超火迷你GPT-4视觉能力暴涨,GitHub两万星,华人团队出品
GPT-4V来做目标检测?网友实测:还没有准备好。
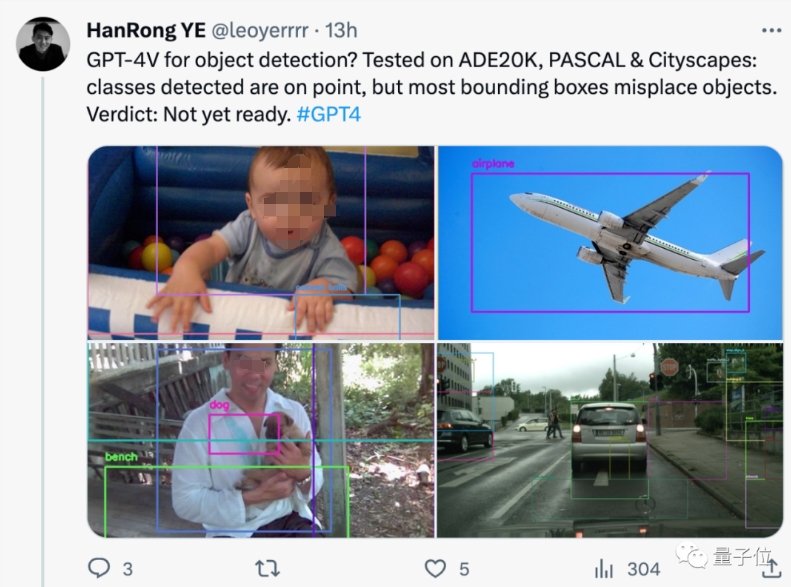
虽然检测到的类别没问题,但大多数边界框都错放了。
没关系,有人会出手!
那个抢跑GPT-4看图能力几个月的迷你GPT-4升级啦——MiniGPT-v2。

△(左边为GPT-4V生成,右边为MiniGPT-v2生成)
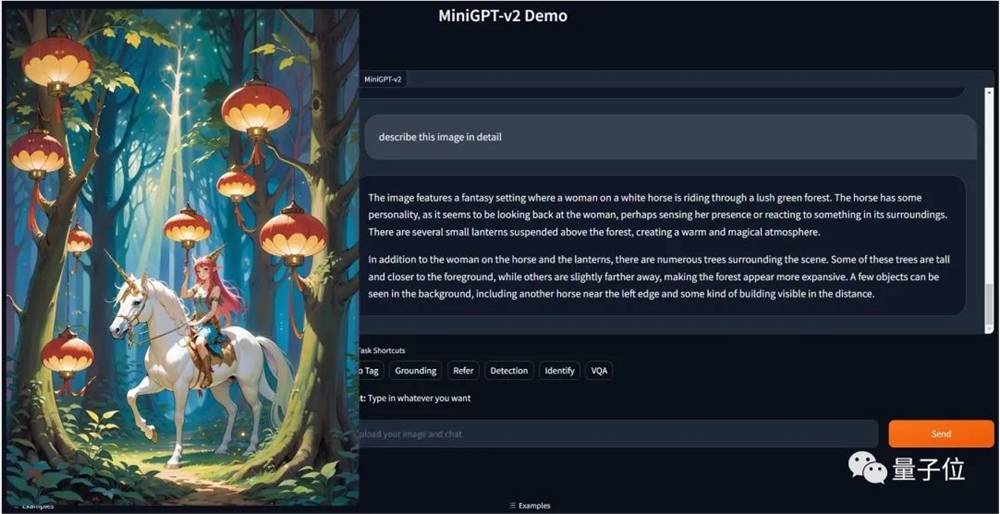
而且只是一句简单指令:[grounding] describe this image in detail就实现的结果。
不仅如此,还轻松处理各类视觉任务。
圈出一个物体,提示词前面加个 [identify] 可让模型直接识别出来物体的名字。

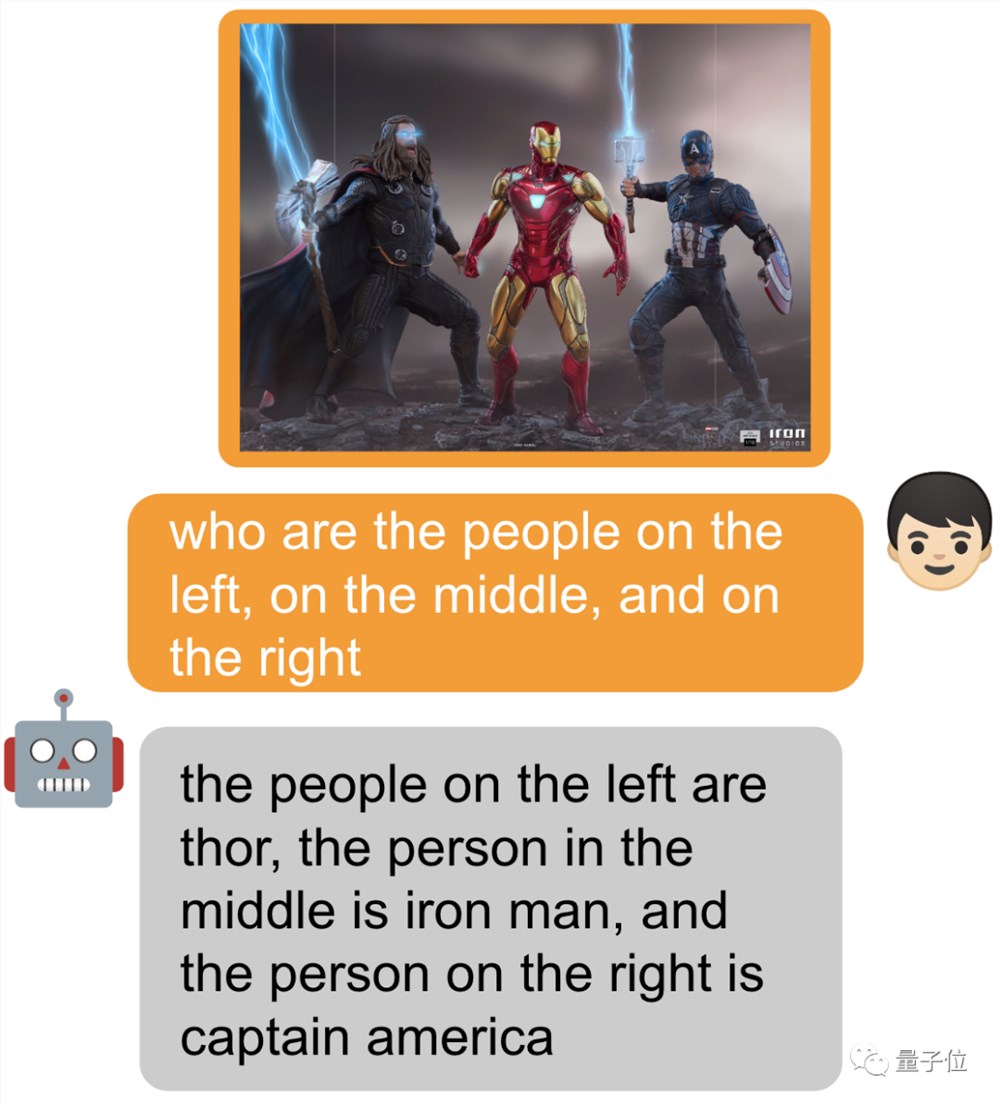
当然也可以什么都不加,直接问~
MiniGPT-v2由来自MiniGPT-4的原班人马(KAUST沙特阿卜杜拉国王科技大学)以及Meta的五位研究员共同开发。

