大模型总结摘要靠谱吗?比人类写的流畅,用GPT-4幻觉还少
以后文本摘要总结任务,可以放心交给大模型了。
文本摘要,作为自然语言生成(NLG)中的一项任务,主要用来将一大段长文本压缩为简短的摘要,例如新闻文章、源代码和跨语言文本等多种内容都能用到。
随着大模型(LLM)的出现,传统的在特定数据集上进行微调的方法已经不在适用。
我们不禁会问,LLM 在生成摘要方面效果到底如何?
为了回答这一问题,来自北京大学的研究者在论文《 Summarization is (Almost) Dead 》中进行了深入的探讨。他们使用人类生成的评估数据集评估了 LLM 在各种摘要任务(单条新闻、多条新闻、对话、源代码和跨语言摘要)上的表现。
在对 LLM 生成的摘要、人工撰写的摘要和微调模型生成的摘要进行定量和定性的比较后发现,由 LLM 生成的摘要明显受到人类评估者的青睐。
接着该研究在对过去3年发表在 ACL、EMNLP、NAACL 和 COLING 上的100篇与摘要方法相关的论文进行抽样和检查后,他们发现大约70% 的论文的主要贡献是提出了一种总结摘要方法并在标准数据集上验证了其有效性。因此,本文表示「摘要(几乎)已死( Summarization is (Almost) Dead )」。
尽管如此,研究者表示该领域仍然存在挑战,例如需要更高质量的参考数据集、改进评估方法等还需要解决。

论文地址:https://arxiv.org/pdf/2309.09558.pdf
方法及结果
该研究使用最新的数据来构建数据集,每个数据集由50个样本组成。
例如在执行单条新闻、多条新闻和对话摘要任务时,本文采用的方法模拟了 CNN/DailyMail 、Multi-News 使用的数据集构建方法。对于跨语言摘要任务,其策略与 Zhu 等人提出的方法一致。关于代码摘要任务,本文采用 Bahrami 等人提出的方法。
数据集构建完成之后,接下来就是方法了。具体来说,针对单条新闻任务本文采用 BART 和 T5;多条新闻任务采用 Pegasus 和 BART;T5和 BART 用于对话任务;跨语言任务使用 MT5和 MBART ;源代码任务使用 Codet5。
实验中,该研究聘请人类评估员来比较不同摘要的整体质量。结果如图1所示,LLM 生成的摘要在所有任务中始终优于人工生成的摘要和微调模型生成的摘要。
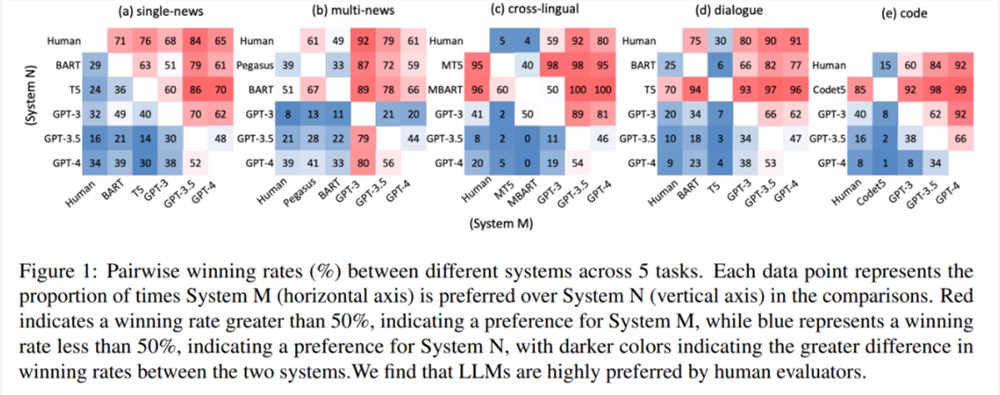
这就提出了一个问题:为什么 LLM 能够胜过人类撰写的摘要,而传统上人们认为这些摘要是完美无缺的。此外,经过初步的观察表明,LLM 生成的摘要表现出高度的流畅性和连贯性。
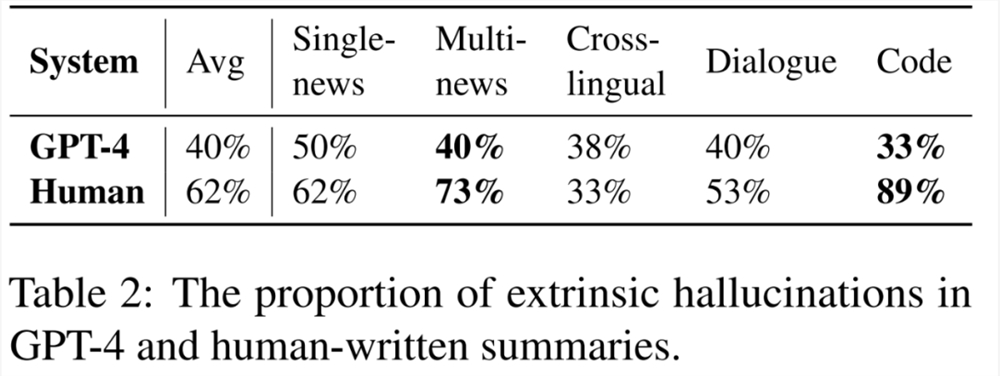
本文进一步招募注释者来识别人类和 LLM 生成摘要句子中的幻觉问题,结果如表1所示,与 GPT-4生成的摘要相比,人工书写的摘要表现出相同或更高数量的幻觉。在多条新闻和代码摘要等特定任务中,人工编写的摘要表现出明显较差的事实一致性。

