OpenAI 发布 DALL-E 3 文生图模型:与 ChatGPT 完全集成 在细节和提示保真度方面挑战极限
站长之家(ChinaZ.com) 9月21日消息:本周三,OpenAI 宣布了 DALL-E 3,这是其最新版本的 AI 图像合成模型,它与 ChatGPT 完全集成。

DALL-E 3 通过紧密遵循复杂的描述并处理图像内文本生成(如标签和标志)来渲染图像,这是早期模型所面临的挑战。目前处于研究预览阶段,将于十月初提供给 ChatGPT Plus 和企业客户。
与其前身一样,DALL-E 3 是一种文本到图像生成器,根据称为提示的书面描述创建新颖的图像。尽管 OpenAI 没有透露关于 DALL-E 3 的技术细节,但以前版本的 DALL-E 的核心 AI 模型是基于由人类艺术家和摄影师创作的数百万张图像进行训练的,其中一些是从像 Shutterstock 这样的库网站获得许可的。DALL-E 3 很可能也遵循了这一相同的方法,但使用了新的训练技术和更多的计算训练时间。
从 OpenAI 在其宣传博客上提供的示例来看,DALL-E 3 似乎是迄今为止可用于按提示操作的图像合成模型中的一个巨大突破。尽管 OpenAI 的示例是精选的,以展示其效果,但它们似乎忠实地遵循了提示的指令,并以无需任何「黑科技」或提示工程即可令对象逼真地呈现出来。
与 DALL-E 2 相比,OpenAI 表示 DALL-E 3 能够更有效地细化手部等小细节,从而默认情况下创建引人入胜的图像。
相比之下,来自另一竞争对手供应商 Midjourney 渲染了逼真的细节,但仍然需要对提示进行大量反直觉的调整才能控制图像输出。
DALL-E 3 似乎还可以处理图像中的文本,而其前身无法做到这一点(一些竞争模型,如 Stable Diffusion XL 和 DeepFloyd,在这方面表现得越来越好)。例如,包含「一幅画中,一个鳄梨坐在治疗师椅子上,说着『我感到内心空虚』,中间有一个坑孔大小的洞」的提示,创建了一个卡通鳄梨,角色的台词完美地被包含在一个对话气泡中。

图片来自OpenAI
值得注意的是,OpenAI 表示 DALL-E 3 是「在 ChatGPT 上本地构建」的,并将作为 ChatGPT Plus 的一个集成功能推出,使 AI 助手能够作为头脑风暴的合作伙伴以一种与当前对话的背景相一致的上下文环境方式生成图像。这可能会带来新的能力。微软的 Bing Chat AI 助手,也是基于 OpenAI 的技术构建的,自去年三月以来就能够在对话中生成图像。
DALL-E 的原始版本于 2021 年 1 月出现,OpenAI 在 2022 年 4 月推出了更强大的续作,以令人震惊的方式引发了 AI 生成图像的新时代,深深吸引了最初的封闭测试者。DALL-E 模型使用一种称为「潜在扩散」的技术,将噪音转化为它从训练数据集中获得的知识和提示的图像。同样的技术在去年 8 月也使开放权重模型 Stable Diffusion 诞生。
由于 DALL-E 是通过从人类创作的艺术作品的大规模数据集中获取概念来学习图像的,自从去年引入主流以来,AI 图像生成技术一直备受争议。这项技术引发了艺术家的抗议,他们担心它会取代他们或不道德地复制他们的风格,引发了关于未经版权持有人同意使用作为训练数据的被抓取图像的版权侵权的诉讼,以及关于美国版权办公室和美国地方法院对版权的新裁决。
作为对这些争议的回应,OpenAI 表示,DALL-E 3 将拒绝要求以在世艺术家风格制作图像的请求。OpenAI 还提供了一个表单,供创作者选择不让他们的图像用于训练未来的模型。这些措施似乎不太可能满足那些通常认为 AI 训练应该仅限于选择加入而不包含在默认图像数据集中的艺术家。
