智源开源中英文语义向量模型训练数据集MTP
站长网2023-09-18 09:26:030阅
近日,智源研究院发布面向中英文语义向量模型训练的大规模文本对数据集MTP(massive text pairs)。
这是全球最大的中、英文文本对训练数据集, 数据规模达3亿对,希望推动解决中文模型训练数据集缺乏问题。
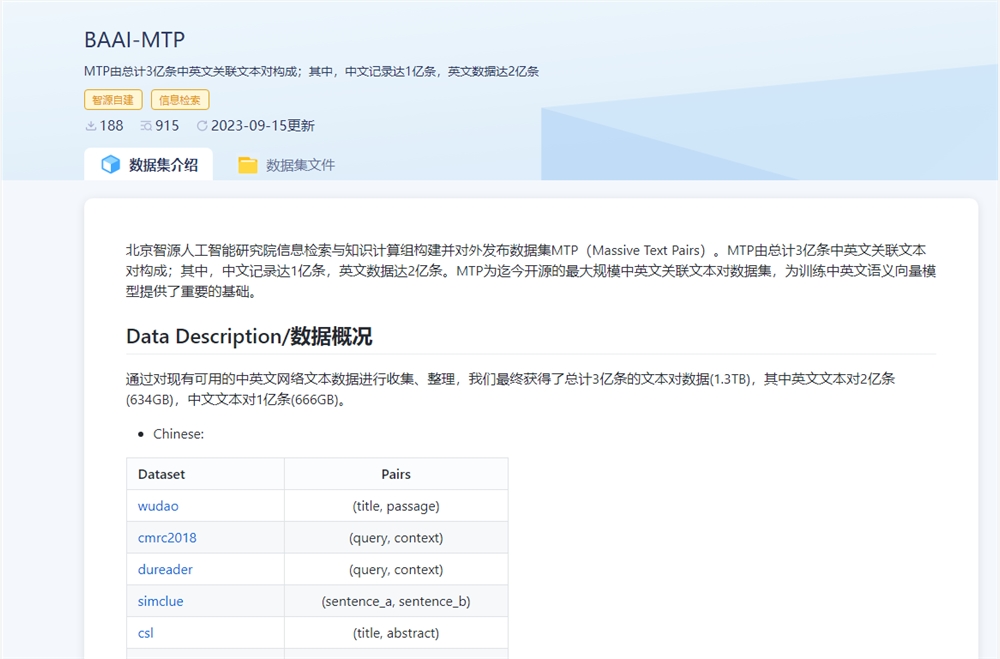
据介绍,MTP(massive text pairs)中文记录达1亿条,英文数据达2亿条。MTP 是目前为止开源的最大规模中英文关联文本对数据集,为训练中英文语义向量模型提供了重要的基础。
该数据集包含了各种不同的数据源,包括 wudao、cmrc2018、dureader、simclue、csl、amazon_reviews_multi、wiki_atomic_edits、mlqa、xlsum 以及其他一些来自互联网的数据,如社区问答、新闻和文献等。
智源研究院表示,数据对大模型训练起着至关重要的基础作用,开源亦是人工智能发展的关键推动力量。作为中国大模型开源生态圈的代表机构,智源持续进行包括数据在内的大模型全栈技术开源,推动人工智能协同创新。
MTP数据集链接:
https://data.baai.ac.cn/details/BAAI-MTP
BGE 模型链接:
https://huggingface.co/BAAI
BGE 代码仓库:
https://github.com/FlagOpen/FlagEmbedding
0000
评论列表
共(0)条相关推荐
“ChatGPT的最强竞品”爆火,就这?
