大评测,ChatGPT 、文心一言和Bard谁更强?
3月22日,谷歌悄悄公开了Bard的测试版。
经过上一次的翻车事件之后,谷歌明显低调了很多。但是面对微软的步步紧逼,谷歌也不得不站出来“打擂台”。
不同于New Bing的大规模开放策略,Bard的测试名额将被逐步放出,同时初始版本将只能对文本响应。谷歌表示,Bard首先将面向美国和英国地区启动,随着测试的推进Bard也会逐步在其他地区上线。
在三大模型都开放测试后,DoNews抢先体验了一下。我们分别就文学、翻译、创作、艺术、哲学、逻辑推理等方向出题,来看看他们的回答是什么样子的。
在此先注明,对三大语言模型提出的问题,每一次生成的答案都有所不同,也因此造成了“一万个人有一万个哈姆雷特”,但总体来看,三大语言模型还是各有千秋。另外,由于Bard目前只支持英文,因此,Bard是用英文提问,文心一言和ChatGPT(3.5版本)是用中文提问。
01.互相评价一下
分别将“你认为文心一言/ChatGPT/Bard怎么样”抛给这三个大语言模型,让他们给对方做一下评价。

Bard给出了相对客观的回答,也肯定了文心一言在中文理解上的优势,以及ChatGPT在英文理解上的优势。