上次MiniGPT-4刚出来就引发巨大关注,一时间服务器被挤爆,如今GItHub项目已超22000 星。
此番升级,已经有网友开始用上了~
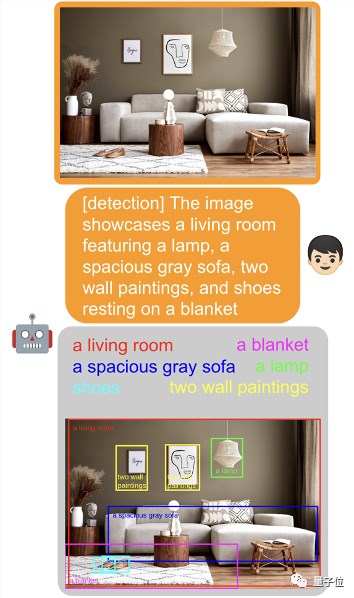
多视觉任务的通用界面
大模型作为各文本应用的通用界面,大家已经司空见惯了。受此灵感,研究团队想要建立一个可用于多种视觉任务的统一界面,比如图像描述、视觉问题解答等。
「如何在单一模型的条件下,使用简单多模态指令来高效完成各类任务?」成为团队需要解决的难题。
简单来说,MiniGPT-v2由三个部分组成:视觉主干、线性层和大型语言模型。
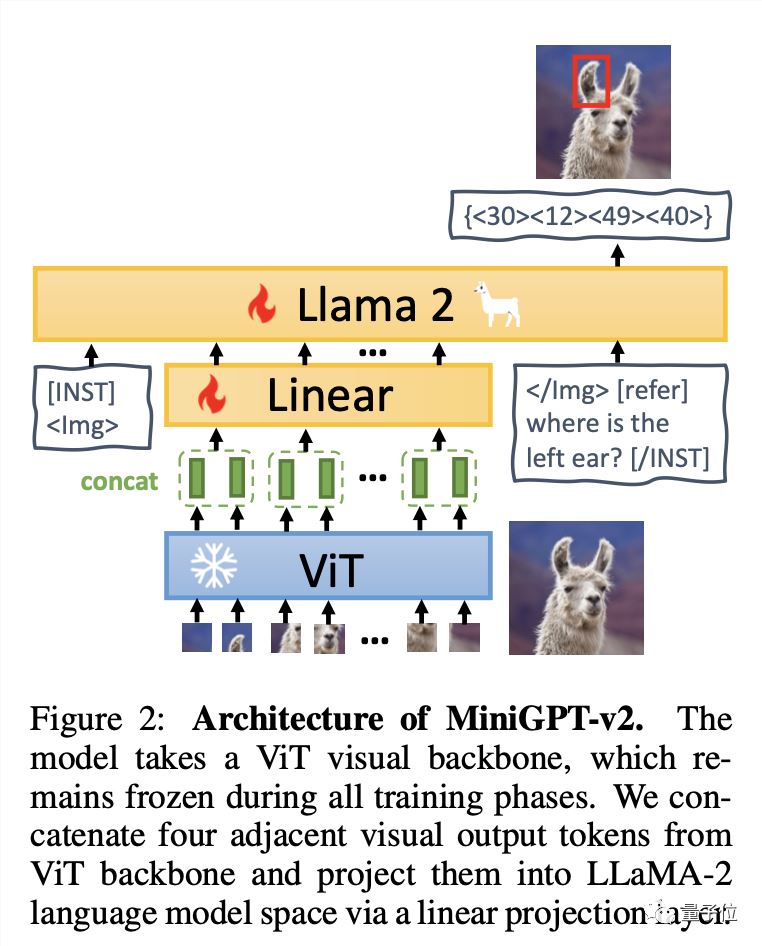
该模型以ViT视觉主干为基础,所有训练阶段都保持不变。从ViT中归纳出四个相邻的视觉输出标记,并通过线性层将它们投影到 LLaMA-2语言模型空间中。
团队建议在训练模型为不同任务使用独特的标识符,这样一来大模型就能轻松分辨出每个任务指令,还能提高每个任务的学习效率。
训练主要分为三个阶段:预训练——多任务训练——多模式指令调整。
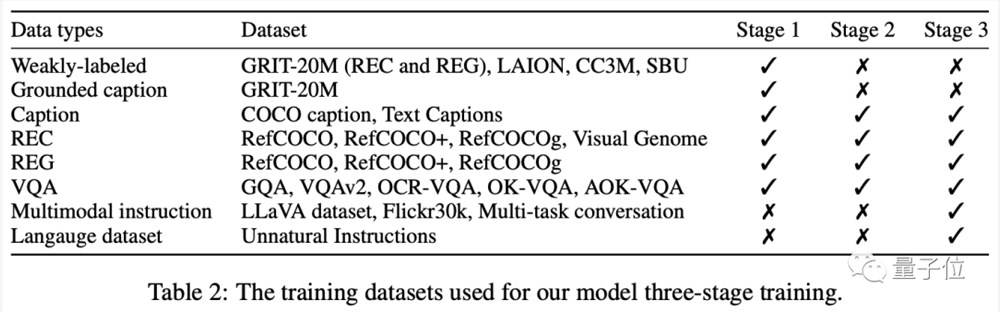
