微软发布小型语言模型Orca 2:仅7亿/13亿参数,媲美Llama-2-Chat-70B
**划重点:**
1. 📊 *Orca2模型在零样本测试中,涵盖语言理解和常识推理等15个多样化基准测试中,与五到十倍更大的模型相匹敌或胜过。
2. 🌐 微软开源了两个规模为7亿和13亿参数的Orca2模型,旨在促进对更小型模型的研究,这有助于有限资源的企业更经济地解决特定应用场景。
3. 🧠 与传统的模仿学习不同,微软研究人员通过精心设计的合成数据集,教授Orca2模型使用不同的解决方案策略,为不同任务提供最有效的解决方案策略。
在OpenAI发生权力斗争和大规模辞职的时刻,微软作为AI巨头的长期支持者,依然在其人工智能努力上不懈努力。微软公司的研究部门今日发布了Orca2,这是一对小型语言模型,经测试在复杂推理任务的零样本设置中,与Meta的Llama-2Chat-70B等五到十倍大的语言模型相匹敌或更胜一筹。
这两个模型分别具有7亿和13亿个参数,是在几个月前展示了强大推理能力的原始13B Orca模型的基础上进行的改进。微软研究人员在一篇联合博客中写道:“通过Orca2,我们继续展示改进的训练信号和方法可以使较小的语言模型获得增强的推理能力,这通常只在更大型的语言模型中找到。”
公司已经将这两个新模型开源,以促进对能够与更大模型一样出色执行的较小模型的开发和评估的进一步研究。这项工作为那些资源有限的企业提供了更好的选择,以解决目标用例而无需过多投资于计算能力。
针对小型模型缺乏推理能力的问题,微软研究决定通过在高度定制的合成数据集上对Llama2基础模型进行微调来解决这一差距。与常用的模仿学习技术不同,研究人员训练模型在不同任务中采用不同的解决方案策略。他们的理念是,较大模型的策略并不总是完美适用于较小模型。例如,GPT-4可能能够直接回答复杂问题,但没有这种能力的较小模型可能通过将相同任务分解为几个步骤而受益。
研究人员在今天发表的一篇论文中写道:“在Orca2中,我们教授模型各种推理技巧(逐步,回忆然后生成,回忆-推理-生成,直接回答等)。更关键的是,我们旨在帮助模型学会为每个任务确定最有效的解决方案策略。”项目的训练数据是从更强大的教师模型中获得的,以这样一种方式获取数据,以教授学生模型处理如何使用推理策略以及何时对手头的特定任务使用它。
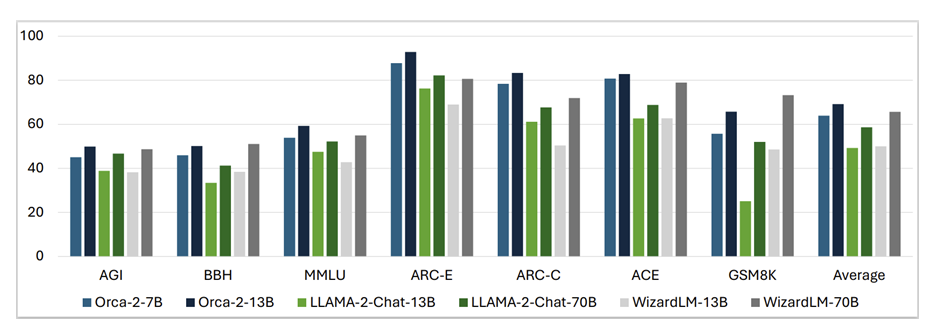
在15个多样化的基准测试中,涵盖语言理解、常识推理、多步推理、数学问题解决、阅读理解、摘要和真实性等方面,Orca2模型在零样本设置中表现出色,大多数情况下匹配或超过了五到十倍规模更大的模型。
所有基准测试结果的平均值显示,Orca2的7B和13B版本胜过了Llama-2-Chat-13B和70B以及WizardLM-13B和70B。唯独在GSM8K基准测试中,包含8.5K高质量小学数学问题,WizardLM-70B的表现确实比Orca模型和Llama模型更为出色。
尽管这些性能对于希望在经济应用中获得小型高性能模型的企业团队来说是个好消息,但值得注意的是,这些模型也可能继承其他语言模型以及它们微调的基本模型的常见限制。
微软补充说,用于创建Orca模型的技术甚至可以应用于其他基础模型。研究团队写道:“尽管它有一些局限性...,但是Orca2在未来推理、专业化、控制和较小模型的安全性方面的潜力是显而易见的。对精心筛选的合成数据进行后训练在这些改进中是一个关键策略。随着更大的模型不断取得进展,我们与Orca2的合作在多样化语言模型的应用和部署选项方面迈出了重要一步。”