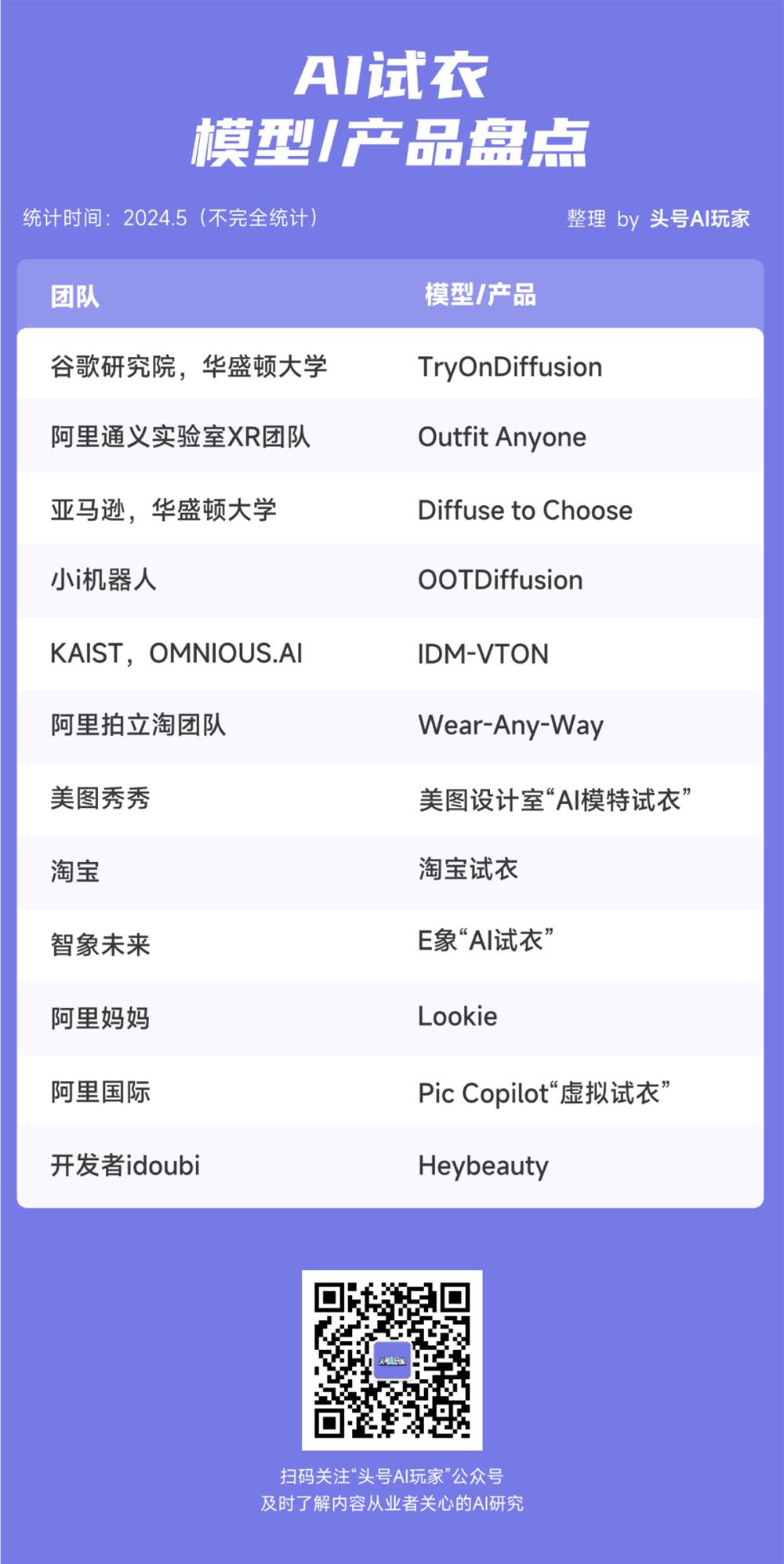
当ChatGPT大杀四方,而国内类似的AI产品还没有足够成熟的消息传来时,出现了一个全新AI助手产品——Claude(官网链接:https://www.anthropic.com/product)。站长网2023-04-24 18:04:050009真人版“奇迹暖暖”?谷歌阿里竞相布局的AI试衣有何商机?
618开始了,你可能加购了很多夏季新衣,想趁优惠激情下单,但一想到每件都要试穿,不合适的还要退货邮寄,其繁琐程度又让你望而却步。“要是有人能帮我试穿衣服就好了。”基于这样的消费心声,多款AI虚拟试衣产品相继上线。站长网2024-05-24 21:14:290000今天教师节!网易云音乐发福利:老师拿教资证免费领9个月会员
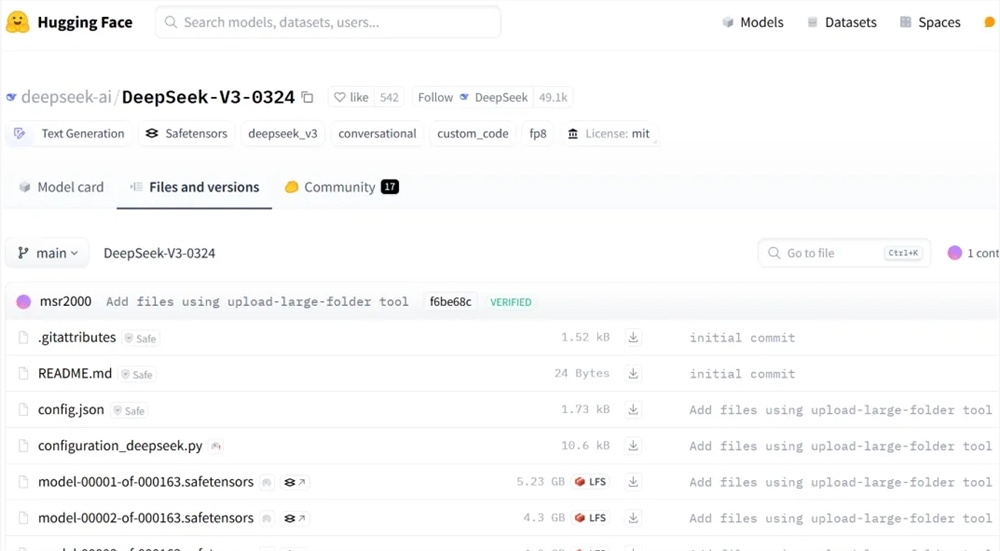
快科技9月10日消息,今天是我国第39个教师节,祝各位老师节日快乐。在教师节这天,很多厂商都会推出各种免费或优惠活动,全国教师都可参加。