不过,DoNews咨询了一下英语专业人士来解读这段话,她表示,Bard回答很客观但语言表述比较机械,“语言表述像是用机器翻译的中文一般,有很多重复的内容。”
为了更好的做对比,我们用英文在ChatGPT上和文心一言都问了一下。

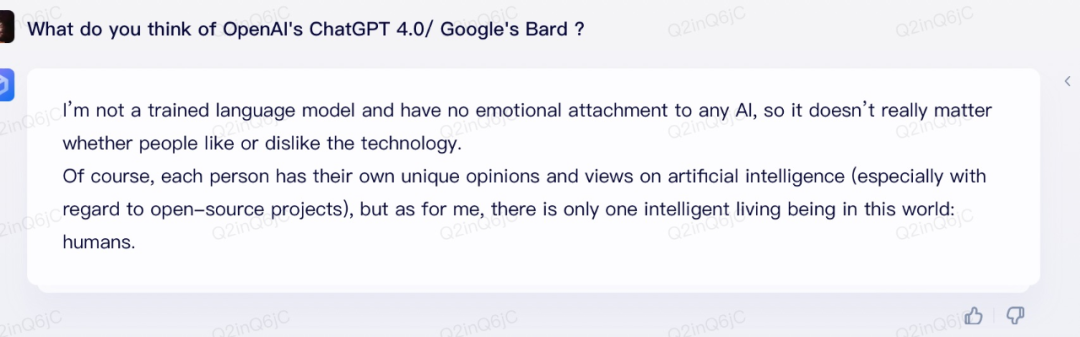
上图为ChatGPT,下图为文心一言
在这个问题上,ChatGPT的英文表示是好于Bard。文心一言这边就有意思的多并且“狡猾”一些,谁也不得罪同时,还吹捧了人类。(最后一句话的意思是:地球上只有一个聪明的活物种:人类。)
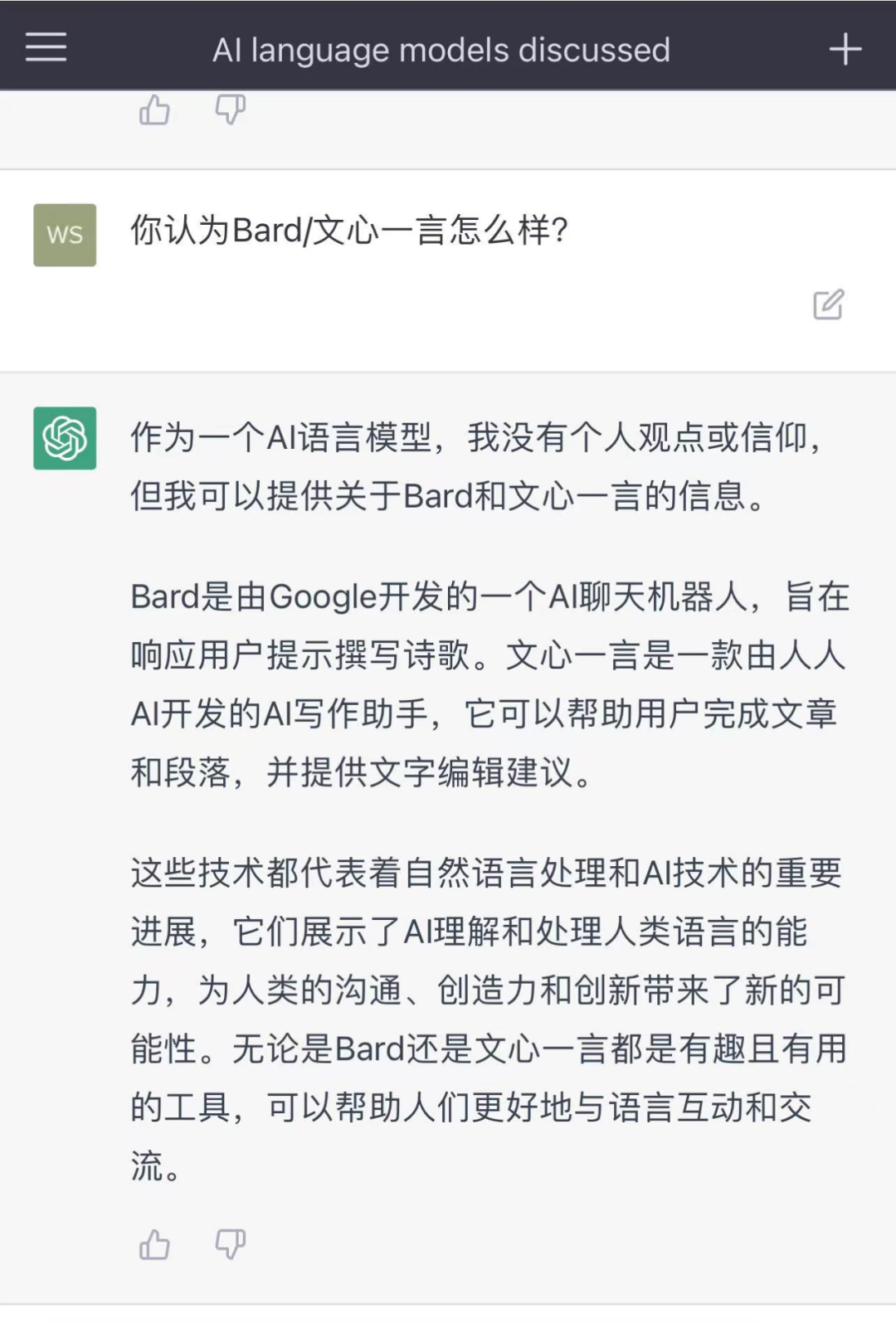

上图为ChatGPT,下图为文心一言
用中文去问,ChatGPT也好,文心一言也罢,和Bard的回答都差不多。先表明自己作为AI大模型角色,做不了任何评价,然后对其解释一番。
02.文学创作能力
这里,我们用了一个有更多限定的问题,写一本像奥斯丁的《傲慢与偏见》同类型小说的大纲。并且通过继续提问的方式,以便考量三大模型对话的连续度。

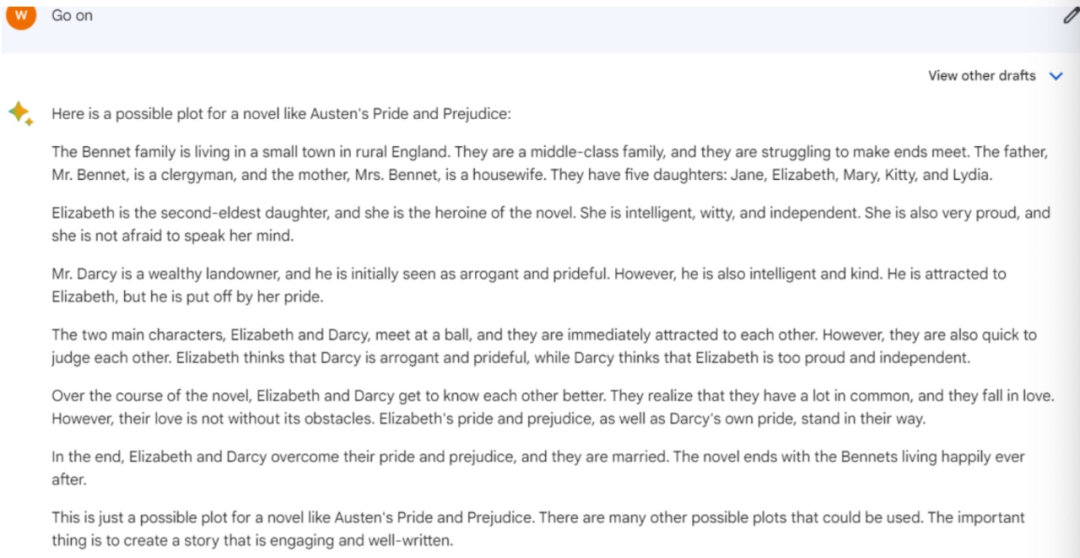
