手把手教你剪「羊驼」,陈丹琦团队提出LLM-Shearing大模型剪枝法
给 Llama2(羊驼)大模型剪一剪驼毛,会有怎样的效果呢?今天普林斯顿大学陈丹琦团队提出了一种名为 LLM-Shearing 的大模型剪枝法,可以用很小的计算量和成本实现优于同等规模模型的性能。
自大型语言模型(LLM)出现以来,它们便在各种自然语言任务上取得了显著的效果。不过,大型语言模型需要海量的计算资源来训练。因此,业界对构建同样强大的中型规模模型越来越感兴趣,出现了 LLaMA、MPT 和 Falcon,实现了高效的推理和微调。
这些规模不等的 LLM 适用于不同的用例,但从头开始训练每个单独的模型(即使是10亿参数小模型)还是需要大量计算资源,这对于大多数科研机构而言仍是很大的负担。
因此在本文中,普林斯顿大学陈丹琦团队试图解决以下问题:能否利用现有预训练 LLM 来构建一个规模更小、通用且在性能上有竞争力的 LLM,同时比从头开始训练需要的计算量少得多?
研究者探索利用结构化剪枝来实现目标。这里的问题是,对于通用 LLM,剪枝后的模型会出现性能下降,尤其是在剪枝后没有大量计算投入的情况。他们使用的高效剪枝方法可以用来开发规模更小但仍具有性能竞争力的 LLM,并且与从头开始训练相比,训练需要的计算量也大大减少。