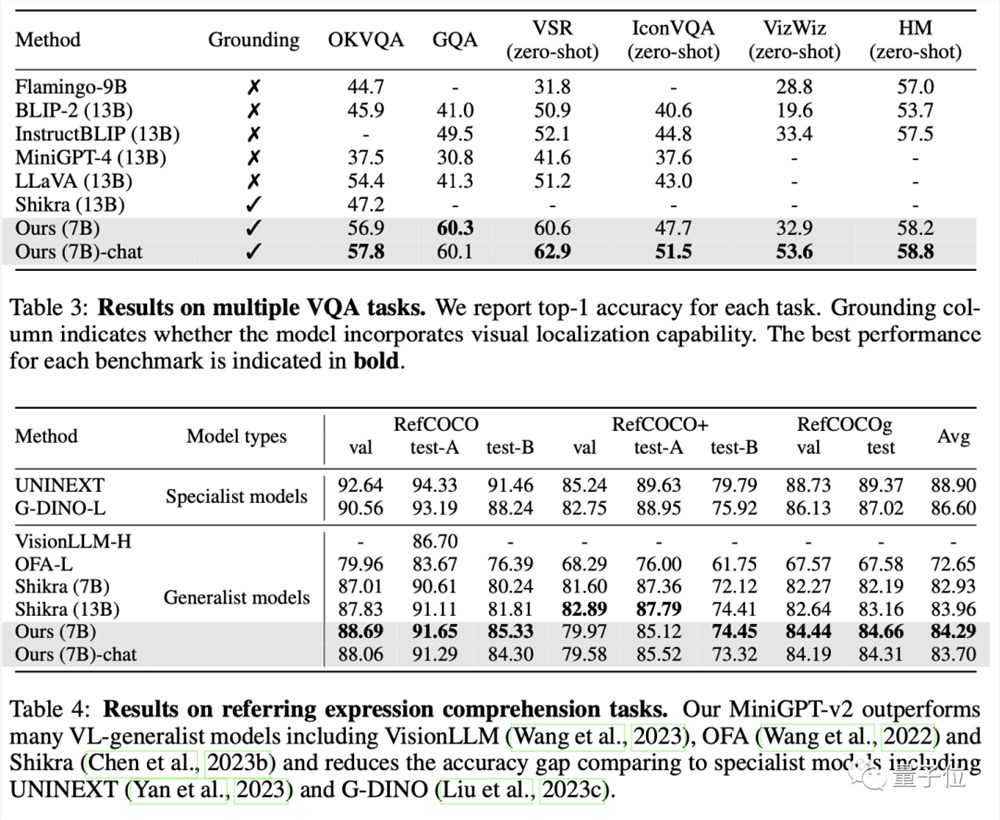
最终,MiniGPT-v2在许多视觉问题解答和视觉接地基准测试中,成绩都优于其他视觉语言通用模型。
最终这个模型可以完成多种视觉任务,比如目标对象描述、视觉定位、图像说明、视觉问题解答以及从给定的输入文本中直接解析图片对象。

感兴趣的朋友,可戳下方Demo链接体验:
https://minigpt-v2.github.io/
https://huggingface.co/spaces/Vision-CAIR/MiniGPT-v2
论文链接:https://arxiv.org/abs/2310.09478
GitHub链接:https://github.com/Vision-CAIR/MiniGPT-4
参考链接:https://twitter.com/leoyerrrr
—完—
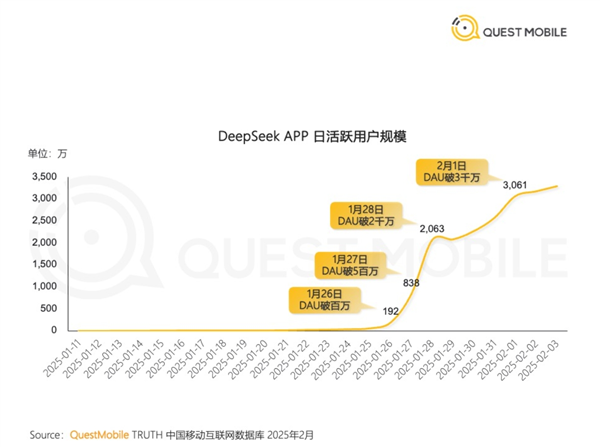
中国AI新秀爆火 DeepSeek成史上最快突破3000万日活App
