超强大模型DEJAVU 推理速度是FasterTransformer的2倍
要点:
DEJAVU 是一个系统,采用一种经济高效的算法,结合异步和硬件感知实施,动态预测每一层的上下文稀疏性,从而提高大型语言模型(LLM)的推断速度。
研究团队通过引入上下文稀疏性的概念,动态修剪特定的注意力头和MLP参数,而无需改变预训练模型,以提高LLM在具有严格延迟约束的应用中的效率。
DEJAVU 通过硬件感知的稀疏矩阵乘法实施,显著降低了开源LLM(如OPT-175B)的延迟,超过了Nvidia的FasterTransformer库,并在小批量大小下超过了广泛使用的Hugging Face实现。
大型语言模型(LLM),如GPT-3、PaLM和OPT,以其卓越的性能和能够在上下文中学习的能力,令人叹为观止。然而,它们在推断时的高成本是它们的显著缺点。为了解决这一挑战,研究团队提出了DEJAVU系统,该系统采用了一种经济高效的算法,结合异步和硬件感知的实施,动态预测每一层的上下文稀疏性,从而提高LLM的推断速度。
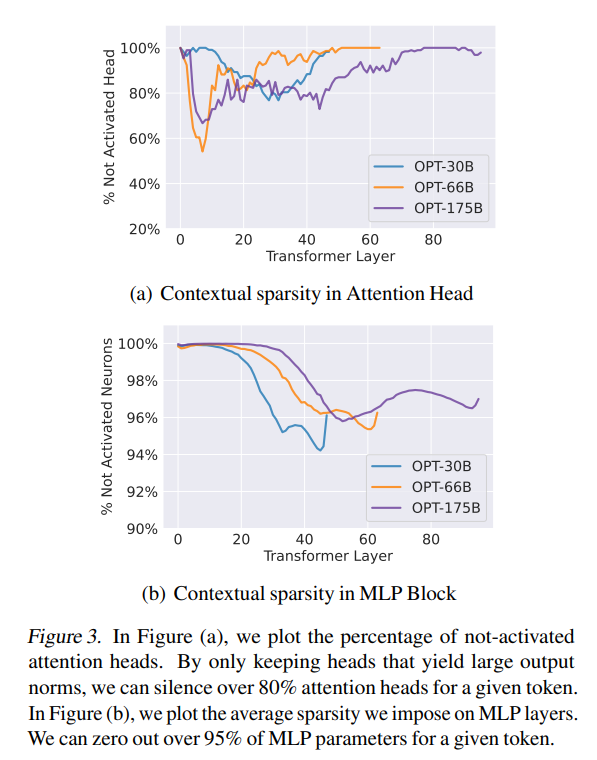
为了定义适用于LLM的理想稀疏性,研究团队提出了三个关键标准:不需要模型重新训练、保持质量和上下文学习能力以及提高现代硬件上的时钟时间速度。为了满足这些要求,他们引入了上下文稀疏性的概念,该概念包括产生与给定输入几乎相同结果的小型、依赖于输入的注意力头和MLP参数的子集,而无需完全模型。DEJAVU利用上下文稀疏性,使LLM在具有严格延迟约束的应用中更加高效。
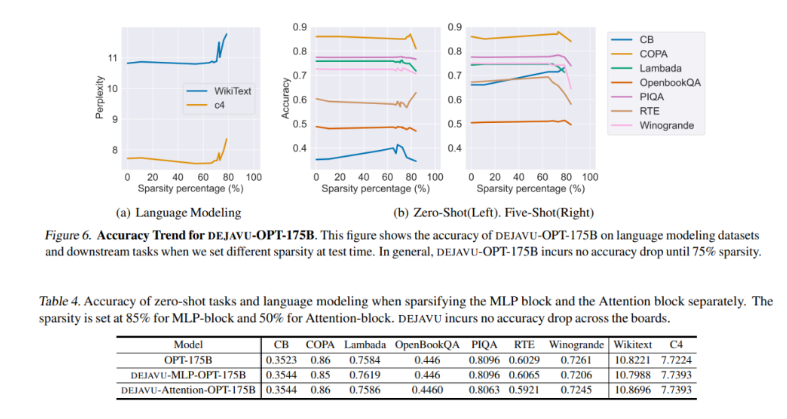
具体来说,研究人员提出了一种低成本的、基于学习的算法,用于实时预测稀疏性。给定特定层的输入,该算法预测后续层中的相关注意力头或MLP参数的子集,并仅为计算加载它们。他们还引入了一种异步预测器,类似于经典的分支预测器,以减少顺序开销。通过引入硬件感知的稀疏矩阵乘法实施,DEJAVU显著降低了开源LLM(如OPT-175B)的延迟。它在端到端延迟上超过了Nvidia的FasterTransformer库,而在小批量大小下也超过了广泛使用的Hugging Face实现。
这项研究表明,DEJAVU有效地利用了异步前瞻预测器和硬件高效稀疏性,以提高LLM的时钟时间推断。这些有前途的实验结果突显了上下文稀疏性在显著减少推断延迟方面的潜力,相较于现有模型,这项研究使LLM更容易被更广泛的AI社区使用,可能开启令人兴奋的新的AI应用。