论文地址: https://arxiv.org/abs/2310.06694
代码地址: https://github.com/princeton-nlp/LLM-Shearing
ModelsSheared-LLaMA-1.3B, Sheared-LLaMA-2.7B
在对 LLM 进行剪枝之前,研究者确定了两个关键技术挑战,一是如何确定最终的性能强大、推理高效的剪枝结构?LLM 目前的结构化剪枝技术没有指定的目标结构,导致剪枝后模型在性能和推理速度方面不理想;二是如何继续预训练剪枝后的模型以达到预期性能?他们观察到,与从头开始训练模型相比,使用原始预训练数据来训练会导致不同域出现不同的损失减少。
针对这两个挑战,研究者提出了「LLM - shearing」算法。这种新颖的剪枝算法被称为「定向结构化剪枝」,它将源模型剪枝为指定的目标架构,该结构通过现有预训练模型的配置来确定。他们表示,该剪枝方法在源模型中搜索子结构,并在资源受限的情况下最大程度地保持性能。此外设计一种动态批量加载算法,它能根据损失减少率按比例加载每个域的训练数据,从而高效利用数据并加速整体性能的提升。
最终,研究者将 LLaMA2-7B 模型剪枝成了两个较小的 LLM,分别是 Sheared-LLaMA-1.3B 和 Sheared-LLaMA-2.7B,证实了其方法的有效性。
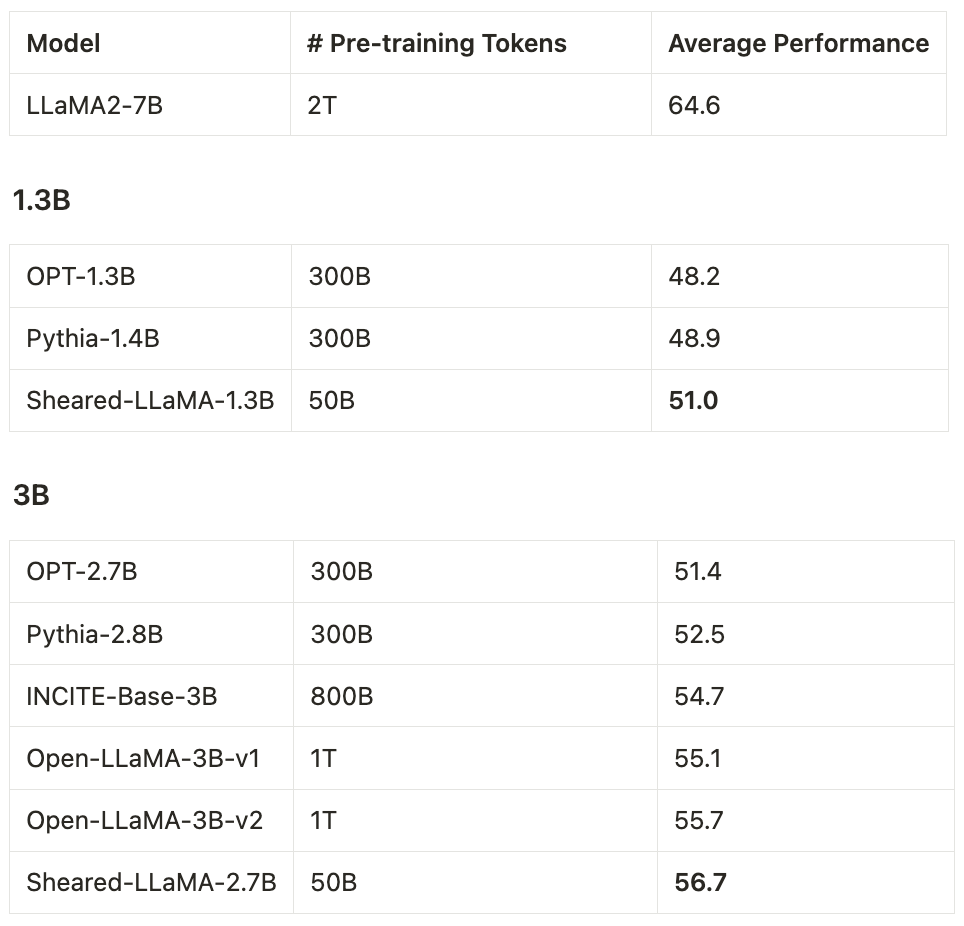
他们仅仅使用500亿个 token(即 OpenLLaMA 预训练预算的5%)进行剪枝和继续预训练,但对于11个代表性下游任务(如常识、阅读理解和世界知识)以及开放式生成的指令调整,这两个模型的性能仍然优于其他同等规模的流行 LLM,包括 Pythia、INCITE 和 OpenLLaMA。
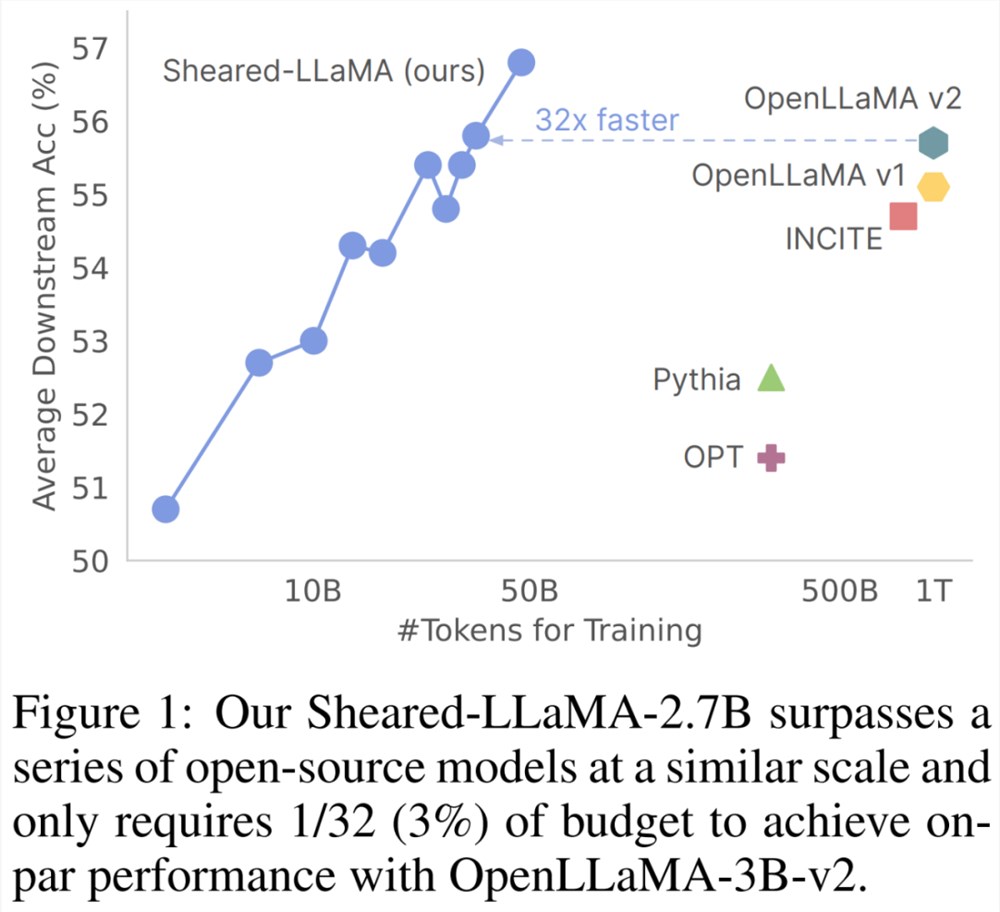
不过要提到一点,在这篇论文发布 Sheared-LLaMA-3B 的时候,最强3B 开源模型的纪录已经被 StableLM-3B 打破了。

