提前对齐,视频问答新SOTA!北大全新Video-LLaVA视觉语言大模型,秒懂视频笑点
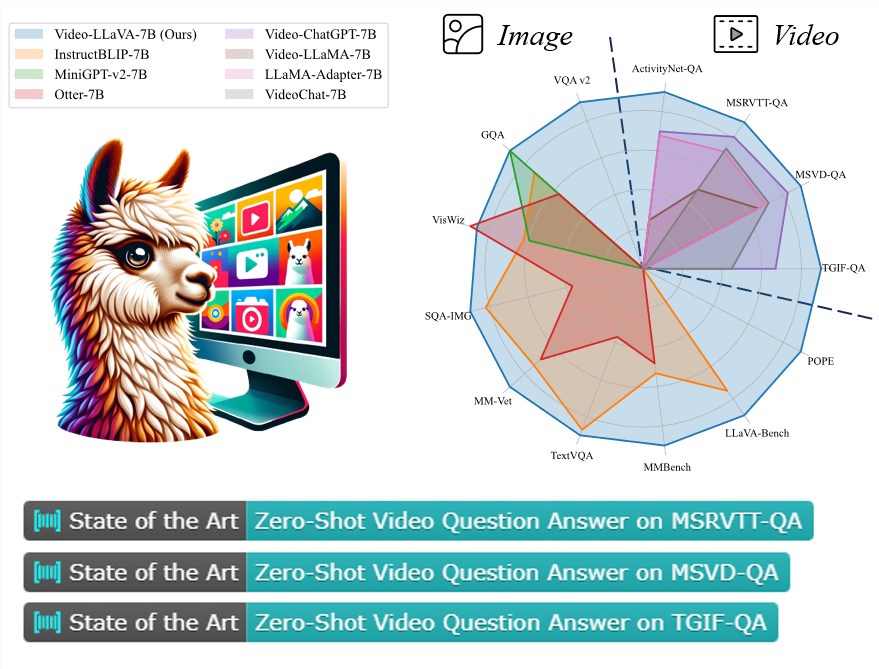
【新智元导读】最近,来自北京大学等机构研究者提出了一种全新视觉语言大模型——Video-LLaVA,使得LLM能够同时接收图片和视频为输入。Video-LlaVA在下游任务中取得了卓越的性能,并在图片、视频的13个基准上达到先进的性能。这个结果表明,统一LLM的输入能让LLM的视觉理解能力提升。
最近,来自北大的研究人员提出了一种全新的视觉语言大模型——Video-LLaVA,为alignment before projection提供了新颖的解决方案。
与以往的视觉语言大模型不同,Video-LLaVA关注的是提前将图片和视频特征绑定到统一个特征空间,使LLM能够从统一的视觉表示从学习模态的交互。
此外,为了提高计算效率,Video-LLaVA还联合了图片和视频进行训练和指令微调。
论文地址:https://arxiv.org/pdf/2310.01852.pdf
GitHub地址:https://github.com/PKU-YuanGroup/Video-LLaVA
Huggingface地址:https://huggingface.co/spaces/LanguageBind/Video-LLaVA
凭借强大的语言理解能力,诸如ChatGPT这类的大语言模型迅速在AI社区风靡。而如何让大语言模型同时理解图片和视频,也成为了大模型背景下的研究多模态融合的热点问题。
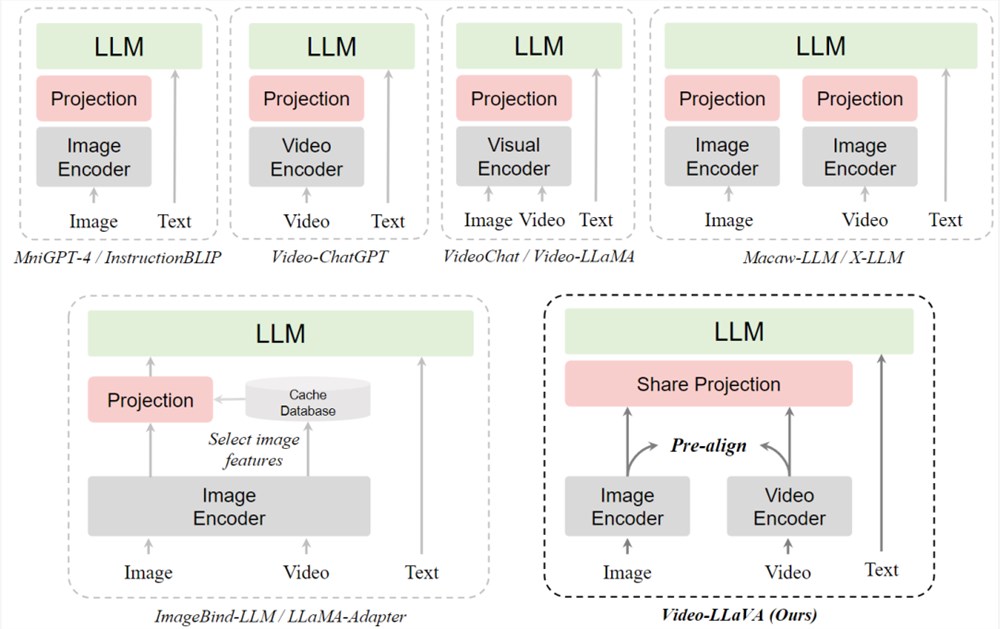