随着Orca2模型的开源发布和该领域正在进行的研究,可以安全地说未来可能会涌现更多高性能的小型语言模型。就在几周前,中国最近刚刚成为独角兽的01.AI,由资深AI专家李开复创立,也在这一领域迈出了重要的一步,发布了一个支持中文和英文的340亿参数模型,胜过了70亿Llama2和180亿Falcon等竞品。这家初创公司还提供了一个培训有60亿参数的较小选项,并在广泛使用的AI/ML模型基准测试中表现不俗。
六个月前在巴黎创立并以其独特的Word Art标志和创纪录的1.18亿美元种子轮融资引起轰动的Mistral AI公司,也提供了一个7亿参数的模型,优于Meta的Llama213B(Meta较新模型中的较小型号之一)。
微软博客介绍:https://www.microsoft.com/en-us/research/blog/orca-2-teaching-small-language-models-how-to-reason/
继苹果DMA变更后,Opera 将在欧洲推出适用于 iOS 的全新 AI 浏览器
站长之家(ChinaZ.com)1月29日消息:挪威浏览器开发商Opera今天宣布,他们计划在欧洲推出一款全新的人工智能浏览器,该浏览器将基于Opera自家的iOS引擎构建。这一宣布是在苹果公司表示将允许替代浏览器引擎在iOS上运行之后的消息,这一变化是应欧洲数字市场法案(DMA)的要求。站长网2024-01-29 09:33:590001报道称爆火的AI大模型 Kimi 每天获客成本或超20万元
划重点:-💥Kimi投放广告的每个用户获客成本约在10元,考虑到用户问答互动产生的算力成本,每个用户的获客成本达到12-13元。-💰近一个月来,Kimi在苹果端和安卓端的日均下载量为17805,每天的获客成本将烧掉至少20万元。-📈Kimi大模型在AI行业引起轰动,成为引领长文本处理新浪潮的领军者。站长网2024-03-25 19:11:200000编剧、导演福音!StoriaBoard:由AI驱动的故事可视化工具
StoriaBoard是一款由先进的生成式人工智能技术驱动的下一代故事板工具,旨在帮助创作者和制片人将他们的创意变成大银幕上的杰作。无论您是一名编剧、导演还是制片人,StoriaBoard都为您提供了强大的工具,以更轻松、更高效地规划和可视化您的故事。体验地址:https://app.storia.ai/核心功能:站长网2023-09-28 16:01:580001iPhone电池门赔偿金开始发放 网友不买账
近日,iPhone电池门的赔偿金已经开始发放,引起了不少网友的关注。据了解,这起事件始于2017年美国用户对苹果起诉,涉及了iPhone6系列、iPhone7系列等机型。0000从9块9到1149,谁在为AIGC买单?
“在AIGC时代,如果不能在第一天就向用户收费,那么就永远都不可能收到用户的钱。”妙鸭相机产品负责人张月光的一席话不仅点明了妙鸭相机背后的商业思考,同时也揭露了AIGC产品进退不得的商业化困局。AIGC技术尚未进化至完成态,技术的局限与算力成本的重压令AIGC产品“进不得”。站长网2023-08-12 09:50:210000