此外,下游任务性能轨迹表明,使用更多 token 来进一步训练剪枝后的模型,将带来更大的收益。研究者只对最多70亿参数的模型进行了实验,但 LLM-shearing 具有高度通用性,可以在未来的工作中扩展到任何规模的大型语言模型。
方法介绍
给定一个现有的大模型 M_S(源模型),本文目标是研究如何有效地生成一个更小、更强的模型 M_T(目标模型)。该研究认为这需要两个阶段来完成:
第一阶段将 M_S 剪枝为 M_T,虽然这样减少了参数数量,但不可避免地导致性能下降;
第二阶段持续预训练 M_T,使其性能更强。
结构化剪枝
结构化剪枝可以去除模型大量参数,从而达到压缩模型并加速推理的效果。然而,现有的结构化剪枝方法会导致模型偏离常规架构的配置。例如 CoFiPruning 方法产生的模型具有不统一的层配置,与标准的统一层配置相比,这样会产生额外的推理开销。
本文对 CoFiPruning 进行了扩展,以允许将源模型剪枝为指定的任何目标配置。例如,本文在生成2.7B 模型时使用 INCITE-Base-3B 架构作为目标结构。
此外,本文还在不同粒度的模型参数上学习一组剪枝掩码( pruning mask),掩码变量如下所示:

每个掩码变量控制是否剪枝或保留相关的子结构。例如,如果对应的 z^layer=0,则需要删除这个层。下图2说明了剪枝掩码如何控制被剪枝的结构。

剪枝之后,本文通过保留与每个子结构中的掩码变量相关的最高得分组件来最终确定剪枝后的架构,并继续使用语言建模目标对剪枝后的模型进行预训练。
动态批量加载
该研究认为对剪枝后的模型进行大量预训练是很有必要的,这样才能恢复模型性能。
受其他研究的启发,本文提出了一种更有效的算法,即动态批量加载,其可以根据模型性能简单地动态调整域比例。算法如下:

实验及结果
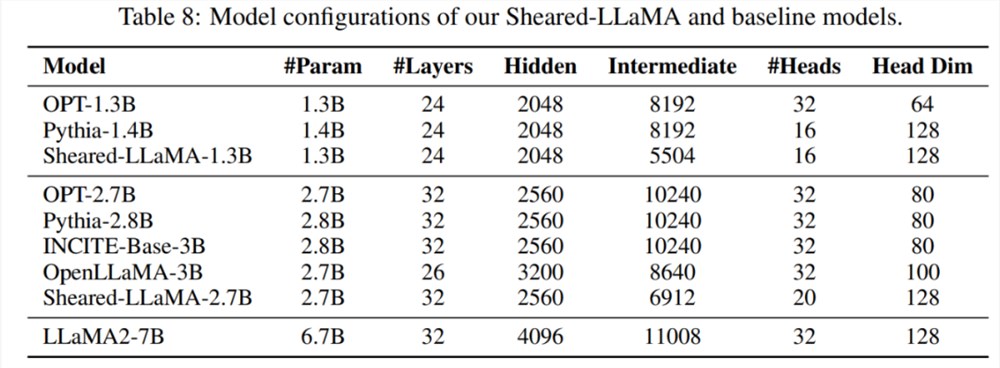
模型配置:本文将 LLaMA2-7B 模型作为源模型,然后进行结构化剪枝实验,他们将 LLaMA2-7B 压缩成两个较小的目标尺寸2.7B 和1.3B 参数,并将剪之后的模型与相同尺寸的模型进行了性能比较,包括 OPT-1.3B、Pythia-1.4B、OPT-2.7B、 Pythia-2.8B、INCITE-Base-3B、OpenLLaMA-3B-v1、OpenLLaMA-3B-v2。表8总结了所有这些模型的模型体系结构细节。
数据:由于 LLaMA2的训练数据并不是公开访问的,因此本文使用了 RedPajama 数据集 。表1提供了本文模型和基线模型使用的预训练数据。

