牛!S-LoRA技术实现单GPU运行数千个LLM,个性化服务AI应用
**划重点:**
1. 🌐 S-LoRA技术由斯坦福大学和加州大学伯克利分校的研究人员合作开发,可显著降低LLM精细调整的成本,使企业能够在单个GPU上运行数百甚至数千个模型。
2. ⚙️ S-LoRA通过动态内存管理系统和"Unified Paging"机制解决了部署多个LoRA模型时的技术挑战,支持在单个GPU或多个GPU上服务多个LoRA适配器。
3. 📈 在评估中,S-LoRA相较于Hugging Face PEFT表现出色,提高了30倍的吞吐量,并成功同时服务了2,000个适配器,为个性化LLM服务在企业应用中创造了可能。
近日,研究人员在解决大型语言模型(LLM)精细调整的高成本和计算资源限制方面取得了重要突破。由斯坦福大学和加州大学伯克利分校的研究人员合作开发的S-LoRA技术,使得在单个图形处理单元(GPU)上运行数千个LLM模型成为现实。
通常,对LLM进行精细调整是企业定制人工智能功能以适应特定任务和个性化用户体验的重要工具。然而,这一过程通常伴随着巨大的计算和财务开销,限制了中小型企业的应用。为解决这一难题,研究人员提出了一系列算法和技术,其中S-LoRA技术成为最新的亮点。
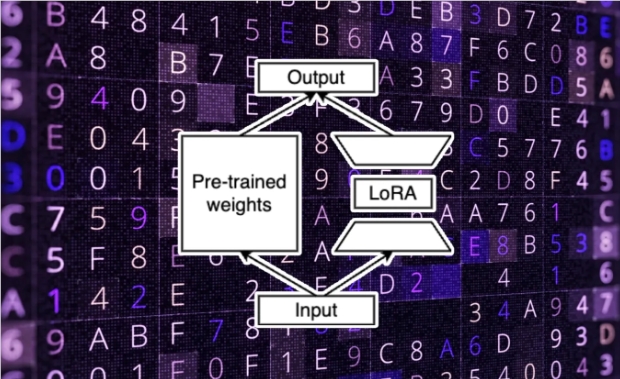
S-LoRA采用了LoRA的方法,该方法由Microsoft开发,通过识别LLM基础模型中足够用于精细调整的最小参数子集,将可调整参数数量减少数个数量级,同时保持与全参数调整相当的准确性水平。这极大地减少了个性化模型所需的内存和计算资源。
尽管LoRA在精细调整中的有效性已经在人工智能社区广泛应用,但在单个GPU上运行多个LoRA模型仍然面临一些技术挑战,主要是内存管理和批处理过程。S-LoRA通过引入动态内存管理系统和"Unified Paging"机制成功解决了这些挑战,实现了多个LoRA模型的高效服务。
在评估中,S-LoRA在服务Meta的Llama模型时表现出色,相较于Hugging Face PEFT,吞吐量提高了30倍,同时成功服务了2,000个适配器,而计算开销增加微不足道。这使得企业能够以较低的成本提供个性化的LLM驱动服务,从内容创作到客户服务等领域都有广泛应用前景。
S-LoRA的研究人员表示,该技术主要面向个性化LLM服务,服务提供商可以通过相同的基础模型为用户提供不同的适配器,这些适配器可以根据用户的历史数据进行调整。此外,S-LoRA还支持与上下文学习相容,通过添加最新数据作为上下文,进一步提升LLM的响应效果。
该技术的代码已经在GitHub上开源,研究人员计划将其整合到常见的LLM服务框架中,以便企业能够轻松地将S-LoRA纳入其应用中。这一创新为企业提供了更广阔的LLM应用空间,同时降低了运行成本,推动了个性化AI服务的发展。
世界读书日,跟你聊聊图书行业有多惨
你知道吗?中国读书最多的群体是小学生。统计数据显示,去年小学生人均读书14.3本,是成年人的3倍。同时他们还是纸质书消费大户,纸质书、电子书阅读比例约为9:1。这一数据在小学生们成年之后迅速下降为4.7本。伴随着短视频、播客、直播的崛起与火热,人们对书的热情越来越低,尤其在纸质书消费方面,人们不再“买书如山倒”。站长网2023-04-23 14:11:460000AI图像生成工具Visual Electric发布多张图像组合重绘功能
昨晚,AI图像生成工具VisualElectric推出了两个强大的功能,为AI图像创作流程降低了门槛。首先,它允许用户将生成的多张图像进行组合并进行重绘。其次,用户可以利用几张图片快速自定义图像生成风格,类似于Lora训练的方式。站长网2023-12-15 12:02:410000AI视频生成的2024,Sora务虚、即梦和可灵务实
自从ChatGPT成为有史以来最快突破亿级用户规模的消费级应用,AI行业的大变局就到来了。随后大家开始谈起了AI会给人类社会带来的深刻变革与挑战,比尔·盖茨甚至认为AIGC(生成式人工智能)的重要性不亚于互联网的发明,将改变我们的世界。0000周鸿祎:2025年这7大风口最赚钱 单身经济排第一
快科技12月26日消息,近日,360集团创始人周鸿祎通过其个人社交账号发布了一条以2025年赚钱7大风口”为主题的视频。在视频中,他指出,2025年7大赚钱风口分别是单身经济、银发经济、绿色有机食品、出海业务、懒人经济、自媒体以及人工智能大模型为代表的技术红利。0002雷军五四青年节演讲登上人民日报:敢做梦才有机会改变世界
快科技5月4日消息,今天是5月4日,正值第75个五四青年节和五四运动105周年,人民日报发布了雷军献给青春的演讲,讲述了雷军对于如何追寻梦想的脚步,成就更好未来的答案。雷军表示,现在很多人似乎总是羞于提及梦想,担心别人看笑话,但是敢做梦才有机会改变世界。不要让一时的迷茫,遮住你眼中的光芒,不要让一时的磨难,抹掉你的勇气,青年就该有青年的胆魄,青年就该有青年的锐气。”雷军说道。0001