最近的工作将图片或视频通过几个全连接层映射成类似文本的token,让LLM涌现理解视觉信号的能力。
然而,图片和视频是分开用各自的编码器,这对LLM学习统一的视觉表征带来了挑战。并且通过几个映射层教会LLM同时处理图片和视频的性能往往不如视频专家模型如Video-ChatGPT。
对此,来自北大团队认为这种现象源于misalignment before projection。因为图片特征和视频特征在送入LLM之前就已经收敛到各自的特征域空间,这就给LLM学习它们之间的交互带来了挑战。
,时长00:32
类似的现象如misalignment before fusion,也可以在早期的多模态融合工作被观察到,如ALBEF。
不同视觉语言大模型范式的比较
方法介绍
Video-LLaVA的方法简单有效,不需要额外自己预先训练图片和视频模态的编码器,而是巧妙地通过LanguageBind编码器来预先对齐图片和视频特征,形成统一的视觉表征。
具体来说,Video-LLaVA采用的图片和视频编码器通过共享一个语言特征空间,图像和视频表示最终融合成一个统一的视觉特征空间,称之为图像和视频的emergent alignment。
因此,Video-LlaVA通过LanguageBind预先对视觉输入进行对齐,以减小不同视觉信号表示之间的差距。统一的视觉表征经过共享的投影层后,输入到大语言模型中。
并且Video-LlaVA在训练过程中始终没有用到视频图片成对的数据,而是在训练后发现的LLM会惊人的涌现出同时理解图片和视频。
如下图所示,Video-LlaVA成功的识别出图片的自由女神像是近景且细腻的,而视频描述的是多角度的自由女神像,他们是来源于同一个地方。