训练:研究者在所有实验中最多使用了16个 Nvidia A100GPU (80GB)。
SHEARED-LLAMA 优于同等大小的 LM
本文表明,Sheared-LLaMA 明显优于现有的类似规模的 LLM,同时只使用一小部分计算预算来从头开始训练这些模型。
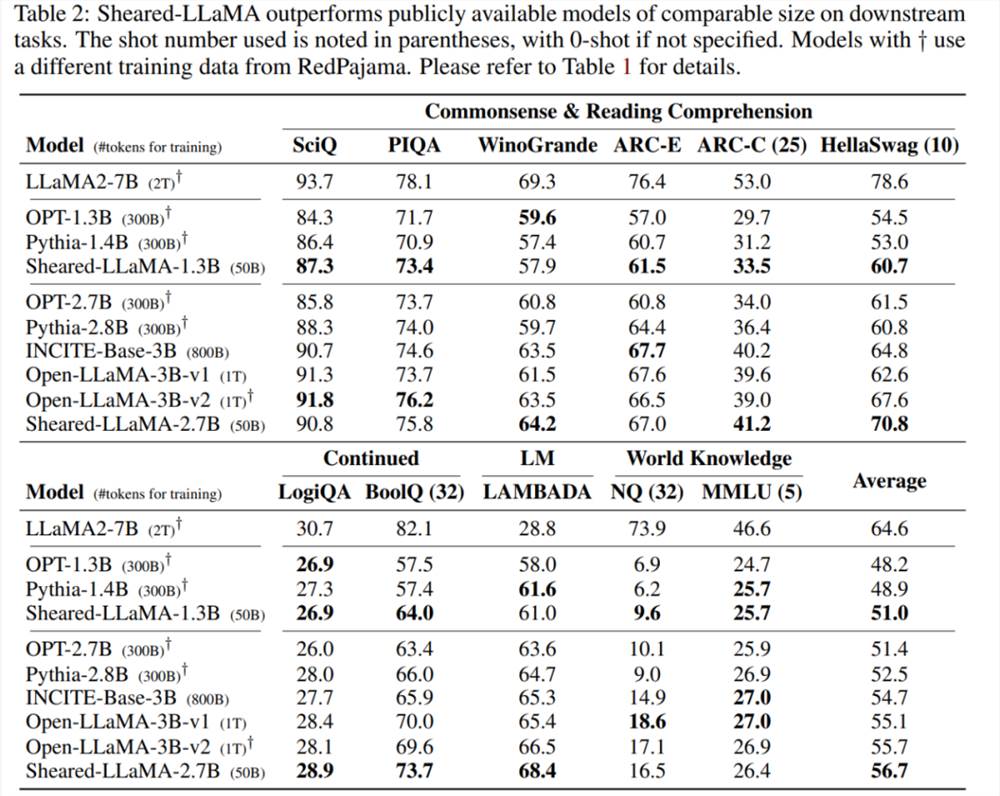
下游任务:表2展示了 Sheared-LLaMA 和类似大小的现有预训练模型的零样本和少样本在下游任务上的性能。
指令调优:如图3所示,与同等规模的所有其他预训练模型相比,指令调优的 Sheared-LLaMA 实现了更高的获胜率。