快科技2月9日消息,今年1月27日,Deepseek应用登顶苹果中国地区和美国地区应用商店免费App下载排行榜,在美区下载榜上超越了ChatGPT,这个中国AI新秀在AI圈内引起了轩然大波。日前,据媒体报道,QuestMobile数据显示,DeepSeek在1月28日的日活跃用户数首次超越豆包,随后在2月1日突破3000万大关,成为史上最快达成这一里程碑的应用。站长网2025-02-10 08:38:560000花30元吃草料,全网近30亿人次围观,国外高校食堂成了新晋流量密码
“我想知道这些东西是饭前吃的?还是饭后吃的?”7月7日,全网千万粉丝的红人“程Yooooo”在韩国首尔大学食堂体验了一顿晚餐后,发出了“灵魂质问”。这份价值25元的餐盘里,有一小碟韭菜、一小份泡菜、5小块肉、一碗汤,再加一份米饭,乍一看堪称是“小菜开会”。这条视频获赞超过40万次,#韩国大学食堂25一份的晚餐#相关话题词条直接登上了抖音热搜前列。站长网2024-07-15 16:13:220001荣耀 100 系列发布 售价 2499 元起
在今晚的新荣耀三周年暨荣耀100系列新品发布会上,荣耀正式发布了荣耀100系列手机,包括荣耀100和荣耀100Pro两款机型,售价从2499元起。站长网2023-11-23 21:58:030001长上下文能力只是吹牛?最强GPT-4o正确率仅55.8%,开源模型不如瞎蒙
【新智元导读】当今的LLM已经号称能够支持百万级别的上下文长度,这对于模型的能力来说,意义重大。但近日的两项独立研究表明,它们可能只是在吹牛,LLM实际上并不能理解这么长的内容。大数字一向吸引眼球。千亿参数、万卡集群,——还有各大厂商一直在卷的超长上下文。从一开始的几K几十K,发展到了如今的百万token级别。Gemini的最新版本可以接收200万个token作为上下文。站长网2024-07-24 01:35:270000深入实用环节,AI如何让剧本“活起来”?|对话猫眼神笔马良项目技术负责人张蒙
影视行业拥抱AI的速度超出我们的想象。AI编剧、AI构图、AI分镜、AI选角、虚拟拍摄、AI辅助制片管理……各种各样的AI产品正在渗入影视产业的各个环节。9月27日,猫眼娱乐发布了首个面向长剧本解析的动态故事板AI生成工具——神笔马良,该产品可根据用户上传的剧本,进行一键智能分析、智能角色创作、智能分镜创作、智能台词朗读,实现剧本内容的视听化呈现。0000