用PIT框架提升大型语言模型的质量
要点:
1. 大型语言模型(LLMs)在各种复杂任务中取得了最先进的结果,但存在限制,如产生不正确的信息、推理错误或无用的内容。
2. 研究人员提出了“Implicit Self-Improvement (PIT) framework”,该框架允许LLMs从人类偏好数据中学习改进目标,无需明确的评分标准。
3. PIT框架通过利用偏好数据来训练奖励模型,成功提高了LLMs的响应质量,优于提示性方法,特别是在低温度设置下。
传统方法中,提高LLMs性能需要通过人工注释来收集更多多样化和高质量的训练数据,但这是一项资源密集型的任务,尤其是对于专业领域而言。为了解决这个问题,来自伊利诺伊大学厄巴纳-香槟分校和Google的研究人员提出了“Implicit Self-Improvement (PIT) framework”。
PIT框架的核心思想是利用人类偏好数据来训练奖励模型,而无需明确的评分标准。与传统的强化学习从人类反馈(RLHF)中最大化响应质量不同,PIT旨在最大化响应与参考响应之间的质量差距,更好地与人类偏好一致。研究人员进行了一系列实验,使用真实世界和合成数据集来评估PIT与提示性方法的性能,结果显示PIT在提高响应质量方面明显优于提示性方法。

图源备注:图片由AI生成,图片授权服务商Midjourney
与依赖提示进行自我改进的Self-Refine方法相比,PIT表现更佳。此外,研究还探讨了温度设置对自我改进方法的影响,指出在低温度下PIT能够取得更好的结果,而在高温度下Self-Refine更适用。此外,研究还研究了课程强化学习和改进迭代次数的重要性,强调在实际应用中需要谨慎考虑停止条件。
综上所述,Implicit Self-Improvement PIT框架为提高大型语言模型的性能提供了一种有前途的途径。通过从人类偏好数据中学习改进目标,PIT解决了传统提示方法的限制,并展示了在各种数据集和条件下提高LLMs响应质量的有效性。
华为汪涛:2023年华为销售收入超7000亿元 经营基本回归常态
快科技3月14日消息,今日,华为在深圳举办华为2024年合作伙伴大会”主题为因聚而生数智有为”。据媒体报道,华为常务董事、ICT基础设施业务管理委员会主任汪涛在主题演讲中表示,经过多年的艰苦努力,华为经受住了严峻的考验。2023年,华为公司经营基本回归常态,整体经营稳健,全球的销售收入超过7000亿元人民币,实现了超过9%的增长。其中华为中国区的企业业务收入取得了超过25%的快速增长。站长网2024-03-14 14:00:180002蕉下在推的“轻量化户外”,资本会买账吗?
随着天气温度逐渐上升,以防晒伞出名的蕉下已按耐不住内心的躁动,开始频繁活跃在大众视线里。只不过在第十年这一重要关口,蕉下也换了个方式打市场。3月6日,蕉下邀请歌手谭维维演唱,发布了首个品牌视频《惊蛰令》,宣布了“轻量化户外”这一新的品牌定位,同时发售了第一款轻量化全地形户外鞋“惊蛰鞋”。站长网2023-04-25 17:37:240000微软 Bing Chat 创意模式更新:显示格式改进和 Image Creator 多语言支持
这周对于微软的BingChat来说是重要的一周。微软公司周四宣布不再需要等待名单来尝试聊天机器人AI服务。它还宣布了一些即将推出的功能,包括添加聊天记录、将聊天内容分享到社交媒体等等。它还透露计划让开发人员制作第三方插件可以在BingChat中使用。站长网2023-05-06 15:07:590000DMP技术开源,可提升AI图像预测精度
要点:通过利用预训练的文本到图像扩散模型作为先验,提出了DiffusionModelsasPrior(DMP)管道,用于各种像素级语义预测任务。通过在确定性预测任务和随机文本到图像模型之间重新构建扩散过程,通过一系列插值建立输入RGB图像和输出预测分布之间的确定性映射。站长网2023-12-07 14:52:130000小鹏汽车:9月交付新车21352台,创单月交付历史新高
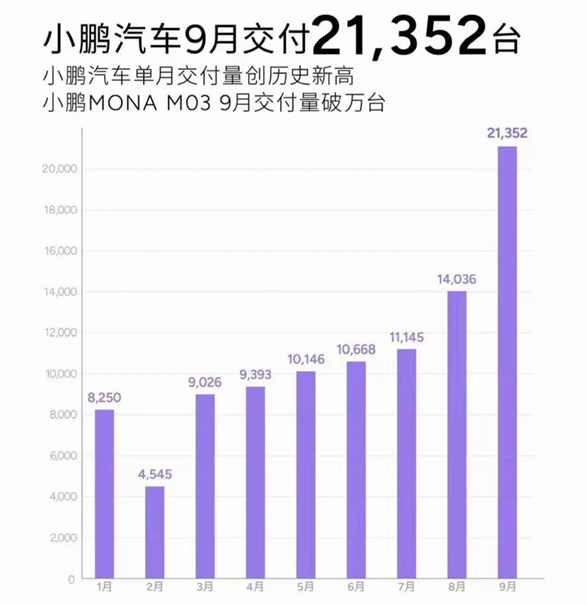
小鹏汽车公布最新交付成绩。数据显示,2024年9月,小鹏汽车共交付新车21,352台,同比增长39%,环比增长52%。新推出的纯电动轿车M03贡献巨大,交付量超过一万台,几乎占到了总销量的一半。站长网2024-10-09 03:45:030000