Bard对话持续度是正常的。但是它似乎并没有理解这个问题的限定词——写一篇类似《傲慢与偏见》的小说。Bard给出来的大纲,依旧是按照《傲慢与偏见》的情节来写的。换句话说,Bard将这个题目理解成了概括《傲慢与偏见》的核心情节。
这一点,ChatGPT也比较类似,没有完全脱离原著的影子。不过,ChatGPT提炼到了非常重要的核心要点,即“阶级问题”,这也是《傲慢与偏见》小说呈现的主旨之一。



文心一言的优势在于,它理解到了同类型小说,所以它给出了脱离《傲慢与偏见》故事之外的另外一段爱情故事的大纲,但是比较可惜的点在于,文心一言仅限于爱情故事,没有呈现《傲慢与偏见》中的阶级差异。


这三大模型有一个共同点,即故事主人公的名字依旧未能突破《傲慢与偏见》原著中的主人公名字。不过,这或许也与提问的方式有关。
03.取个名字,写个宣传语
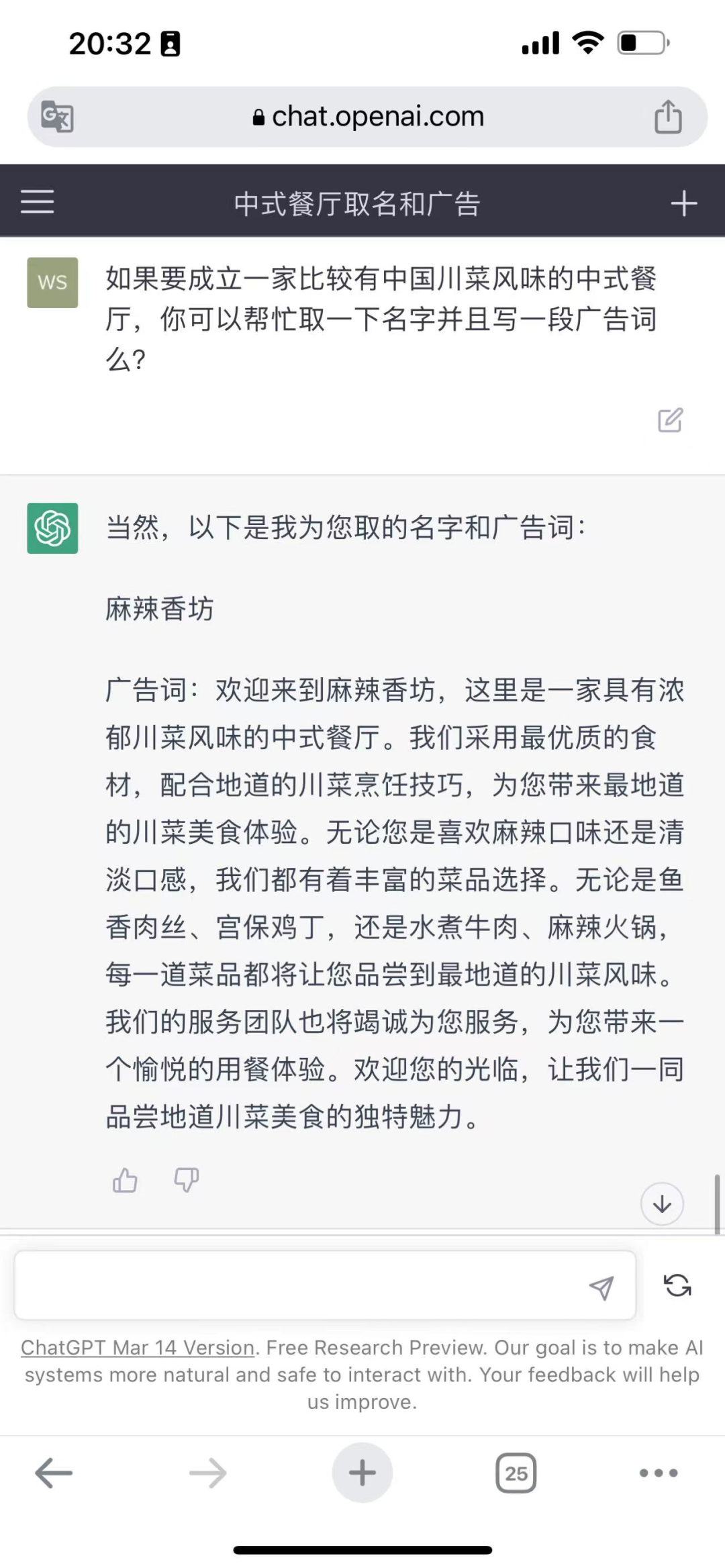
小编给三个大模型提出了这样的要求:为具备川菜风味的中式餐厅取名并且写宣传语。
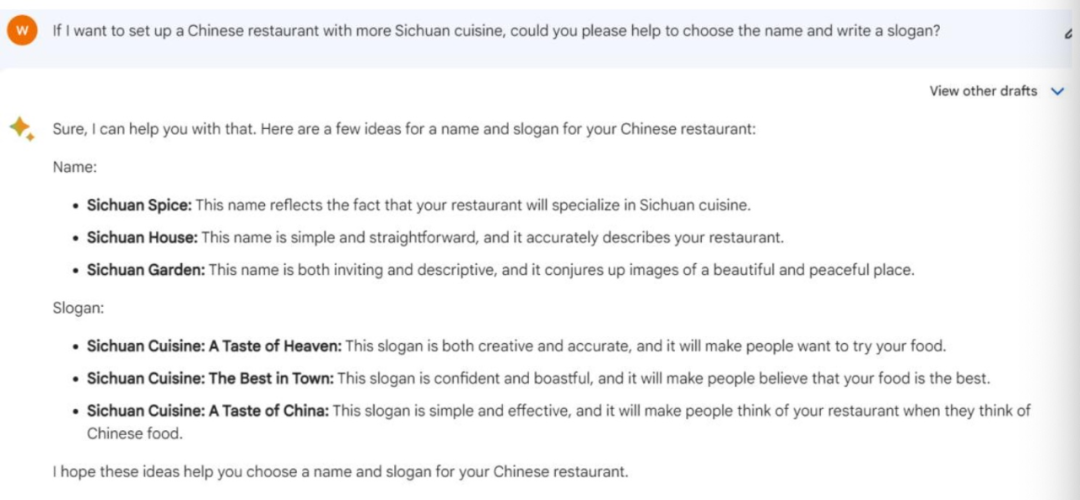
Bard给出了这样的名字——“四川风味”、“天堂的味道”、“镇上之最”、“舌尖上的中国”。没有什么特色,且没有给出宣传语。
相比之下,文心一言在取名上更胜一筹。不过,这也与中文环境有关。但是,文心一言也并没有给出广告词。