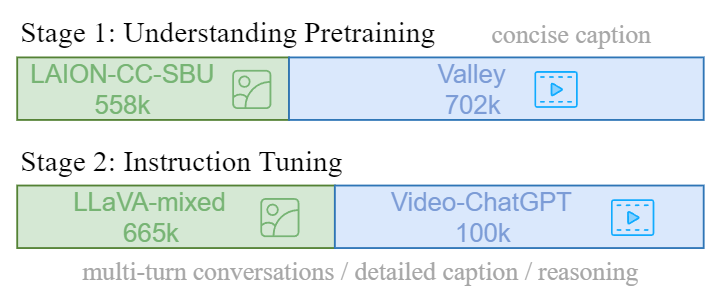
Video-LLaVA采取两阶段的训练策略:
在视觉理解阶段,使用了一个558K个LAION-CC-SBU图像-文本对。视频-文本对是从Valley 提供的子集中获得的,总共有703k对,这些视频源自WebVid。
在指导微调阶段,团队从两个来源收集了指导性数据集,包括来自LLaVA的665k个图像-文本数据集,以及从Video-ChatGPT获得的包含100k个视频-文本数据集。
- 视觉理解阶段
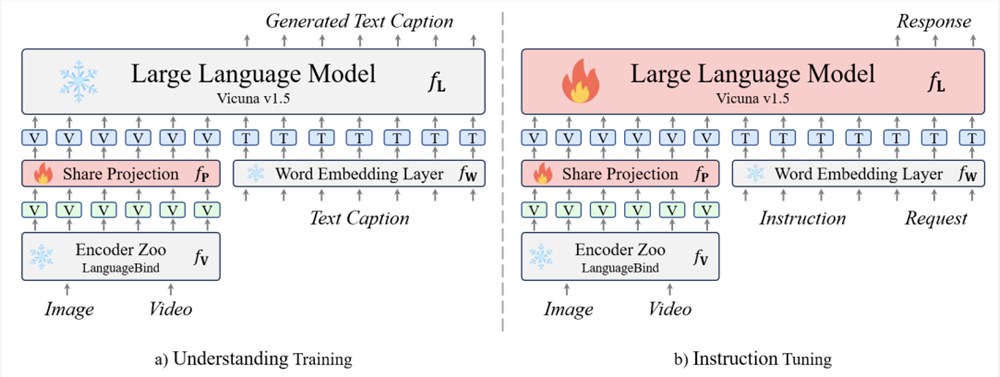
在这个阶段,模型需要通过一个广泛的视觉-文本对数据集来获取解读视觉信号的能力。每个视觉信号对应一个回合的对话数据。
这个阶段的训练目标是原始的自回归损失,模型通过学习基本的视觉理解能力。在此过程中,冻结模型的其他参数。
- 指令微调阶段
在这个阶段,模型需要根据不同的指令提供相应的回复。这些指令通常涉及更复杂的视觉理解任务,而不仅仅是描述视觉信号。需要注意的是,对话数据包含多个回合。
如果涉及多轮对话,输入数据会将所有之前回合的对话与当前指令连接起来,作为本回合的输入。训练目标与前一阶段相同。
经过这个阶段,模型学会了根据不同的指令和请求生成相应的回复。在这个阶段,大语言模型也参与训练。
实验
- 视频理解能力
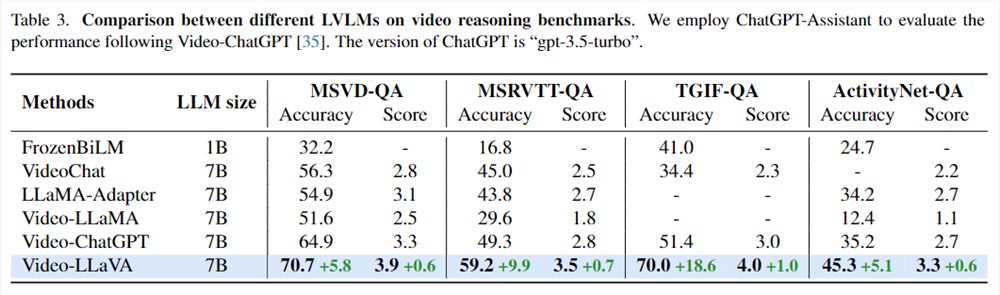
如表3所示,Video-LLaVA在4个视频问答数据集上全面超过了Video-ChatGPT,并且涨幅相当可观。
- 图片理解能力