图4显示了 INCITEBase-3B 模型开始时的精度要高得多,但其性能在持续的预训练过程中趋于稳定。

分析
最后,研究者对本文方法的优势进行了分析。
动态批量加载的有效性
其中,研究者从以下三个方面的影响来分析动态批量加载的有效性:(1) 跨域的最终 LM 损失,(2) 整个训练过程中每个域的数据使用情况,(3) 下游任务性能。结果均基于 Sheared-LaMA-1.3B 算法。
跨域损失差异。动态批量加载的目的是平衡各域的损失降低率,使损失在大致相同的时间内达到参考值。图5中绘制了模型损耗(原始批量加载和动态批量加载)与参考损耗之间的差异,相比之下,动态批量加载能均匀地减少损失,各域的损失差异也非常相似,这表明数据使用效率更高。

数据使用情况。表3对比了 RedPajama 的原始数据比例和动态加载的域数据使用情况(图7展示了整个训练过程中域权重的变化)。与其他域相比,动态批量加载增加了 Book 和 C4域的权重,这表明这些域更难恢复剪枝模型。

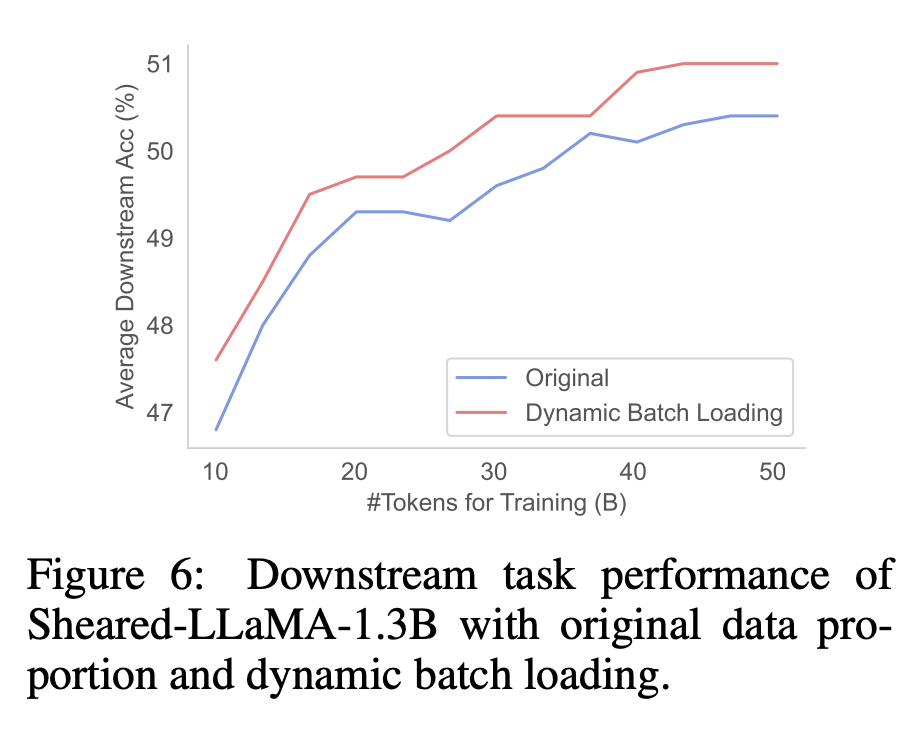
下游性能。如图6所示,与在原始 RedPajama 分布上训练的模型相比,使用动态批量加载训练的剪枝模型获得了更好的下游性能。这表明,动态批量加载所带来的更均衡的损失减少可以提高下游性能。
与其他剪枝方法的对比
此外,研究者将 LLM-shearing 方法与其他剪枝方法进行了比较,并报告了验证困惑度,它是衡量整体模型能力的一个有力指标。
由于计算上的限制,下面的实验控制了所有比较方法的总计算预算,而不是将每种方法运行到最后。
如表4所示,在相同稀疏度下,本文的目标剪枝模型的推理吞吐量比非均匀剪枝 CoFiPruning 模型更高,但困惑度略高。