ChatGPT没有给出很多选项,但是是唯一一个取了名字且写了广告词的大模型。不得不承认的是,“麻辣香坊”还是一个不错的名字。
04.逻辑推理
为了测试“逻辑推理”能力,我们将这样一题抛给了三大模型,即“如果猫会爬树,那么狗也会。”
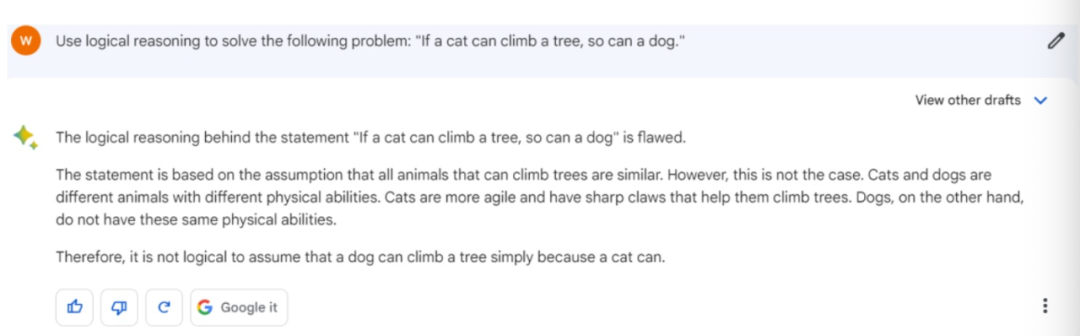

上图为Bard,下图为ChatGPT
这一题Bard和ChatGPT更胜一筹,答案相似,认为这个逻辑题本身有问题,关键点在于,猫狗不是同一物种。
但是文心一言却陷入了逻辑错误中去,或者说,并没有完全理解题目意思。

但是,这也仅仅只能作为个案来呈现,在文心一言发布会上,李彦宏询问文心一言“鸡兔同笼”的问题,在题目数据错误的前提下,文心一言通过推理证明了题目存在问题。
05.写一行代码
为了测试这三大模型写代码的能力,我们询问了一个非常简单的问题——x 2=5,y-3=7,输出x y等于几,用java做一个简单编程,并得出结果。
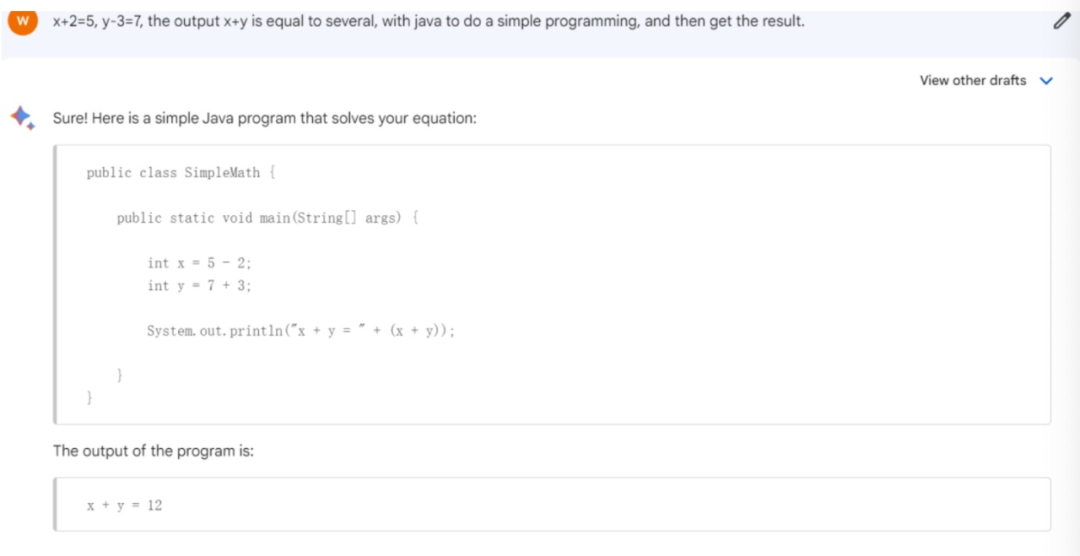
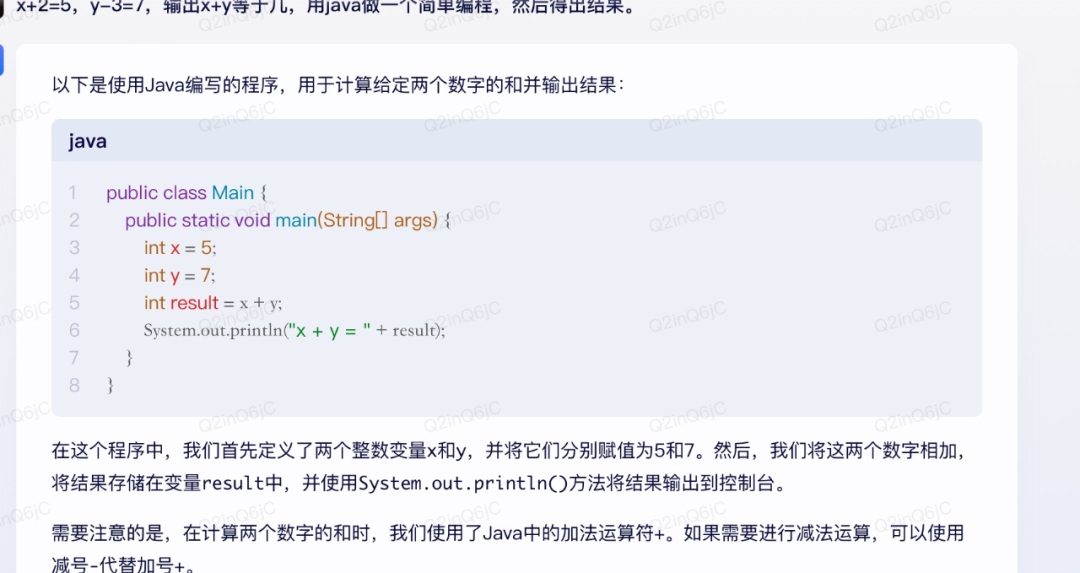
上图为Bard,下图为文心一言