该研究还与InstructBLIP,Otter,mPLUG-owl 等图片语言大模型在图片语言理解任务上进行了比较,结果如表2所示:

- 预先对齐视觉输入
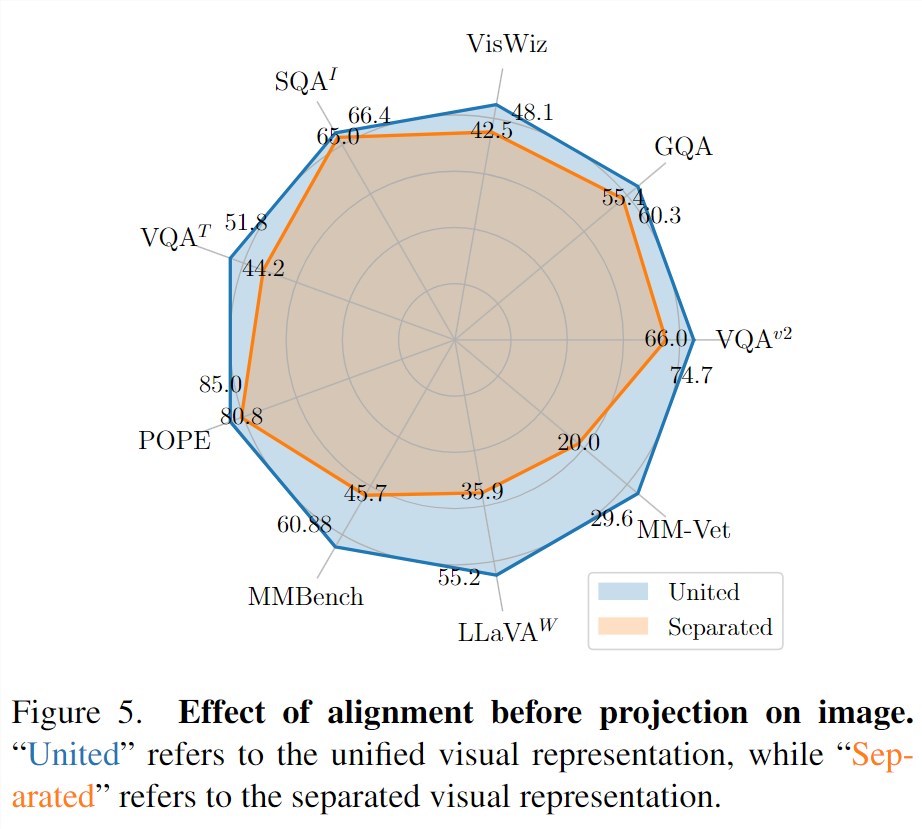
将图片编码器替换相同规模的MAE encoder。定义用MAE encoder是分隔的视觉表示,Languagebind是统一视觉表示(因为预先对齐了视觉表征),并且将MAE encoder和LanguageBind encoder在13个基准上进行对比,这其中包含9个图片理解基准和4个视频理解基准。
对于图片理解,统一视觉表示展现了强大的性能,它在5个图片问答数据集和4个基准工具箱上全面超过了分隔的视觉表示。
另外,我们注意到统一视觉表示在POPE,MMBench,LLaVA-Bench,MM-Vet这四个基准工具箱上的性能以巨大的优势超过。
这突出了预先对齐了视觉表征不仅在图片问答上提升了性能,还在图片理解的其他方面收益,如减小幻觉,提升OCR能力等。
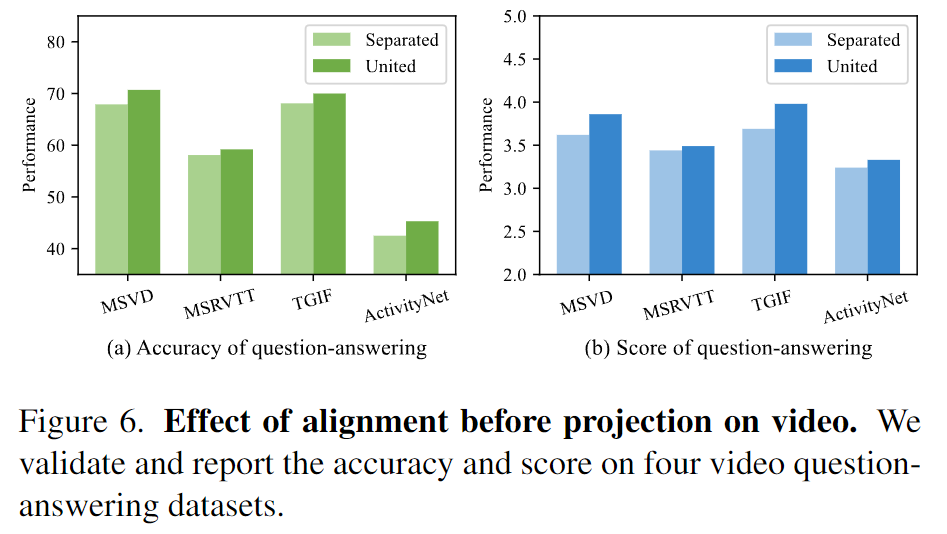
由于替换图片编码器为MAE encoder,视频特征和图片特征在LLM初始学习视觉表示时不再统一。
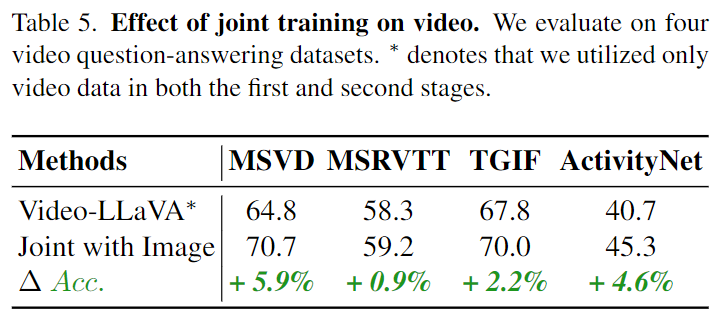
在图6,相比于分隔视觉表示,联合视觉表示在4个视频问答数据集上全面提高了性能。
这些结果展现了预先对齐视觉表征表示能够帮助LLM进一步学习理解视频。
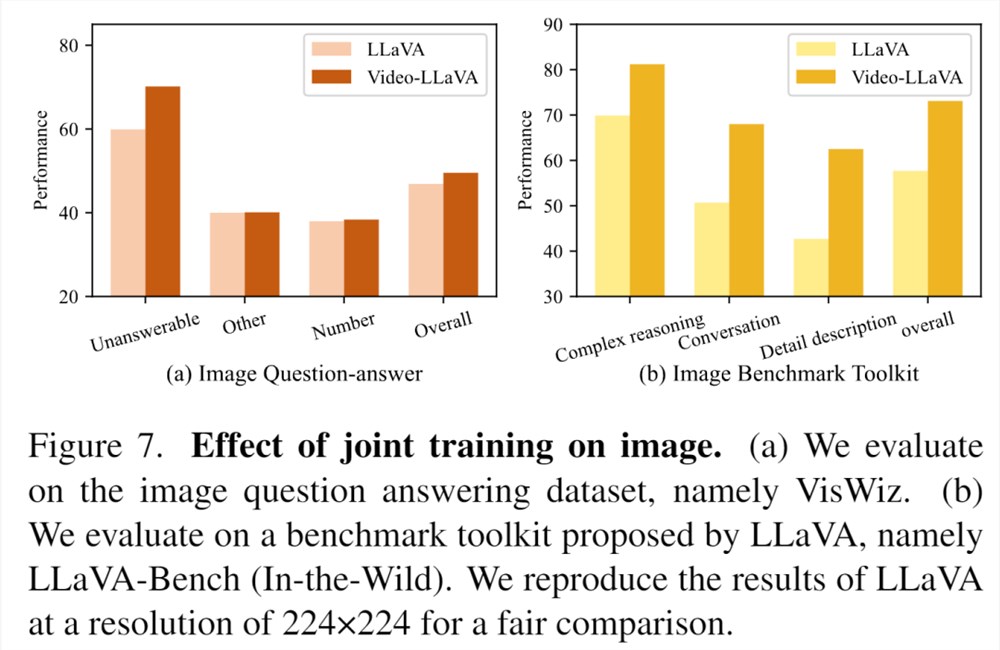
