Meta发布Llama 2-Long模型 处理长文本计算量需求减少40%
要点:
1. Meta发布Llama2-Long模型,能在处理长文本时不增加计算需求,仍保持卓越性能。
2. 模型的性能提升得益于持续预训练、位置编码改进和数据混合,而非依赖更多长文本数据。
3. 在短和长任务上,Llama2-Long都表现出色,超越其他长上下文模型,具有潜力革新自然语言处理领域。
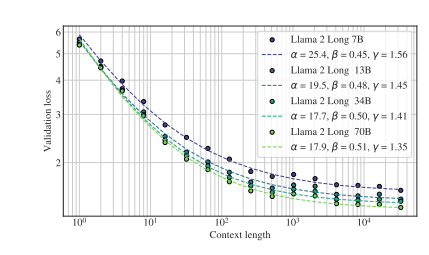
Meta最新发布的Llama2-Long模型引领着处理长文本的革命。这个模型不仅处理长文本输入,而且在不显著增加计算需求的情况下,保持了卓越性能。这一成就的背后是一系列创新策略的结果,而不仅仅依赖于更多的长文本数据。
Llama2-Long采用了持续预训练策略,允许模型逐渐适应更长的输入序列,而不是从头开始进行长序列预训练。这一策略在保持性能的同时,最多可减少40%的计算开销。通过改进位置编码,研究人员成功提高了模型的上下文长度,使其更好地捕获远处信息。
论文地址:https://arxiv.org/pdf/2309.16039.pdf
数据混合也发挥了关键作用,研究人员通过调整预训练数据的比例以及添加新的长文本数据,进一步提升了模型的长上下文能力。实验结果表明,数据质量在长上下文任务中比文本长度更为关键。
模型的指令微调方法也经过优化,通过利用大型多样化短提示数据集,有效将知识传递到长上下文场景。这种方法的简单性和效果出奇的好,特别是在长语境基准测试中。
Llama2-Long不仅在长任务中表现出色,还在短任务中有卓越性能。相对于其他长上下文模型,它在编码、数学和知识密集型任务上表现出明显的改进,甚至超越了GPT-3.5。这一成就被归因于额外的计算资源以及新引入的长数据中学到的知识。
Llama2-Long模型的发布代表了自然语言处理领域的一次里程碑,为处理长文本提供了强大的解决方案。它不仅改进了处理长文本的性能,还通过创新策略为该领域注入了新的活力。
AI前哨|AI能毁灭人类?这是不是危言耸听?
AI能毁灭人类?凤凰网科技讯《AI前哨》北京时间6月11日消息,最近一段时间,一些研究人员和行业领袖不断警告称,人工智能(AI)可能会对人类的生存构成威胁。但是,对于AI究竟如何摧毁人类,他们并未详谈。0000OpenAI: 自定义版ChatGPT“GPTs”已对所有ChatGPT+订阅者开放
今日,OpenAI首席执行官山姆·阿尔特曼(SamAltman)宣布,GPTs现已对所有ChatGPT订阅者开放。据悉,GPTs是OpenAI推出的自定义GPT。在首届OpenAI开发者大会上,OpenAI发布了GPTS。站长网2023-11-10 08:23:560003超强o1模型智商已超120!1小时写出NASA博士1年代码,最新编程赛超越99.8%选手
o1模型已经强到,能够直出博士论文代码了!来自加州大学欧文分校(UCI)的物理学博士KyleKabasares,实测o1previewmini后发现:自己肝了大约1年的博士代码,o1竟在1小时内完成了。他称,在大约6次提示后,o1便创建了一个运行版本的Python代码,描述出研究论文「方法」部分的内容。站长网2024-09-18 02:33:440000谷歌再次遭受反垄断打击,为其应用商店行为支付 7 亿美元和解金
划重点:-谷歌支付7亿美元以解决与州政府的反垄断诉讼,指控其在应用商店中非法主导市场并向消费者收取过高费用。-谷歌将允许开发者直接向用户收费,无需通过谷歌进行交易。-这次和解可能成为谷歌其他法律挑战的范本。在谷歌输给EpicGames的重大反垄断诉讼一周后,谷歌宣布解决2021年由州检察长提起的应用商店做法诉讼的条款。站长网2023-12-19 15:23:250000出抖入淘,东方甄选没有一哥的烦恼
东方甄选又有新动作了。最近,东方甄选和淘宝正式官宣,将在8月29日进行“东方盘淘会”淘宝直播首秀。当天,新东方创始人俞敏洪、东方甄选CEO孙旭东会亲自带队,和旗下众多主播一起,从上午8点播到晚上12点,总时长达到16个小时。东方甄选想要在淘宝大干一场的决心,不言自明。站长网2023-08-29 17:51:500000