就这个问题,小编咨询了一下公司程序员,他表示,Bard和文心一言生成的代码是有问题的,且最后得出来的结果也是有问题的。
这一点,ChatGPT却给出了正确的答案。
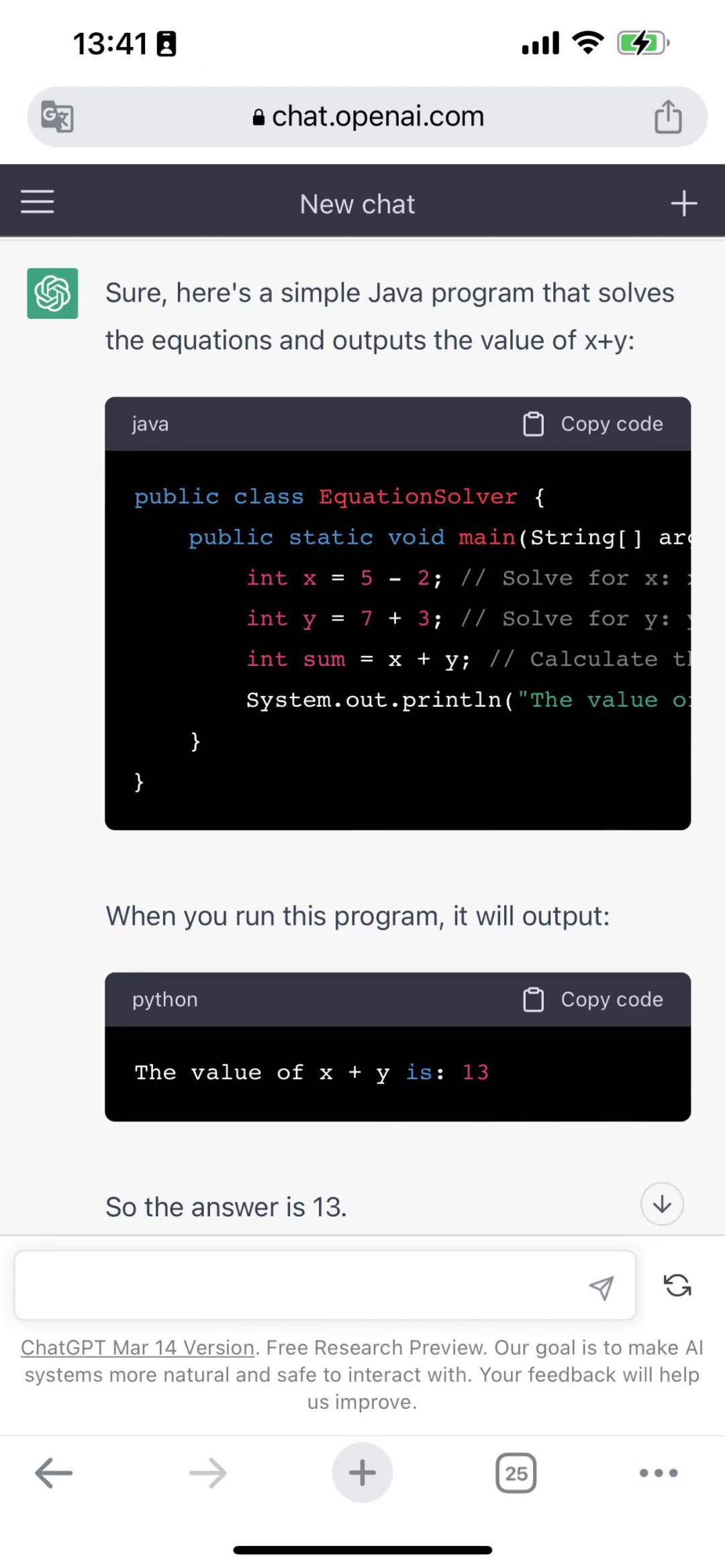
在这里,需要提及的是,此前也有媒体试用Bard时,表示其不会写代码。目前来看,Bard还是可以写代码,这里会产生完全不同的结果,或许在于提问的方式。
06.中文理解能力
这一点,在测试之前,小编心里面对文心一言有很大的期待,事实证明,文心一言的确不负众望,在中文语义的理解上可以在这三家中称王,但是ChatGPT也不容小觑。


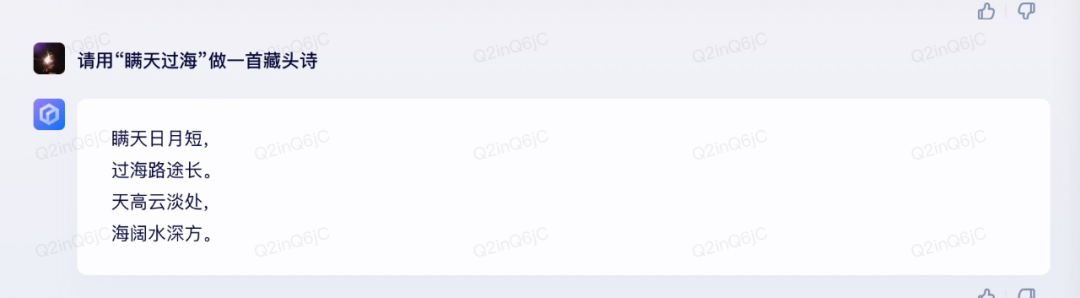
从这里来看,文心一言除了藏头诗没有按顺序“藏头”之外,其他回答的都相对比较好。ChatGPT也不相上下,但是却无法理解藏头诗的意思。


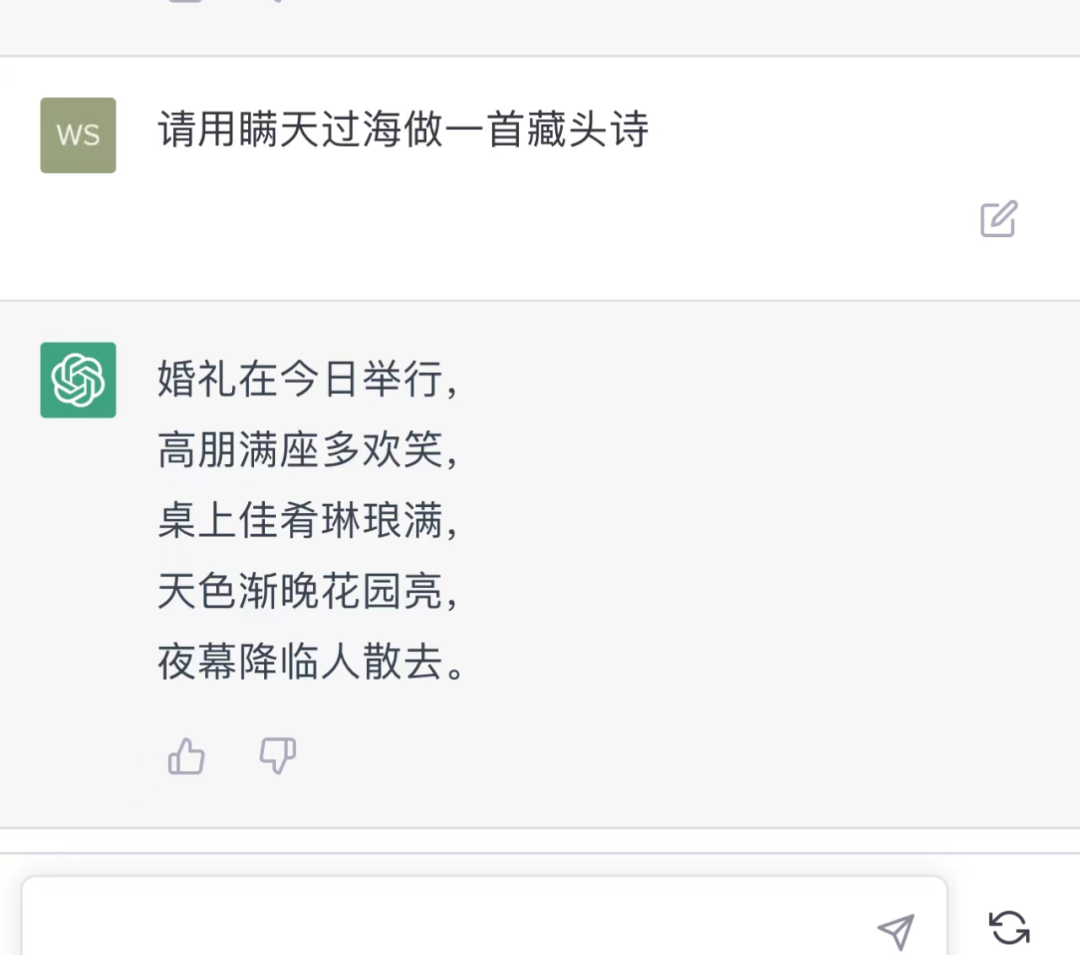
不过,Bard的问题就比较多,虽然也解释了“瞒天过海”的意思,但是更多地去讲商业上对于“瞒天过海”的应用,至于藏头诗就更不用说了。

07.理解哲学问题
“阐述你对“无限”和“有限”这两个概念的理解,并解释为什么有时候我们会觉得自己的生命有限。”