同时论文还验证了无论是对于图片还是视频,在联合训练中他们能相互受益。
对于图片理解,Video-LLaVA在无法回答的和数字上的表现超过了LLaVA-1.5,这意味着联合训练视频使得在图片上的幻觉问题有所缓解,和对图片数字信号的理解能力增强。
相同的趋势在LLaVA-Bench上被观察到,Video数据显著提升了LLM在图片Complex reasoning,Conversation上的表现。
对于视频理解,团队在4个Video问答数据集上评估。
与没有图片参与训练的Video-LLaVA相比,有图片联合训练的模型在4个数据集上全面超过。
这些结果证明了联合图片和视频一起训练能够促进LLM理解视觉表示。
参考资料:
https://github.com/PKU-YuanGroup/ Video-LLaVA
AI合成数据公司“光轮智能”完成天使+轮融资
光轮智能近期完成了天使轮融资。累计融资金额达数千万元人民币,投资方包括SEEFund、变量资本等。据介绍,光轮智能致力于为企业落地AI提供自动化、物理精确可控、真实、可泛化的合成数据解决方案,打造AI时代的数据基础设施。光轮智能开创性的将生成式AI与仿真技术深度融合,提供多模态、高质量、大规模、低成本的合成数据,弥补AI时代的数据缺口。站长网2023-07-25 16:18:390000创新性AI系统SoG: 在各种游戏中击败人类,又能学习玩新游戏
**划重点:**1.🧠**AI性能新标杆:**游戏作为AI性能指标的悠久传统,EquiLibreTechnologies、SonyAI、Amii和Midjourney等研究团队与GoogleDeepMind合作推出的“游戏之子”(SoG)算法,通过定向搜索、自我学习和博弈论推理,在完美和非完美信息游戏中取得显著成果,标志着通用算法迈出了重要一步。