新微调方法LongLoRA可低成本提升LLM上下文理解能力
文章概要:
1. 长文本理解突破:MIT与香港中文大学合作研发出LongLoRA,一种优化方法,可提升大型预训练语言模型(LLM)的上下文理解能力,而无需大量计算资源。
2. 训练方法创新:研究人员采用稀疏本地关注与参数高效调优策略相结合的方法,显著降低了训练成本,同时保持性能。
3. 上下文长度的关键性:文章讨论了上下文长度对LLM性能的影响,强调了在某些情况下,上下文长度比模型参数数量更为重要。
近日,麻省理工学院(MIT)与香港中文大学联手开发了一项名为LongLoRA的新微调方法,为大型预训练语言模型(LLM)的发展提供了全新的途径。这一方法被设计用来增强LLM对上下文的理解能力,而无需过多的计算资源,为经济型超大LLM的构建铺平了道路。
LLM在自然语言处理领域发挥着巨大的作用,但通常需要巨大的计算资源来进行训练。文章指出,训练一个具有8192长度上下文的模型,相比于2048长度上下文,需要16倍的计算资源。而上下文长度实际上代表了LLM在回应给定提示时对整个上下文的清晰理解能力,这对于模型的性能至关重要。

图源备注:图片由AI生成,图片授权服务商Midjourney
LongLoRA方法的创新之处在于研究人员采用了两种关键方法来拓展LLM的上下文理解能力。首先,他们采用了稀疏本地关注,具体是“shift short attention(S2-Attn)”方法,通过这一方法在Fine-tuning过程中,高效地实现了上下文的拓展,同时保持了与标准关注机制相似的性能水平。
其次,研究人员重新审视了参数高效调优策略,发现结合可训练的嵌入和标准化方法的LoRA在上下文扩展方面非常有效。LongLoRA在多个任务中都获得了强大的实验结果,使用了LLaMA2模型,从7B/13B到70B不等。这一方法可以将模型的上下文从4k扩展到100k,适用于LLaMA27B,或者从32k扩展到LLaMA270B,而仅需要一台8× A100机器。值得注意的是,LongLoRA保持了原始模型架构,并与各种现有技术兼容。
为了提高LongLoRA方法的实用性,研究团队还创建了LongQA数据集,用于监督Fine-tuning,包括超过3,000个问题-答案对,其中包含了详细的上下文。
研究的关键发现包括对长序列语言建模的评估,研究发现,通过更长的上下文训练,模型的性能得到了提升,这显示了他们Fine-tuning方法的有效性。另外,研究还探讨了这些模型在单台机器上能够处理的最大上下文长度,发现即使在较小的上下文长度下,模型仍然表现出色。此外,研究还进行了基于检索的评估,测试了模型在寻找长对话中特定主题的任务中的表现,结果显示,这些模型在某些情况下甚至优于同类竞争模型,并且更高效地适应了开源数据。
最近的讨论中,关于LLaMA和Falcon等语言模型的性能已经开始超越了更大模型(如GPT-4或PaLM),焦点逐渐从增加模型参数数量转向了上下文令牌数量或上下文长度的考虑。文章还引用了一项研究,指出与常见误解相反,较长的输入文本并不总是导致更好的输出。实际上,在将较长的文章输入模型(例如2000字)时,模型通常只能理解前700-800字的内容,之后生成的回应可能会变得不太连贯。这一现象类似于人类记忆的工作方式,信息的开头和结尾通常比中间部分更容易被记住。
LongLoRA方法的推出为经济型超大LLM的发展提供了新的路径,通过优化上下文理解能力,降低了训练成本,有望推动自然语言处理领域的进一步发展。
专业摄影App,一个被出海开发者占据的冷门品类?
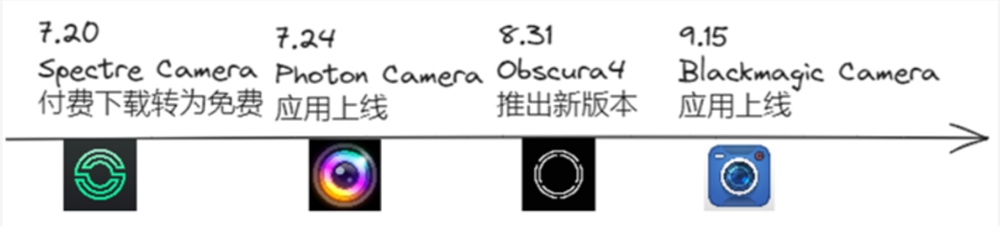
不仅如此,通过在谷歌搜索发现,近两个月内,专业相机赛道就有四条关于新品上线或已有产品进行重大更新的新闻,算挺频繁了。近期专业相机应用动向汇总|白鲸出海整理站长网2023-10-20 15:39:590003外媒:苹果明日将发布M3、M3 Pro和M3 Max三款M3芯片
10月30日消息,据外媒报道,苹果将在以“来势迅猛”为主题的特别活动上发布三款M3芯片,这三款芯片分别是M3、M3Pro和M3Max,将搭载于高端MacBookPro和24英寸iMac新品上。上周三,苹果在官网宣布,它将在太平洋时间10月30日下午5:00(北京时间10月31日上午8点)举行以“来势迅猛”为主题的特别活动。站长网2023-10-30 21:34:430000萝卜快跑招聘安全员优先录用老司机:负责数据跟踪采集、紧急情况处理
快科技8月19日消息,据媒体报道,有网友在工作招聘平台发现,萝卜快跑等多家企业正在热招自动驾驶安全员,有经验的老司机”成为自动驾驶安全员这个新职业的热门首选。0001扎克伯格预测:明年将迎来人工智能名人与粉丝互动时代
据报道,Meta首席执行官马克·扎克伯格表示,人工智能名人与粉丝互动可能在明年成为现实。在接受Verge采访时,扎克伯格表示,人们对人工智能版名人有着巨大的需求。举凯莉·詹纳(KylieJenner)为例,扎克伯格强调了粉丝们与名人互动的渴望,但也指出了品牌安全的考虑,暗示这一趋势可能会推迟到明年才成为主流。站长网2023-09-28 14:30:460000Pokémon Go的开发者Niantic在诉讼中被指控“系统性性别偏见”
据theverge报道,上周五,一位前Niantic员工对该公司提起诉讼,指控该公司贬低女性员工和有色人种女性的工作价值,并拒绝为他们提供同等的薪酬待遇。这起集体诉讼指控Niantic创立了一个“男孩俱乐部”。站长网2023-07-10 15:59:480000