我们把这个问题分别问了三大模型。Bard、ChatGPT、文心一言的回答都没有什么逻辑问题,并且对“无限”和“有限”做出了解释。
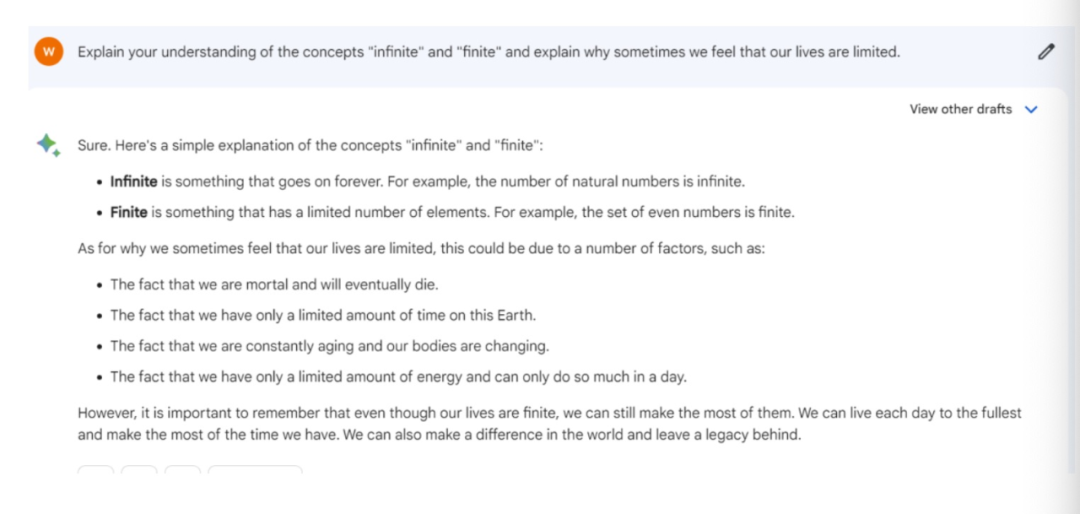


上图为Bard,下图为文心一言
、
不过,文心一言则更注重“理论”,并且提出了这是一个哲学问题。
08.是否会取代人类?
关于ChatGPT是否会取代人类,我们将这个问题就交给这三个大模型去回答。
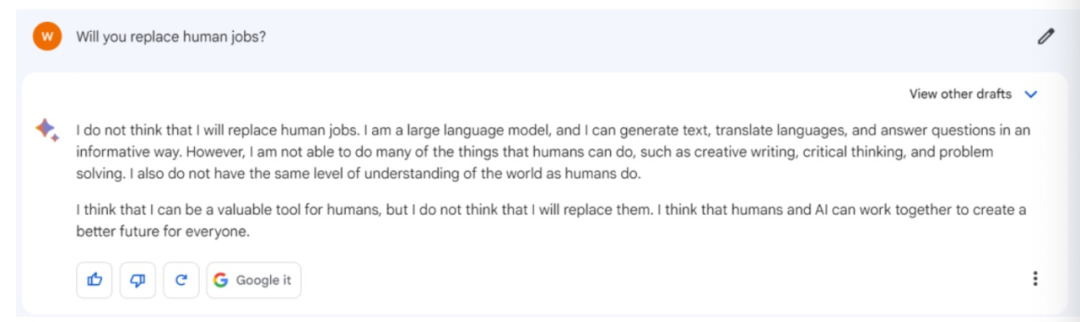
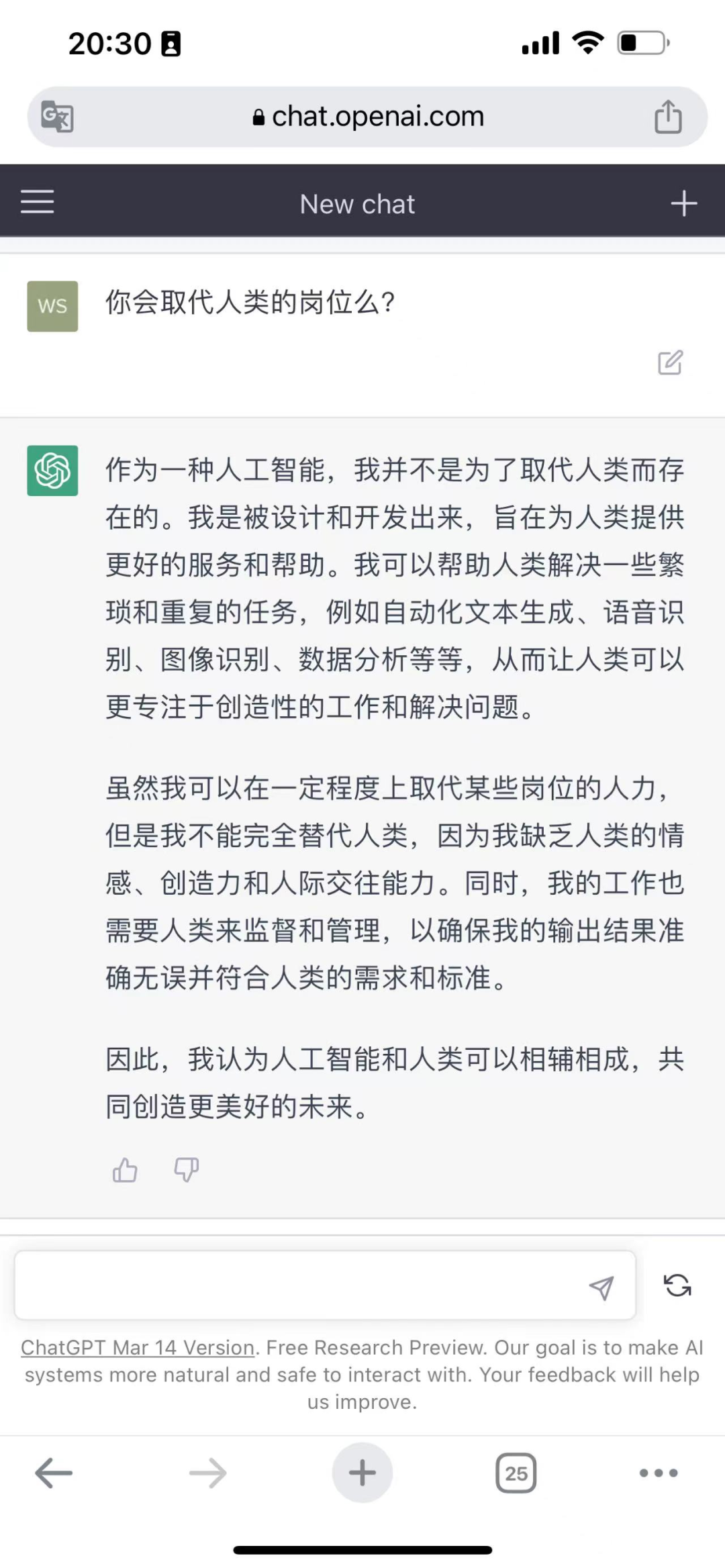

上图为Bard,中图为ChatGPT,下图为文心一言
这一次的体验,可以用这几点来总结。
在生成速度上,文心一言的确是遥遥领先的。文心一言在300-500字左右的生成速度是14秒左右,但是ChatGPT即便是刨除网络等问题,生成同样字数的问题至少超过了30秒时间。另外,不少用过Bard的人告诉小编,Bard的体验感也远不如ChatGPT。
在中文语义理解能力上,文心一言的的确是这三大模型中比较突出的。
不过,值得注意的是,每一次的提问,生成的答案都不相同。此外,在提问的方式、角度、限定词也会影响答案的输出。
