谷歌研究:大型语言模型难以自我纠正推理错误
站长网2023-10-19 09:20:491阅
谷歌研究表明,大型语言模型在没有外部指导的情况下难以自我纠正推理错误
谷歌 DeepMind 最新研究发现,大型语言模型 (LLM) 在没有外部指导的情况下难以自我纠正推理错误。
这项研究结果对于开发更智能的语言模型具有重要意义。
在一篇名为《大型语言模型尚不能自我纠正推理》的论文中,谷歌 DeepMind 的科学家们进行了一系列实验和分析,以探究语言模型的自我纠正能力。研究人员发现,当模型试图仅仅根据自身的想法来纠正其最初的反应时,往往会出现问题。

图源备注:图片由AI生成,图片授权服务商Midjourney
此前的一些研究表明,语言模型在内部进行自我纠正是有效的。但谷歌的研究发现,这些研究在指导模型时使用了 "预言",即正确的标签。如果没有这些 "预言",模型的准确性并不会提高。
谷歌 DeepMind 的研究人员表示,为了使语言模型正常工作,它们需要具备自我纠正的能力,因为在许多现实世界的应用中,外部反馈并不总是可用的。
研究团队还尝试了一种多智能体方法,即部署多个语言模型以实现一致性响应。虽然没有一个模型能够每次都产生相同的结果,但通过投票机制,可以达成一致的响应。
然而,研究人员指出,这种改进并非真正的自我纠正,而是一种自我一致性。要使语言模型真正具备自我纠正的能力,仍需更多的研究和改进。
谷歌 DeepMind 的研究人员认为,目前对于需要更安全响应的应用程序来说,具备自我纠正能力的语言模型可能更加有效。但他们也呼吁研究人员应该保持敏锐的视角,认识到自我纠正的潜力和局限性,并努力改进现有模型。
尽管目前大型语言模型在自我纠正推理方面还存在一些挑战,但这项研究为未来的发展提供了重要的指导,让我们更好地了解和改进语言模型的能力和局限性。
0001
评论列表
共(0)条相关推荐
OpenAI 敦促联邦法官驳回一起诽谤诉讼
人工智能公司OpenAI要求联邦法官驳回电台主持人MarkWalters的诽谤诉讼。诉讼围绕着聊天机器人ChatGPT向记者FredRiehl提供的虚假信息展开。OpenAI在上周提交的文件中表示,ChatGPT向Riehl传递的错误信息并不构成诽谤。OpenAI认为,作为一个AI语言模型,ChatGPT没有故意欺骗或恶意的能力,这是构成诽谤的必要要素。站长网2023-07-25 17:30:070000视频号到大声谈钱的时候了
最近,资深从业者欧阳(化名)决定从某头部MCN机构离职,投身视频号开始新的创业。在他看来,视频号的红利期只剩不到一年,需要抓紧了。但与此同时,不少从业者认为,因为基建不完善、流量不精准、方法难掌握、用户老龄化等问题,视频号仍处于早期阶段,还需要继续观望。站长网2023-09-20 17:53:490000Anthropic公布AI人工智能安全级别ASL系统
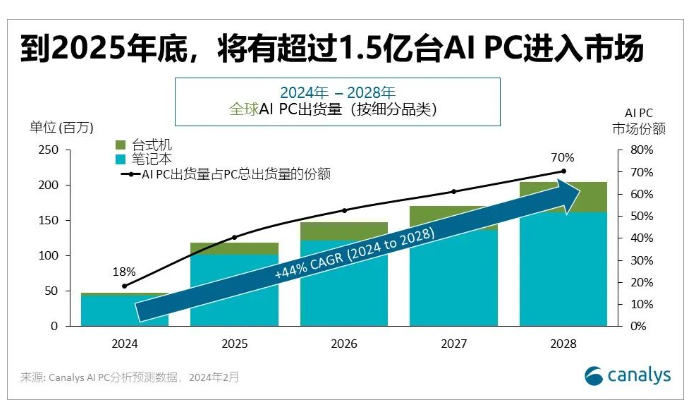
Anthropic创始人DarioAmodei在英国人工智能安全峰会上介绍了该公司提出的负责任扩张政策(ResponsibleScalingPolicy,RSP)。该政策旨在确保人工智能系统的安全性和可控性,防止潜在的风险和滥用。RSP包括两个主要组成部分:ASL系统和缩放曲线。站长网2023-11-03 09:09:110002报告:预计到2025年,AI PC将占全球PC出货量的40%
划重点:⭐Canalys最新预测显示,到2025年,AIPC将占全球PC出货量的40%。⭐AIPC的快速普及将推动PC市场的价值增长,带来更好的用户体验和高端化趋势。⭐Canalys提出AIPC将对整个行业产生深远影响,为厂商和合作伙伴带来巨大的价值收益。站长网2024-03-20 12:01:330000微信PC端更新!终于可以多开文章了,超爽?
本文转载自运营公举小磊磊(公众号ID:gongjulei),免费阅读200万字新媒体运营知识,提升新媒体运营能力。教你自媒体怎么做,快速起号赚钱。细心的新媒体人应该发现,前几天微信又更新了!PC客户端微信发生了很大变化,最主要是微信文章支持多开浏览了!绝对能提高现在的工作效率。在PC端打开任意一篇微信文章,出现弹窗,顶部会显示公众号LOGO和文章标题,不过要注意的是LOGO是无法点击的。站长网2023-05-22 09:17:570000