目前,美国的版权政策规定,纯粹由 AI 生成的艺术作品无法获得版权保护,因此使用 DALL-E 3 创建的任何图像都将属于公有领域。尽管 OpenAI 没有明确承认这一点,但它表示「您使用 DALL-E 3 创建的图像属于您,您无需我们的许可即可重新印刷、销售或制作商品。」这与去年 OpenAI 根据拥有所有生成物权的许可限制 DALL-E 2 图像使用的情况有了显著变化。
关于安全性,OpenAI 表示,与 DALL-E 2 一样,DALL-E 3 已经实施了关键字和图像检测过滤器,以限制其生成暴力、性或令人讨厌的内容。该系统还被编程拒绝生成涉及具名公众人物的请求,这一点在竞争的 AI 图像生成器 Midjourney 生成唐纳德·特朗普的虚假逮捕图像时曾引发问题。
OpenAI 表示,已经与被称为「红队成员」的专家合作,以识别和减轻潜在风险,如有害的偏见或制造宣传和虚假信息。OpenAI 没有提及其工具潜在用于以具有说服力的虚构来扭曲历史记录,尽管它表示正在尝试使用「来源分类器」工具,该工具可以帮助确定图像是否由 DALL-E 3 生成。
OpenAI 表示,这款 AI 图像生成器正在进行封闭测试。计划通过 API 在十月提供给 ChatGPT Plus 和企业客户,并在今年晚些时候在实验室中提供。
IBM 首席执行官:暂停招聘可以被 AI 取代的数千个工作岗位
据彭博周一报道,IBM首席执行官ArvindKrishna在接受采访时表示将放缓或暂停招聘非面向客户的职位,例如人力资源,这些岗位未来几年可能会被AI取代。这些职位在IBM约有26000个。「其中30%的岗位很可能在五年内被AI和自动化取代,」他对彭博说。这相当于减少近8000个工作岗位。站长网2023-05-02 15:36:380000Midjourney遇劲敌!谷歌AI绘画4大牛创业,免费试玩Imagen技术,拿下1.2亿天使融资
AI绘画王座上的MidJourney,终于迎来强劲对手。最新挑战者Ideogram横空出世,开局就靠免费注册吸引众多目光。最瞩目的特性:在图中精准生成文字,英伟达科学家范麟熙直接毫不客气地用它画了一个“It’sover,Midjourney”。背后公司IdeogramAI,谷歌AI绘画4大牛集体离职的创业项目,坐标多伦多,带着1650万美元(约1.2亿人民币)种子轮融资席卷而来。站长网2023-08-26 18:43:370001微信公众平台发布2023公众号年度回顾 可了解创作历程
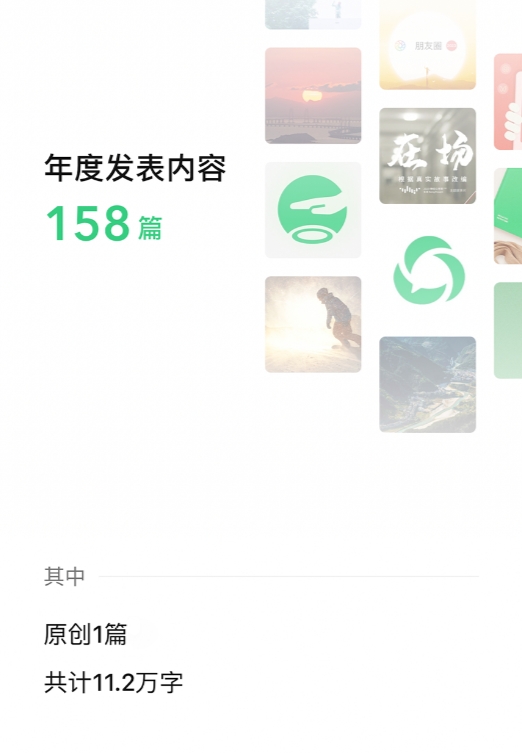
今天,微信公众平台发布了2023公众号年度回顾。每一个在2023年发过公众号的人都可以查查,了解你在公众平台的创作历程。这也是微信公众平台第一次发布年度回顾,创作者进入公众号后台通知中心就能查看。具体内容包括了:年度发表内容数、年度阅读量、获得最多推荐的一篇内容、总关注人数、互动最多的人等数据。站长网2024-01-17 18:11:360000零门槛用AI画漫画,跨模态内容创作进入next level
AI这把火,烧了一年多。现在,有AI可以帮你写PPT,有的会写歌,有的能帮公司批量生成营销素材,有的擅长“量子速读”提炼长文本。总之,几乎每个月都有AI热点出现。各种热点背后,有两个事情值得注意:站长网2024-04-24 04:09:440001“大海捞针”实验验证RAG+GPT-4 Turbo模型卓越性能 只需4%的成本
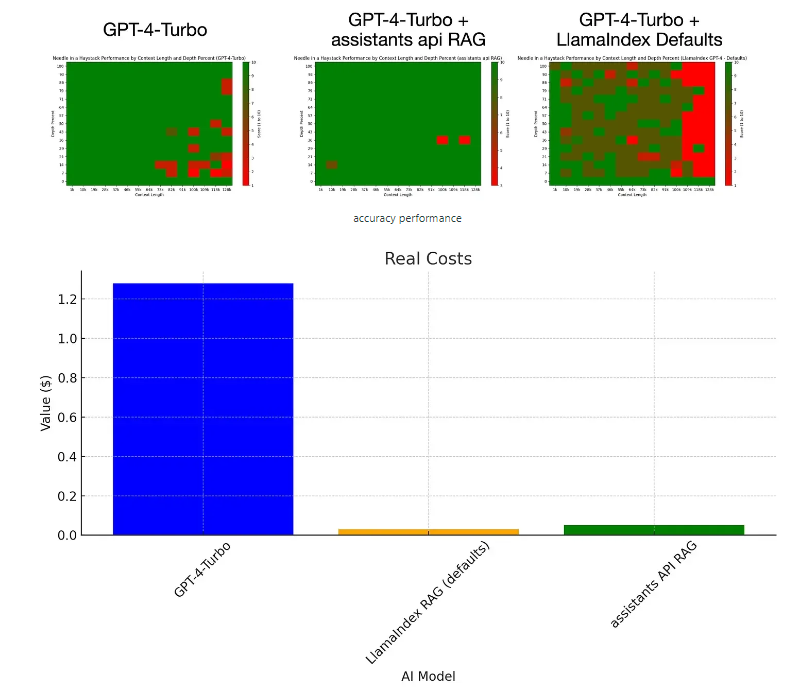
要点:1.RAGGPT-4Turbo实现了性能飙升,只需4%的成本,通过“大海捞针”实验证明其卓越效果。2.下一阶段的LLM重点在于生成超具体的响应,通过上下文窗口填充、RAG和微调等技术实现不同使用情境下的个性化响应。3.在“大海捞针”实验中,RAG模型表现出色,准确性接近完美,成本仅为GPT-4Turbo的4%,而延迟方面也有良好表现。站长网2023-12-08 14:57:150002