站长网2023-11-26 14:17:00000014 Ultra同款!小米Civi 4 Pro升级AI影像大脑3.0
小米Civi4Pro在影像硬件方面的出色表现已经备受瞩目,而官方最新宣布的消息更是让这款手机的摄影能力再上新台阶——它将搭载与小米14Ultra相同的影像大脑3.0,即XiaomiAISP,这款AI大模型计算摄影平台为手机的影像性能提供了强大的支持。站长网2024-03-20 12:01:320000用你的经验,当下马上赚钱!
各位村民好,我是村长。很多人问我怎么靠副业赚钱其实这个问题太简单了因为至少在看村长这篇文章的人几乎都具备靠副业赚钱的能力而且是当下,立刻,马上赚钱!01每个人的经验就是钱!相比于我们每个人四处向外面去找各种所谓的赚钱项目,其实我们自己本身就是一个可以持续变现的产品。我们除了向别人出售我们的时间、体力外,其实还有一样最为重要的东西,就是我们的知识,我们的经验,我们的资源。0000三星Exynos 2400可能采用10核心设计 性能接近苹果M2
据phonearena消息,关于三星Exynos2400SoC的最新消息来自爆料者RGcloudS,他说芯片的最终配置和封装信息仍然悬而未决,因为三星正在权衡其关于芯片组的选择,这可能会为明年的旗舰GalaxyS24系列提供。爆料者还指出,虽然Exynos2400将拥有10个CPU核心,但所有10个核心不会同时运行。相反,将根据每个任务优化使用的核心数量。站长网2023-07-14 00:35:440001












