当地居民排队购买。由于刚开业不久,客流量较大,在周末及节假日晚上,商场外的整条路都堵的。0000