谷歌发布PaLI-3视觉语言模型 小体量达到SOTA!
要点:
1. 谷歌发布了一款名为PaLI-3的视觉语言模型,它在更小的体量、更快的推理速度下取得了更强的性能,在多个任务中达到了SOTA水平。
2. PaLI-3采用了对比预训练方法,深度探索了VIT的潜力,并在多语言模态检索中表现出卓越性能,凸显了其在定位和文本理解任务中的优越性。
3. 这款模型的成功突显了较小规模模型在实际应用和高效研究中的价值,提供了强大的性能和1/10参数的替代方案,有望改变视觉语言领域的发展。
谷歌最新发布的PaLI-3视觉语言模型(PaLI-3)在小体量下实现了SOTA性能,引起广泛关注。这款模型以更小的体量和更快的推理速度实现更强大的性能,是谷歌去年推出的多模态大模型PaLI的升级版。
通过对比预训练方法,研究人员深入研究了视觉-文本(VIT)模型的潜力,从而在多语言模态检索中达到了SOTA水平。这一成功凸显了较小规模模型在实际应用和高效研究中的重要性,提供了强大性能和低参数需求的替代方案,有望推动视觉语言领域的发展。
论文地址:https://arxiv.org/pdf/2310.09199.pdf
视觉语言模型在人工智能领域发挥着重要作用,PaLI-3将自然语言理解和图像识别完美融合,成为AI创新的先锋。与其他模型如OpenAI的CLIP和Google的BigGAN类似,这些具有文本描述和图像解码能力的模型推动了计算机视觉、内容生成和人机交互等领域的发展,成为科学研究和商业发展的核心力量。
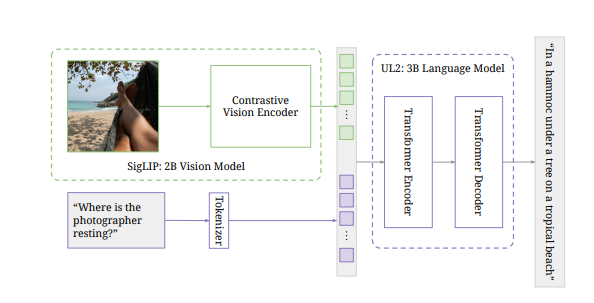
PaLI-3的内部结构采用了预训练的VIT-G14作为图像编码器,并使用SigLIP的训练方法,其中VIT-G14的20亿参数是PaLI-3的基石。对比预训练在图像和文本嵌入后关联特征层面,将视觉和文本特征合并后输入到30亿参数的UL2编码-解码器语言模型中,实现了精确的文本生成,也可用于特征任务的查询提升,如视觉问答(VQA)。
总的来说,PaLI-3在视觉语言模型领域表现出色,特别在定位和视觉文本理解等任务中取得了卓越的性能。它的基于SigLIP的对比预训练方法开辟了多语言跨模态检索的新时代。这一模型在多个任务和数据集上都展现出杰出表现,为视觉语言领域的研究和应用带来了新的可能性。
虽然PaLI-3尚未完全开源,但已发布了多语言和英文SigLIP Base、Large和So400M模型,为感兴趣的研究人员提供了尝试的机会。这一创新有望影响视觉语言模型的未来发展方向,提供更高效的解决方案。
快2025了,电商该把流量成本打下来了
每个行业本身都有自己的发展路线,趋势使然。就像当年,大家苦于层层经销商加价,慢慢质变,电商应运而生;而这次,流量重税之下,历史的齿轮也开始转动。2024年接近尾声,回顾过去一年,电商行业经历了许多变化。0000单场点赞破2亿、曹云金“相声直播”冲击线下剧场生态
“专业能力真的很厉害。直播从相声发展历史,马三立、马季、姜昆、冯巩等相声大师的特点、段子,娓娓道来,娴熟自如。非泛泛之辈能比。”“还是郭德纲最好的徒弟,云鹤九霄不如一曹。”凭借着“相声直播”,曹云金翻红了。在视频评论区,几乎全是对他专业能力的夸赞,对德云社其他人的“踩”,而昔日那段与师父郭德纲的恩怨,以及随之崩盘的人设和口碑,网络评论区刷屏的“孽徒”,也实现了反转。站长网2023-05-25 14:12:430000美国众议院众多党派领导人携手成立跨党派人工智能特别工作组
**划重点:**1.🏛️美国众议院两党领导人宣布成立人工智能特别工作组,致力于应对人工智能的迅猛崛起。2.🤝特别工作组由约翰逊(共和党)和杰弗里斯(民主党)领导,将制定关于人工智能的潜在监管框架和国会可采取的政策步骤的全面报告。3.💼特别工作组的主席是奥伯诺尔特(共和党)和刘特(民主党),成员包括来自两党的国会议员,旨在推动人工智能领域的合作和立法进展。站长网2024-02-21 10:24:250000数据:中国智能手机销量于2023年618促销季年同比下降8%
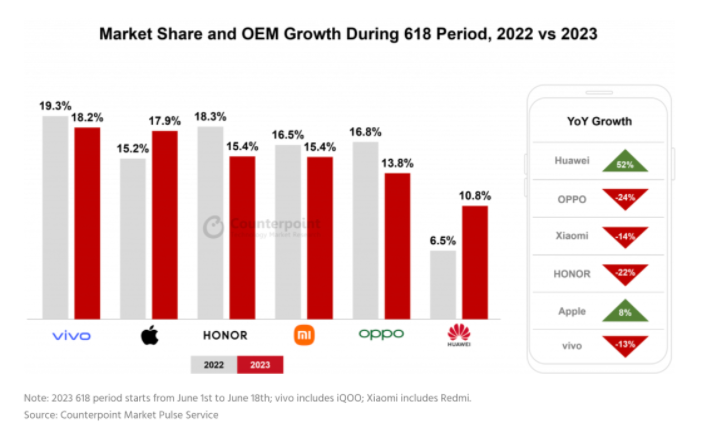
根据Counterpoint发布的618促销季主题报告,中国智能手机销量在2023年的618促销季(6月1日至6月18日)同比下降了8%。在智能手机品牌的竞争格局方面,vivo以18.2%的市场份额位居榜首,其次是苹果(17.9%)和荣耀(15.4%)。苹果公司在高端市场表现出色,年同比增长了8%,而在高端市场上没有强大的竞争对手。为了扩大iPhone的销量,电商网站提供了约20%的折扣。站长网2023-07-12 07:08:140001周鸿祎开启首堂AI免费课:称PPT是忽悠人的最好工具
360集团的创始人及董事长周鸿祎今日在首堂AI免费课直播中分享了他对PPT的看法。他直言不讳地指出,PPT实际上是一种极具忽悠性的工具,那些内容的空洞和思想的不足,常常可以借由华丽的图像和精彩的金句得以掩饰。周鸿祎进一步表示,在他的公司内部,PPT是被禁止使用的,只有在对外交流时才会使用。他的这一观点显示了他对于真实、深入的沟通和交流的重视。站长网2024-02-29 16:23:420000