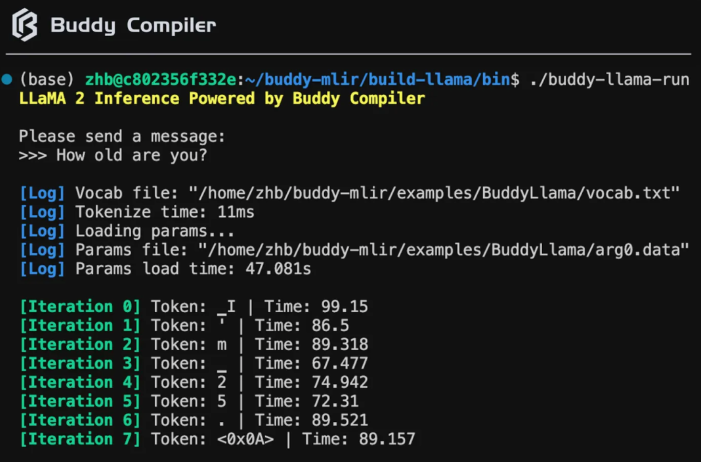
Buddy Compiler打通LLaMA 2端到端推理
要点:
LLaMA2端到端推理打通!结合 MLIR 和 PyTorch 的编译生态,中国团队展示了 Buddy Compiler 的前端部分实现,可以覆盖 LLaMA 计算图,进行 MLIR 转换和部分优化。
Buddy Compiler 基于 PyTorch 和 MLIR 实现了 LLaMA 的端到端推理通路,通过 Buddy Compiler 工具链进行优化和下降,最终生成可执行文件,实现了从 AI 模型到硬件架构的编译流程。
技术路线标准化、上手门槛低和优化上限高是整个软硬件协同设计生态的重要原则,Buddy Compiler 致力于实现这一目标,并将 PyTorch 和 MLIR 作为关键组成部分,提供了简化和解耦的开发流程。
Buddy Compiler 选择使用 TorchDynamo 作为 Trace 工具对接 AI 模型,并使用 Aten IR 作为对接层级,通过 MLIR Python Bindings 实现 Dynamo Compiler 生成 TOSA/Linalg Ops,从而实现了从 PyTorch 到 MLIR 的转换。
Buddy Compiler 是一个结合了 MLIR 和 PyTorch 的编译生态的工具,它实现了 LLaMA 的端到端推理通路。通过 Buddy Compiler,我们可以将 AI 模型从 PyTorch 转换为 MLIR,并进行优化和下降,最终生成可执行文件。
Buddy Compiler 的设计原则是技术路线标准化、上手门槛低和优化上限高。为了实现这一目标,Buddy Compiler 选择使用 TorchDynamo 作为 Trace 工具对接 AI 模型,并使用 Aten IR 作为对接层级。通过 MLIR Python Bindings 实现的 Dynamo Compiler 可以将 PyTorch 的 Aten IR 转换为 MLIR 的 TOSA/Linalg Ops。
Buddy Compiler 的编译通路可以面向通用硬件进行优化。它使用了 MLIR Core Dialect 进行实现,从而实现了最大化的复用,并且与所有 LLVM/MLIR 的工具兼容。在优化方面,Buddy Compiler 采用了针对循环的并行计算优化和针对矩阵乘法的向量化优化。
它还可以生成面向特定加速器的代码,例如 Gemmini 加速器。目前,Buddy Compiler 已经在 X86AVX512平台上进行了测试,同时还在进行 Arm Neon 和 RISC-V Vector Extesion 的广泛测试。未来,Buddy Compiler 还计划支持 GPU 的优化,并增加前端的覆盖程度,以及将多模态大模型编译到多种硬件平台上。
总的来说,Buddy Compiler 通过结合 MLIR 和 PyTorch 的编译生态,实现了 LLaMA 的端到端推理通路。它的设计原则是标准化技术路线、降低上手门槛和提高优化上限。通过 Buddy Compiler,我们可以将 AI 模型从 PyTorch 转换为 MLIR,并进行优化和下降。
Buddy Compiler 的编译通路可以面向通用硬件进行优化,并已在 X86AVX512平台上进行了测试。未来,Buddy Compiler 还计划支持更多的硬件平台,并增加前端的覆盖程度。通过 Buddy Compiler,我们可以更好地利用软硬件协同设计,实现高效的大模型推理。
百度文心大模型4.0正加紧训练 已接近可发布状态
据《科创板日报》报道,百度正在加速训练文心大模型4.0,并预计在10月17日的百度世界大会上发布。这个新版本的大模型是继文心大模型3.5之后的又一重要升级,将着重在基础模型上实现大提升。有消息称,文心大模型4.0的进展比预期要快很多,其核心能力将得到显著提升,包括理解、生成、逻辑和记忆等方面。特别是在逻辑推理、代码和数学等方面,该模型的进步最为明显。站长网2023-10-09 08:17:000000苹果iOS 18和macOS 15“设置”应用将大幅精简重排!
根据彭博社知名评论员马克·古尔曼近日爆料,苹果公司正在计划在即将发布的iOS18和macOS15系统中对“设置”应用进行精简,并重新安排其内部各个选项。同时,该应用还将通过改进搜索功能、增强用户体验以及优化页面导航等方式来提高其简洁性。0000三星Galaxy Z Fold/Flip5将于 7 月 26 日发布
三星宣布将于7月26日19点举行Galaxy全球新品发布会,发布第五代折叠屏旗舰。目前,三星的GalaxyZFold/Flip5已经通过了国家质量认证,配备了25W的充电器,并将搭载3.36GHz的骁龙8Gen2forGalaxy芯片站长网2023-07-06 18:22:270001淘宝AI大模型应用“淘宝问问”将上线双11大促模式 提供购买建议
今年9月,淘宝推出AI大模型应用“淘宝问问”进行内测,用户可通过淘宝App搜索或邀请码参与测试。当时,淘宝表示,淘宝问问是淘宝在淘宝App原搜索功能上对电商搜索导购方式进行迭代的创新尝试,旨在结合用户输入,通过深度合成算法为用户提供更符合消费习惯的商品和内容。站长网2023-10-18 11:43:070000“点点”撑得起小红书AI搜索的野心吗?
小红书终究还是拿到了DeepSeek这张船票。前几天,小红书旗下独立AI搜索App“点点”推出“深度思考”功能,据此前《钛媒体》报道,其背后接入的大概率是DeepSeek-R1开源模型。0000