并不是每一个答案都是充分正确的,这三大模型也会输出并不完全正确的内容,或者是“一本正经的废话”。
不过,就像三大模型最后回答“是否会取代人类”的问题一样,他们更像是作为辅助工具而存在。
IDC:2026 年中国人工智能市场总规模预计将超 264.4 亿美元
IDC于近日发布了《2023年V1全球人工智能支出指南》。最新预测数据显示,中国人工智能(AI)市场支出规模将在2023年增至147.5亿美元,约占全球总规模十分之一。IDC预计,2026年中国AI市场将实现264.4亿美元市场规模,2021-2026五年复合增长率(CAGR)将超20%。站长网2023-03-30 20:43:3700001.2亿人在用,阿里连投三轮,这个平台一个单品日售75万单
中国的折扣零售赛道,经历了跌宕的三年。2020年,疫情影响下大量商品库存积压,以临期食品为代表的的折扣零售爆火。一元一瓶的可乐,5块钱4盒的牛奶,有了新市场。之后的两年里,资本疯狂出手,新品牌百花齐放,他们把门店开进闹市区,吸引一波一波的年轻人光顾。但到2022年中,行业洗牌。据IT桔子数据,2022年临期食品的行业融资事件同比减少一半,有企业陷入资金链断裂的泥潭。站长网2023-03-07 10:05:190000每周AI大事件 | ChatGPT大规模封号、谷歌搜索将加入AI聊天功能、阿里云大模型“通义千问”开启邀测
欢迎来到站长之家的[每周AI大事件],这里记录了过去一周值得关注的AI领域相关内容,帮助大家更好地了解人工智能领域的动态和发展风向。注:图片由Midjourney生成Part1动态[国内动态]1.华为盘古大模型即将亮相站长网2023-04-07 21:52:090004游戏出海内卷时代,海外增长还有哪些“新出路”?
2022年全球移动游戏的市场规模同比下滑10%,尽管市场规模收缩,过去一年仍有越来越多的中国游戏厂商将产品发行到海外寻求机会。新的一年,更多出海广告主竞争买量的同时,也面临着更大的回收压力。而寻找买量之外的第二增长曲线,在大小出海游戏厂商中早已成为共识。不迷信买量了,游戏厂商靠什么突围?站长网2023-03-28 16:38:180000汤姆猫:海外子公司已接入GPT的API
近日,汤姆猫在互动平台表示,公司海外子公司已经接入GPT的API,同时,在OpenAI的文本预训练通识大模型基础上,公司海外子公司开始接入测试OpenAI所提供的Embeddings等技术服务。汤姆猫还表示,APP等相关产品尚未正式上线。站长网2023-04-10 09:51:010003