香港中文大学发布全面中文大语言模型评测CLEVA
核心要点:
香港中文大学的研究团队发布了全面的中文大语言模型评测方法,已被EMNLP2023System Demonstrations录取。
该评测方法包含31个任务和多种评测指标,覆盖了84个数据集,着重关注准确性、鲁棒性、公平性等多个维度。
评测方法还提供多样的提示模版,降低数据污染风险,以及提供清晰的操作界面,可供研究团队使用和交互评测。
香港中文大学的研究团队最近发布了一项全面的中文大语言模型评测方法,这一方法已经被EMNLP2023System Demonstrations录取。这一评测方法名为CLEVA,是由香港中文大学计算机科学与工程学系的王历伟助理教授领导的研究团队开发的,与上海人工智能实验室合作研究。
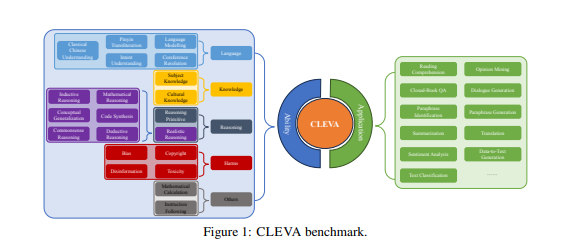
CLEVA的目标是为中文大语言模型提供全面的评测,覆盖多个任务和多个评测指标,以更好地理解和评价这些模型的能力。
论文地址:https://arxiv.org/pdf/2308.04813.pdf
这一评测方法包含了31个任务,其中包括11个应用评估和20个能力评测任务,共涵盖了来自84个数据集的370,000多个中文测试样本。这是过去同类工作中样本数量最多的,为全面评测提供了更多的数据支持。
CLEVA不仅关注传统的准确性指标,还引入了鲁棒性、公平性、效率、校准与不确定性、偏见与刻板印象以及毒性等多维度的评测指标,以更全面地评价大语言模型的性能。
为了确保评测的可比性,CLEVA为每个评测任务准备了一组多个提示模板,使所有模型都使用相同的提示模板进行评测。这有助于公平比较模型能力,同时还可以分析模型对不同提示模板的敏感程度,为模型的下游应用提供指导。
此外,CLEVA还采取了多种方法来降低数据污染的风险,包括采用新数据和不断更新的测试集。
这一全面的中文大语言模型评测方法旨在提供更可信的评测结果,为学术界和工业界提供更准确的模型能力认知。研究团队已经使用CLEVA评测了23个中文大模型,并计划持续评测更多的模型。其他研究团队也可以通过CLEVA网站提交和对接评测结果,从而促进大模型能力的认知和评测。
周鸿祎称余承东是顶级演说家 每年为华为节省10亿广告费
360董事长周鸿祎在今日的朋友圈中,分享了一张与华为常务董事、终端BGCEO、智能汽车解决方案BU董事长余承东的合影。他不仅对余承东表示了高度的赞赏,还表示此次会面是为了向余承东学习。站长网2024-01-18 15:06:520000天涯社区已无法打开 此前官方称技术升级
据网友反映,今日无法访问天涯社区网页及APP,显示页面无法打开或无网络连接。虽然天涯社区的微博和微信账号仍在更新,但截至发稿时尚未对页面无法打开的问题做出回应。此前,天涯社区曾于4月1日发布公告,表示近期将进行技术升级和数据重构,而在此期间将暂停对外服务。技术故障导致的问题尚未确定,但考虑到近年来天涯社区的情况,也不排除其被关闭的可能性。站长网2023-04-25 17:07:320000获取linux内存、cpu、磁盘IO等信息脚本及其原理详解
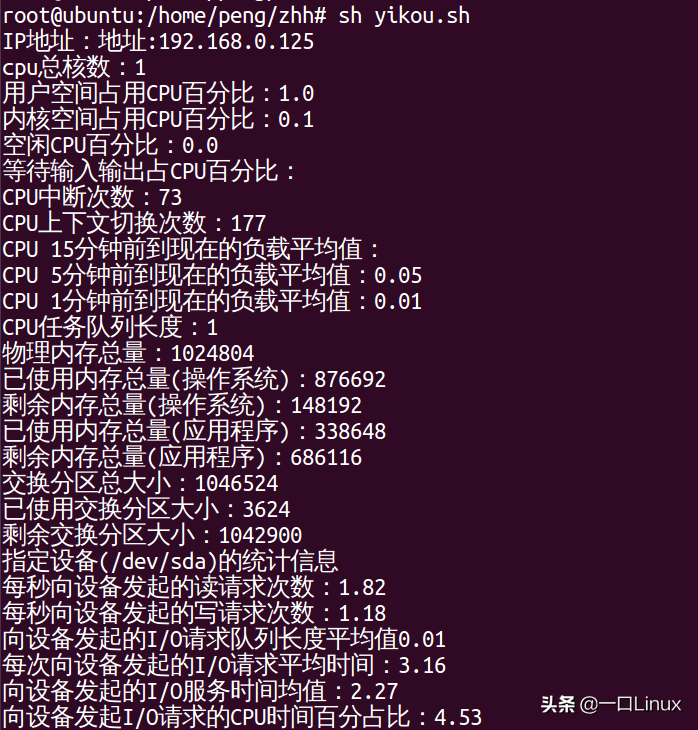
今天主要分享一个shell脚本,用来获取linux系统CPU、内存、磁盘IO等信息。#!/bin/bash#获取要监控的本地服务器IP地址IP=`ifconfig|grepinet|grep-vE'inet6|127.0.0.1'|awk'{print$2}'`echo"IP地址:"$IP#获取cpu总核数站长网2023-05-24 10:52:280000马斯克起诉奥特曼 称OpenAI违背造福人类初衷
旧金山高等法院近日受理了一起引人注目的诉讼案件。特斯拉CEO埃隆·马斯克通过洛杉矶的律师事务所Irell&Manella,以违反合同为由对OpenAI及其CEO萨姆·奥特曼提起了诉讼。站长网2024-03-01 17:40:290000618将近 国家邮政局:合理安排仓储计划和发货节奏
国家邮政局发布《关于做好近期快递服务保障工作的通知》称,近期主要电商平台相继开展集中促销,预计在“618”时间节点迎来阶段性业务高峰,并在端午节和学生暑假前后出现新一波购物需求。通知要求,要制定任务措施,细化责任分工。一是完善工作机制。各地邮政管理部门和各企业总部要健全工作机制,强化工作的组织、指挥和协调。0000