其他分析
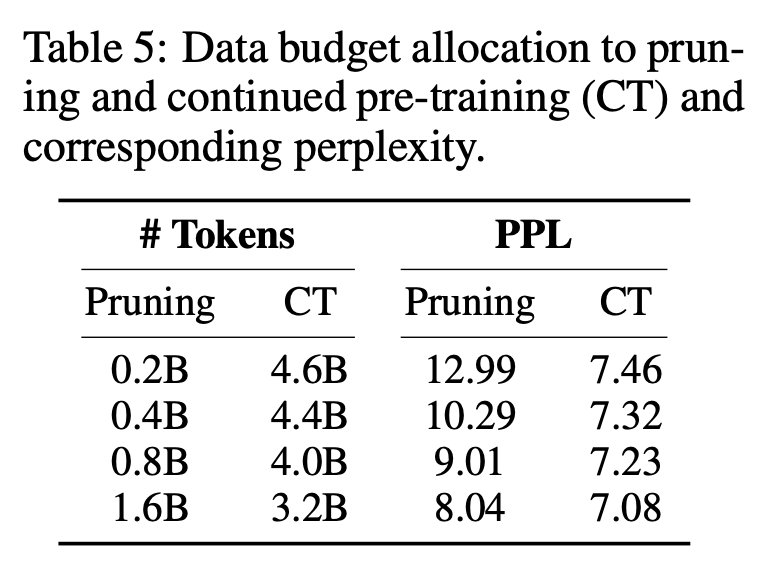
表5显示,在控制 token 总量的情况下,增加剪枝开销可以持续改善困惑度。然而,由于剪枝比持续的预训练更昂贵,研究者将0.4B 的 token 分配给剪枝。
更多研究细节,可参考原论文。
高薪主播,濒临“下岗”?
2023年,AI主播正在直播电商行业自上而下地“流行”开来。4月25日,腾讯云发布智能小样本数字人生产平台,宣称三分钟完成建模、成本降低至数千元,即利用技术进行人物外貌和声音模型的训练和搭建,从而1:1还原主播,创造一个“AI替身”。图源:腾讯云数智人生成效果站长网2023-07-26 09:59:220001猫晚再造猫晚
11月10日晚,天猫双11惊喜夜(简称“猫晚”)重磅回归,双11的快乐又回来了。这一次,天猫依然请来了半个娱乐圈的明星,前有大张伟演唱《万物盛开法则》,开篇即高潮;又有华晨宇带来《点燃银河镜头的篝火》,梦幻又神秘;最后易烊千玺用一首《羞答答的玫瑰静悄悄地开》又一次制造出晚会的心动名场面。70组艺人,直接将双11惊喜夜躁成了“春晚”。站长网2023-11-12 10:34:060001新东方文旅6天5晚售价5999元 网友吐槽:定价偏贵
快科技7月28日消息,浙江新东方文旅最近推出大美中华文化十线”,6天5晚PLUS版”售价5999元,4天3晚轻量版”售价3999元。对此,网友们纷纷评论价格太贵,富人不会去,穷人玩不起”,也有人直言俞敏洪带团就不贵”。此前,新东方官宣再创业方向:开拓面向中老年人的文旅事业。根据官方计划,自此,新东方将在教育、生活、文旅三大领域运营。0000网络风险公司警告称 ChatGPT 有可能暴露企业机密信息
据彭博消息,根据以色列网络风险公司Team8的一份报告,使用ChatGPT等生成式人工智能工具的公司可能会将客户的机密信息和商业秘密置于危险之中。该报告说,新的人工智能聊天机器人和写作工具的广泛采用可能使公司容易受到数据泄露和诉讼的影响。人们担心的是,聊天机器人可能被黑客利用,获取敏感的公司信息或对公司采取行动。还有人担心,现在输入聊天机器人的机密信息将来可能会被人工智能公司利用。站长网2023-04-19 09:21:440000Meta 全球事务总裁为开源 Llama 2 人工智能模型辩护:它们还「相当愚蠢」
Meta的全球事务总裁NickClegg为马克·扎克伯格的Meta发布的开源人工智能模型进行了辩护,他声称关于人工智能危险的炒作超过了技术的发展。站长网2023-07-20 17:17:180000