目前,网易云音乐已上线教师节活动,资格认证通过后,可赠送老师黑胶VIP会员和听书会员。站长网2023-09-10 08:18:370000DeepSeek-V3-0324版发布 代码生成能力大幅提升
3月24日,DeepSeek发布了其V3模型的更新版本,版本号为DeepSeek-V3-0324。这一版本的更新标志着AI编程领域迈出了重要的一步,被认为开启了AI编程的全民普惠时代。站长网2025-03-31 12:48:530000Contra Pro:专为独立开发者和设计师服务的AI作品集建站平台
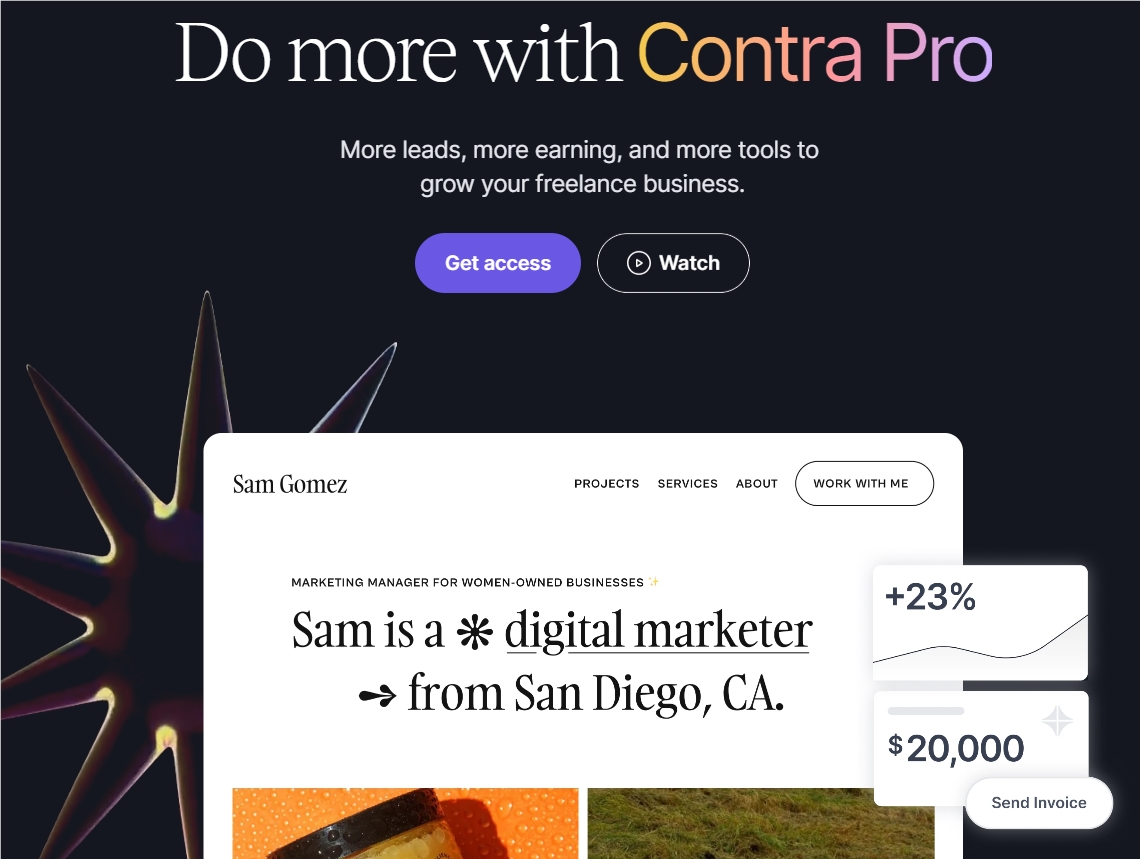
ContraPro是一款面向自由职业者的专业在线作品集平台。该平台提供了众多功能,能够全面满足自由职业者的业务需求。ContraPro具有强大的分析功能,能够实时追踪作品集浏览数据、访问量等关键指标,让自由职业者了解内容传播效果。平台还提供无限量的作品集模板和自定义域名功能,使自由职业者能够打造个性化的专属品牌。体验地址:https://contra.com/pro站长网2023-09-15 11:20:020000