新方法揭示了如何利用一个大语言模型来越狱另一个大语言模型
新方法揭示了如何利用一个大语言模型来越狱另一个大语言模型
划重点:🔍一项由宾夕法尼亚大学的研究人员开发的新算法可以自动消除大型语言模型(LLM)中的安全漏洞。🤖这个名为PromptAutomaticIterativeRefinement(PAIR)的算法可以识别“越狱”提示,防止其生成有害内容。🌐PAIR不仅能够与ChatGPT等黑盒模型一起工作,还能够以较少尝试生成越狱提示,且这些提示具有可解释性和可传递性。站长网2023-11-08 11:35:080006


热点
SAP 和 Databricks 使客户能够统一 AI 的数据
2025-02-15 10:22:44年入千万的AI恋爱键盘,可能会让你的crush拉黑你
2025-02-17 18:20:38揭秘:苹果AI为何选阿里不选DeepSeek
2025-02-15 10:22:16一周涨粉150万,《好一个乖乖女》捧红“短剧新一哥” | 新榜对话
2025-02-17 18:09:09获英伟达买入 中国自动驾驶公司文远知行股价暴涨超100%
2025-02-15 10:22:15微软开源创新框架:可将DeepSeek,变成AI Agent
2025-02-17 18:00:41不要学编程!大佬警告别报AI专业,全美15万IT精英被裁员,CS毕业即失业
2025-02-15 10:17:59顺丰接收全球第100架波音767-300BCF:3月正式投入航线
2025-02-15 10:04:07德国媒体感慨中国科技发展太快:若只卖玩具、纺织品、手机电脑就好了
2025-02-15 10:03:40系列最强机预定!郭明錤预估iPhone SE 4今年出货近2000万台
2025-02-15 10:00:17
关注
年入千万的AI恋爱键盘,可能会让你的crush拉黑你
2025-02-17 18:20:38
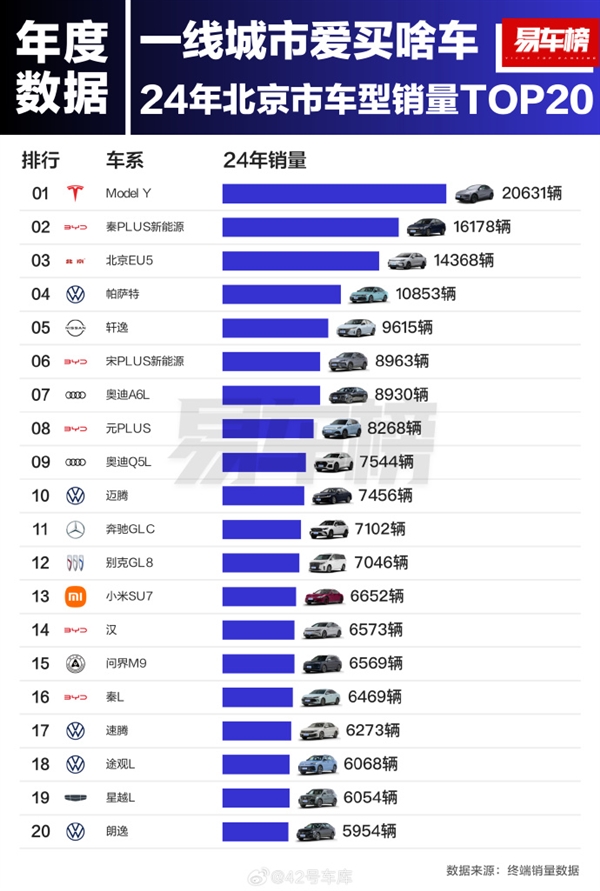
数据 | 深挖2024涨粉最多的1000个抖音账号,我们总结了3大内容趋势
2025-02-11 17:47:46
一周涨粉150万,《好一个乖乖女》捧红“短剧新一哥” | 新榜对话
2025-02-17 18:09:09全年免佣金!京东外卖启动餐饮商家招募
2025-02-11 17:41:02微软开源创新框架:可将DeepSeek,变成AI Agent
2025-02-17 18:00:41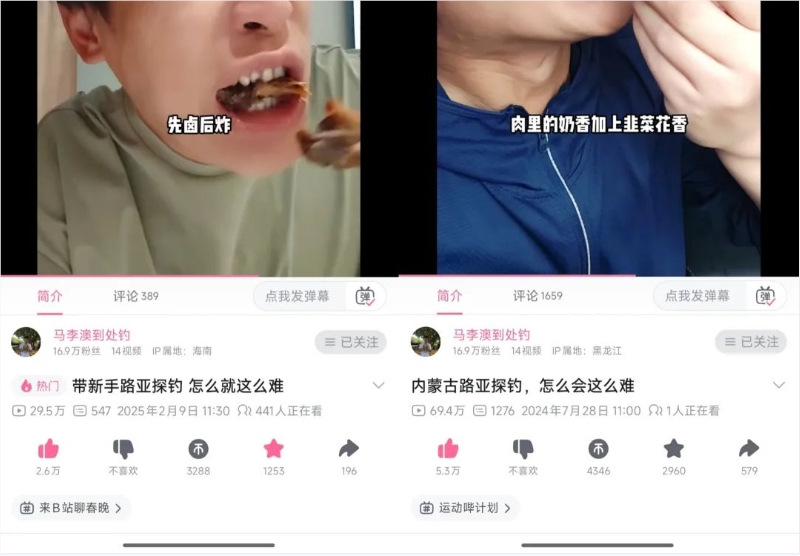
全网更新最慢钓鱼UP主@马李澳到处钓,如何靠“佛系”圈粉17万?丨金腰带
2025-02-11 17:40:32
两极反转,外国人开始在X上卖中国AI的课了?
2025-02-11 17:36:01在相亲平台给钱就有“完美爱人”?
2025-02-11 17:28:34“AI照骗”如今的信任危机,靠打水印真能解决吗
2025-02-11 12:52:57谷歌CEO:现在就是AI创新,黄金年代
2025-02-11 10:01:39