人工撰写的摘要和 GPT-4生成摘要中出现幻觉的比例,如表2所示:
本文还发现人工编写的参考摘要存在这样一个问题,即缺乏流畅性。如图2(a) 所示,人工编写的参考摘要有时存在信息不完整的缺陷。并且在图2(b) 中,一些由人工编写的参考摘要会出现幻觉。

本文还发现微调模型生成的摘要往往具有固定且严格的长度,而 LLM 能够根据输入信息调整输出长度。此外,当输入包含多个主题时,微调模型生成的摘要对主题的覆盖率较低,如图3所示,而 LLM 在生成摘要时能够捕获所有主题:

由图4可得,人类对大模型的偏好分数超过50%,表明人们对其摘要有强烈的偏好,并凸显了 LLM 在文本摘要方面的能力:

正面竞争ChatGPT:俄罗斯推出GigeChat人工智能
快科技4月24日消息,在本月早些时候,俄罗斯曾宣布正在研发类GPT的生成式人工智能,并已有至少3家企业开发出了大模型的原型。今天,俄罗斯联邦储蓄银行公布GigeChat,对标ChatGPT,正式加入了这场人工智能的大战”。俄罗斯联邦储蓄银行称,GigaChat最初将处于测试模式,仅限受邀请用户参与。0001RLHF再也不需要人类了!谷歌团队研究证明,AI标注已达人类水平
【新智元导读】ChatGPT横空出世后,RLHF成为研究人员关注的焦点。谷歌最新研究提出,不用人类标注,AI标注偏好后,也能取得与RLHF一样的效果。如果说,RLHF中的「人类」被取代,可行吗?谷歌团队的最新研究提出了,用大模型替代人类,进行偏好标注,也就是AI反馈强化学习(RLAIF)。论文地址:https://arxiv.org/abs/2309.00267站长网2023-09-05 14:18:060000亿级流量扶持!七夕这个大腿,我劝你抱一下
在一切与浪漫有关的节日里,爱侣们红尘做伴,商户们赚得潇潇洒洒。“七夕”,是我们中国传统的情人节,威力甚至超过214和520,越来越多的消费者在这天以赠礼的方式来表达爱意。节日的流量向来是商家必争之地,尤其是这种消费色彩浓郁的节日,不仅有节日自带的热度,更有平台方给的资源支持。截至目前,抖音上#七夕礼物话题已经有超过159亿的播放量了。▲图片来自抖音站长网2023-07-27 14:01:250000小米汽车商城推出Are you OK手型版气门芯帽 售价29.9元
小米汽车商城近日推出了一款设计独特的气门芯帽,这款产品以小米标志性的"AreyouOK"手势为设计灵感,售价为29.9元一套,每套包含两个气门芯帽。这款气门芯帽拥有鲜艳的黄色外观,材质上采用了PVC和黄铜。小米官方强调,黄铜芯在制造过程中是直接嵌入的,保证了产品在使用过程中的稳定性,无需担心在行驶中会脱落。站长网2024-09-03 04:03:330000谷歌DeepMind被曝抄袭开源成果,论文还中了顶流会议
大模型圈再曝抄袭大瓜,这回,“被告”还是大名鼎鼎的谷歌DeepMind。“原告”直接怒喷:他们就是把我们的技术报告洗了一遍!具体是这么个事儿:谷歌DeepMind一篇中了顶流新生代会议CoLM2024的论文被挂了,瓜主直指其抄袭了一年前就挂在arXiv上的一项研究。开源的那种。两篇论文探讨的都是一种规范模型文本生成结构的方法。站长网2024-07-15 17:56:100000