陶哲轩:GPT-4神助攻,写Python代码轻松省半小时
【新智元导读】陶哲轩早就预言,2026年GPT能帮数学家合著论文。今天,GPT-4就帮他写出一段代码,直接节省了半小时的工作量。刚刚,陶哲轩大赞:用ChatGPT写Python代码,效果真是太好了,它直接为我节省了数学研究中半小时的工作量!作为实验,他要求ChatGPT写一段Python代码,为每个自然数n计算1,...,n的最长子序列的长度𝑀(𝑛),其中欧拉全能函数ϕ不递减。站长网2023-09-03 08:59:450000微软Teams AI库来了! 可帮助公司创建消息机器人
据外媒报道,微软Teams的AI库将于10月正式投入全球运行。AI库是一系列代码功能,目的是帮助开发者更轻松地在MicrosoftTeams中集成大规模语言模型,从而构建出会话式的Teams应用,提高企业工作效率。站长网2023-09-14 21:38:100000人工智能芯片初创公司 D-Matrix 在微软支持下融资 1.1 亿美元
站长之家(ChinaZ.com)9月7日消息:总部位于硅谷的人工智能芯片初创公司D-Matrix已从多个投资者那里筹集了1.1亿美元的资金,其中包括微软公司,目前许多芯片公司面临融资困境。据路透社采访的消息人士称,由于英伟达在AI芯片市场上的占主导地位,其强大的硬件和软件组合使得一些初创公司的潜在投资者却步。站长网2023-09-07 10:04:210000GPT-4调教指令揭秘,OpenAI又「Open」了一回!网友在线追问GPT-5
【新智元导读】GPT-4越来越懂事了,这背后有着非常巧妙的「调教」策略。OpenAI最新发布的「模型规范」,给LLM列出了条条框框,即正确的行为方式。没想到,评论区一大片网友催更GPT-5。这周既没有GPT-5,也没有搜索引擎的发布,不过,OpenAI也是没闲着。这次,OpenAI可是又open了一回。先是揭秘了,大家一直揪着不放的「数据」问题。站长网2024-05-14 10:37:100000归母净利润暴增2748%!阿里发布2024财年半年报
快科技12月24日消息,近日,阿里巴巴发布2024财年中期报告(截至2023年9月止六个月),报告期内实现归母净利润620.38亿元,同比增长达2748%。报告显示,在报告期内阿里巴巴实现收入4589.46亿元,同比增长11%;经营利润760.74亿元,同比增长52%。归母净利润620.38亿元,同比增长2748%;摊薄每股收益3.01元,同比增长达2849%。0000